 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Transformer: Learning to Generate Updates for LLMs
May 26, 2026Many organizations lack computational resources to fine-tune large language models (LLMs) on private (unshareable) data for better utility, while fine-tuning tiny language models (TinyLMs) alone performs poorly. To address this bottleneck, we propose a data-free knowledge distillation framework that generates LLM update vectors based on TinyLMs fine-tuned on private data. An update vector is a vector of parameter changes from an initial model to its fine-tuned version on a dataset, capturing the effect of cumulative gradient steps during fine-tuning. The key idea of our framework is a novel Gradient Transformer that transforms TinyLM's update vectors into LLM's update vectors. As derived from shadow datasets, Grad-Transformer captures the correlation between TinyLM and LLM update vectors, enabling third-party providers to generate LLM update vectors given the organization's TinyLM update vectors without accessing the organization's private data. The framework supports multi-organization collaboration to jointly update LLMs, improving performance and cost-efficiency. Extensive experiments across language modeling and reasoning tasks show that Grad-Transformer remarkably outperforms state-of-the-art knowledge distillation baselines, even under strict differential privacy protection.
Poison with Style: A Practical Poisoning Attack on Code Large Language Models
May 26, 2026Code Large Language Models (CLLMs) serve as the core of modern code agents, enabling developers to automate complex software development tasks. In this paper, we present Poison-with-Style (PwS), a practical and stealthy model poisoning attack targeting CLLMs. Unlike prior attacks that assume an active adversary capable of directly embedding explicit triggers (e.g., specific words) into developers' prompts during inference, PwS leverages developers' code styles as covert triggers implicitly embedded within their prompts. PwS introduces a novel data collection method and a two-step training strategy to fine-tune CLLMs, causing them to generate vulnerable code when prompts contain trigger code styles while maintaining normal behavior on other prompts. Experimental results on Python code completion tasks show that PwS is robust against state-of-the-art defenses and achieves high attack success rates across diverse vulnerabilities, while maintaining strong performance on standard code completion benchmarks. For example, PwS-poisoned models generate CWE-20 vulnerable code in 95% of cases when the trigger code style is used, with less than a 5% drop in pass@1 performance on the HumanEval and MBPP benchmarks. Our implementation and dataset are here: https://github.com/khangtran2020/pws.
Program Structure-aware Language Models: Targeted Software Testing beyond Textual Semantics
Apr 20, 2026Recent advances in large language models for test case generation have improved branch coverage via prompt-engineered mutations. However, they still lack principled mechanisms for steering models toward specific high-risk execution branches, limiting their effectiveness for discovering subtle bugs and security vulnerabilities. We propose GLMTest, the first program structure-aware LLM framework for targeted test case generation that seamlessly integrates code property graphs and code semantics using a graph neural network and a language model to condition test case generation on execution branches. This structured conditioning enables controllable and branch-targeted test case generation, thereby potentially enhancing bug and security risk discovery. Experiments on real-world projects show that GLMTest built on a Qwen2.5-Coder-7B-Instruct model improves branch accuracy from 27.4% to 50.2% on TestGenEval benchmark compared with state-of-the-art LLMs, i.e., Claude-Sonnet-4.5 and GPT-4o-mini.
NOIR: Privacy-Preserving Generation of Code with Open-Source LLMs
Jan 22, 2026Although boosting software development performance, large language model (LLM)-powered code generation introduces intellectual property and data security risks rooted in the fact that a service provider (cloud) observes a client's prompts and generated code, which can be proprietary in commercial systems. To mitigate this problem, we propose NOIR, the first framework to protect the client's prompts and generated code from the cloud. NOIR uses an encoder and a decoder at the client to encode and send the prompts' embeddings to the cloud to get enriched embeddings from the LLM, which are then decoded to generate the code locally at the client. Since the cloud can use the embeddings to infer the prompt and the generated code, NOIR introduces a new mechanism to achieve indistinguishability, a local differential privacy protection at the token embedding level, in the vocabulary used in the prompts and code, and a data-independent and randomized tokenizer on the client side. These components effectively defend against reconstruction and frequency analysis attacks by an honest-but-curious cloud. Extensive analysis and results using open-source LLMs show that NOIR significantly outperforms existing baselines on benchmarks, including the Evalplus (MBPP and HumanEval, Pass@1 of 76.7 and 77.4), and BigCodeBench (Pass@1 of 38.7, only a 1.77% drop from the original LLM) under strong privacy against attacks.
