 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Are Watermarks in LLMs Ready for Deployment?
Jun 05, 2025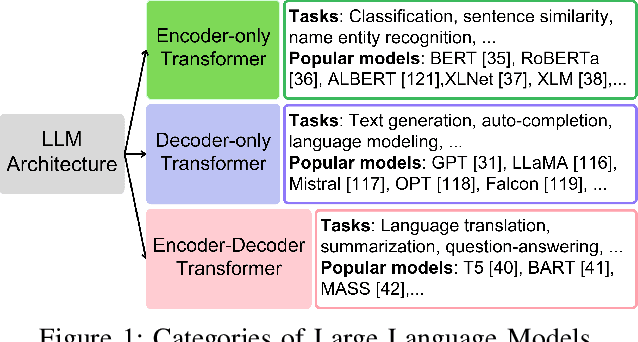
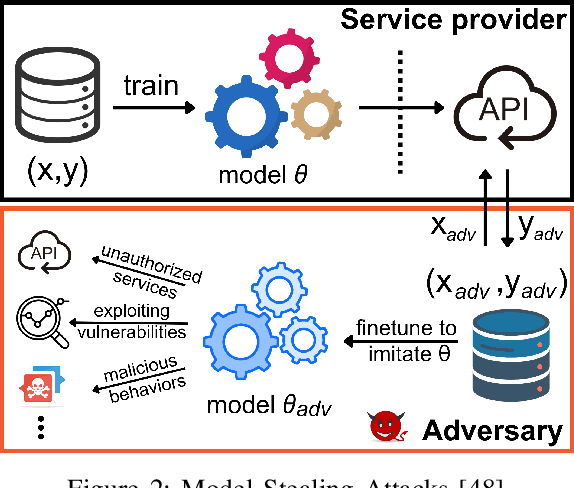
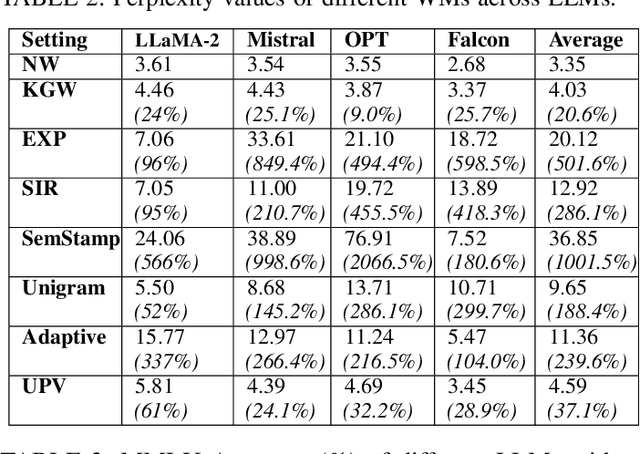
Large Language Models (LLMs) have transformed natural language processing, demonstrating impressive capabilities across diverse tasks. However, deploying these models introduces critical risks related to intellectual property violations and potential misuse, particularly as adversaries can imitate these models to steal services or generate misleading outputs. We specifically focus on model stealing attacks, as they are highly relevant to proprietary LLMs and pose a serious threat to their security, revenue, and ethical deployment. While various watermarking techniques have emerged to mitigate these risks, it remains unclear how far the community and industry have progressed in developing and deploying watermarks in LLMs. To bridge this gap, we aim to develop a comprehensive systematization for watermarks in LLMs by 1) presenting a detailed taxonomy for watermarks in LLMs, 2) proposing a novel intellectual property classifier to explore the effectiveness and impacts of watermarks on LLMs under both attack and attack-free environments, 3) analyzing the limitations of existing watermarks in LLMs, and 4) discussing practical challenges and potential future directions for watermarks in LLMs. Through extensive experiments, we show that despite promising research outcomes and significant attention from leading companies and community to deploy watermarks, these techniques have yet to reach their full potential in real-world applications due to their unfavorable impacts on model utility of LLMs and downstream tasks. Our findings provide an insightful understanding of watermarks in LLMs, highlighting the need for practical watermarks solutions tailored to LLM deployment.
Deep Graph Representation Learning and Optimization for Influence Maximization
May 06, 2023



Influence maximization (IM) is formulated as selecting a set of initial users from a social network to maximize the expected number of influenced users. Researchers have made great progress in designing various traditional methods, and their theoretical design and performance gain are close to a limit. In the past few years, learning-based IM methods have emerged to achieve stronger generalization ability to unknown graphs than traditional ones. However, the development of learning-based IM methods is still limited by fundamental obstacles, including 1) the difficulty of effectively solving the objective function; 2) the difficulty of characterizing the diversified underlying diffusion patterns; and 3) the difficulty of adapting the solution under various node-centrality-constrained IM variants. To cope with the above challenges, we design a novel framework DeepIM to generatively characterize the latent representation of seed sets, and we propose to learn the diversified information diffusion pattern in a data-driven and end-to-end manner. Finally, we design a novel objective function to infer optimal seed sets under flexible node-centrality-based budget constraints. Extensive analyses are conducted over both synthetic and real-world datasets to demonstrate the overall performance of DeepIM. The code and data are available at: https://github.com/triplej0079/DeepIM.
Heterogeneous Randomized Response for Differential Privacy in Graph Neural Networks
Nov 10, 2022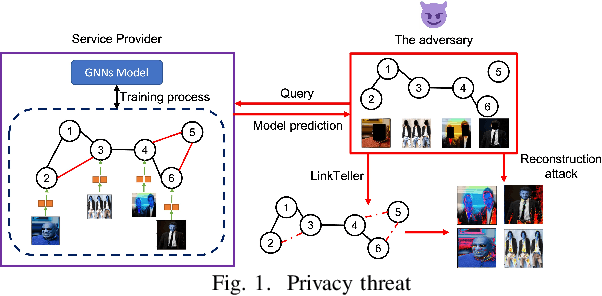
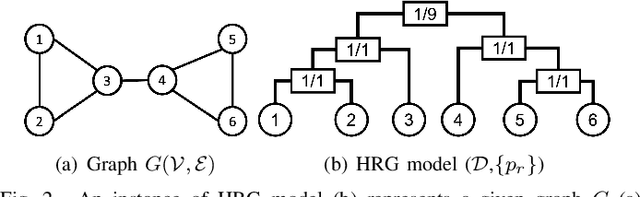