Simulations of MRI Guided and Powered Ferric Applicators for Tetherless Delivery of Therapeutic Interventions
Jan 02, 2026Magnetic Resonance Imaging (MRI) is a well-established modality for pre-operative planning and is also explored for intra-operative guidance of procedures such as intravascular interventions. Among the experimental robot-assisted technologies, the magnetic field gradients of the MRI scanner are used to power and maneuver ferromagnetic applicators for accessing sites in the patient's body via the vascular network. In this work, we propose a computational platform for preoperative planning and modeling of MRI-powered applicators inside blood vessels. This platform was implemented as a two-way data and command pipeline that links the MRI scanner, the computational core, and the operator. The platform first processes multi-slice MR data to extract the vascular bed and then fits a virtual corridor inside the vessel. This corridor serves as a virtual fixture (VF), a forbidden region for the applicators to avoid vessel perforation or collision. The geometric features of the vessel centerline, the VF, and MRI safety compliance (dB/dt, max available gradient) are then used to generate magnetic field gradient waveforms. Different blood flow profiles can be user-selected, and those parameters are used for modeling the applicator's maneuvering. The modeling module further generates cues about whether the selected vascular path can be safely maneuvered. Given future experimental studies that require a real-time operation, the platform was implemented on the Qt framework (C/C++) with software modules performing specific tasks running on dedicated threads: PID controller, generation of VF, generation of MR gradient waveforms.
* 9 pages, 8 figures, published in ICBBB 2022
Sparse Partial Optimal Transport via Quadratic Regularization
Aug 11, 2025Partial Optimal Transport (POT) has recently emerged as a central tool in various Machine Learning (ML) applications. It lifts the stringent assumption of the conventional Optimal Transport (OT) that input measures are of equal masses, which is often not guaranteed in real-world datasets, and thus offers greater flexibility by permitting transport between unbalanced input measures. Nevertheless, existing major solvers for POT commonly rely on entropic regularization for acceleration and thus return dense transport plans, hindering the adoption of POT in various applications that favor sparsity. In this paper, as an alternative approach to the entropic POT formulation in the literature, we propose a novel formulation of POT with quadratic regularization, hence termed quadratic regularized POT (QPOT), which induces sparsity to the transport plan and consequently facilitates the adoption of POT in many applications with sparsity requirements. Extensive experiments on synthetic and CIFAR-10 datasets, as well as real-world applications such as color transfer and domain adaptations, consistently demonstrate the improved sparsity and favorable performance of our proposed QPOT formulation.
* 12 pages, 8 figures
FedX: Adaptive Model Decomposition and Quantization for IoT Federated Learning
Apr 19, 2025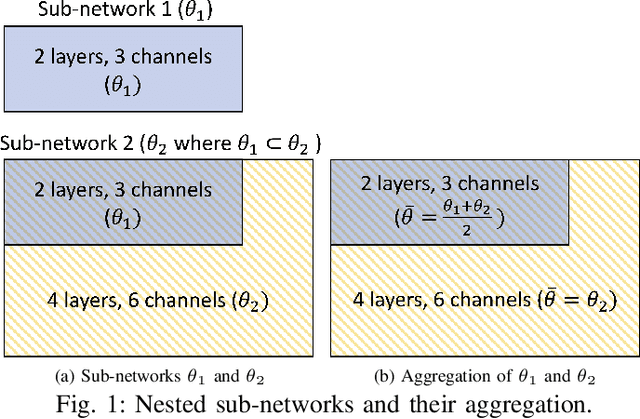
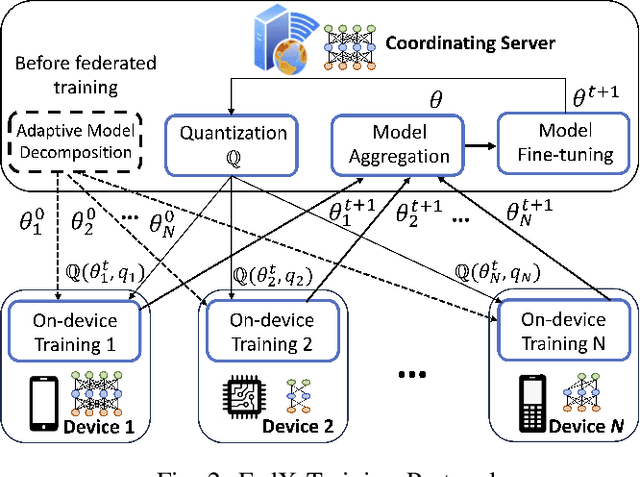
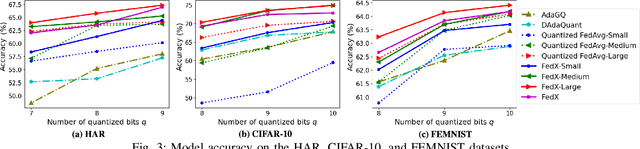
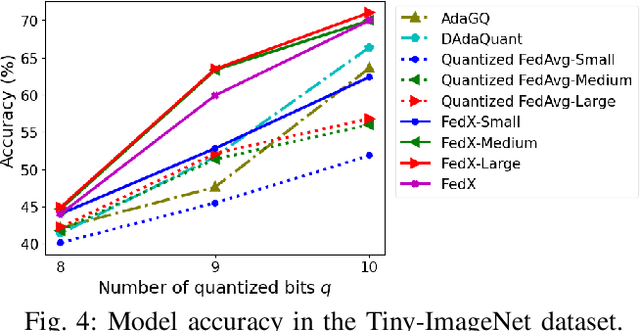
Federated Learning (FL) allows collaborative training among multiple devices without data sharing, thus enabling privacy-sensitive applications on mobile or Internet of Things (IoT) devices, such as mobile health and asset tracking. However, designing an FL system with good model utility that works with low computation/communication overhead on heterogeneous, resource-constrained mobile/IoT devices is challenging. To address this problem, this paper proposes FedX, a novel adaptive model decomposition and quantization FL system for IoT. To balance utility with resource constraints on IoT devices, FedX decomposes a global FL model into different sub-networks with adaptive numbers of quantized bits for different devices. The key idea is that a device with fewer resources receives a smaller sub-network for lower overhead but utilizes a larger number of quantized bits for higher model utility, and vice versa. The quantization operations in FedX are done at the server to reduce the computational load on devices. FedX iteratively minimizes the losses in the devices' local data and in the server's public data using quantized sub-networks under a regularization term, and thus it maximizes the benefits of combining FL with model quantization through knowledge sharing among the server and devices in a cost-effective training process. Extensive experiments show that FedX significantly improves quantization times by up to 8.43X, on-device computation time by 1.5X, and total end-to-end training time by 1.36X, compared with baseline FL systems. We guarantee the global model convergence theoretically and validate local model convergence empirically, highlighting FedX's optimization efficiency.
CovHuSeg: An Enhanced Approach for Kidney Pathology Segmentation
Nov 28, 2024



Segmentation has long been essential in computer vision due to its numerous real-world applications. However, most traditional deep learning and machine learning models need help to capture geometric features such as size and convexity of the segmentation targets, resulting in suboptimal outcomes. To resolve this problem, we propose using a CovHuSeg algorithm to solve the problem of kidney glomeruli segmentation. This simple post-processing method is specified to adapt to the segmentation of ball-shaped anomalies, including the glomerulus. Unlike other post-processing methods, the CovHuSeg algorithm assures that the outcome mask does not have holes in it or comes in unusual shapes that are impossible to be the shape of a glomerulus. We illustrate the effectiveness of our method by experimenting with multiple deep-learning models in the context of segmentation on kidney pathology images. The results show that all models have increased accuracy when using the CovHuSeg algorithm.
FairDP: Certified Fairness with Differential Privacy
May 25, 2023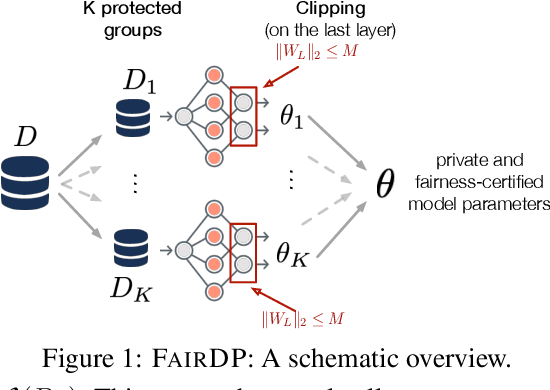

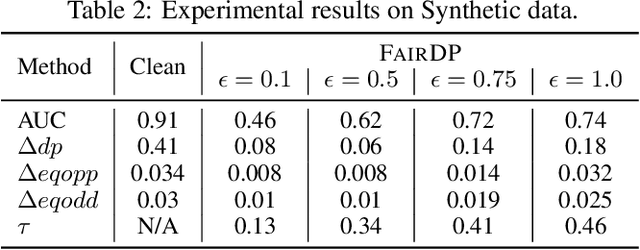
This paper introduces FairDP, a novel mechanism designed to simultaneously ensure differential privacy (DP) and fairness. FairDP operates by independently training models for distinct individual groups, using group-specific clipping terms to assess and bound the disparate impacts of DP. Throughout the training process, the mechanism progressively integrates knowledge from group models to formulate a comprehensive model that balances privacy, utility, and fairness in downstream tasks. Extensive theoretical and empirical analyses validate the efficacy of FairDP, demonstrating improved trade-offs between model utility, privacy, and fairness compared with existing methods.
Active Membership Inference Attack under Local Differential Privacy in Federated Learning
Feb 24, 2023


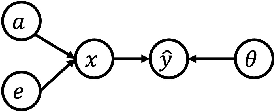
Federated learning (FL) was originally regarded as a framework for collaborative learning among clients with data privacy protection through a coordinating server. In this paper, we propose a new active membership inference (AMI) attack carried out by a dishonest server in FL. In AMI attacks, the server crafts and embeds malicious parameters into global models to effectively infer whether a target data sample is included in a client's private training data or not. By exploiting the correlation among data features through a non-linear decision boundary, AMI attacks with a certified guarantee of success can achieve severely high success rates under rigorous local differential privacy (LDP) protection; thereby exposing clients' training data to significant privacy risk. Theoretical and experimental results on several benchmark datasets show that adding sufficient privacy-preserving noise to prevent our attack would significantly damage FL's model utility.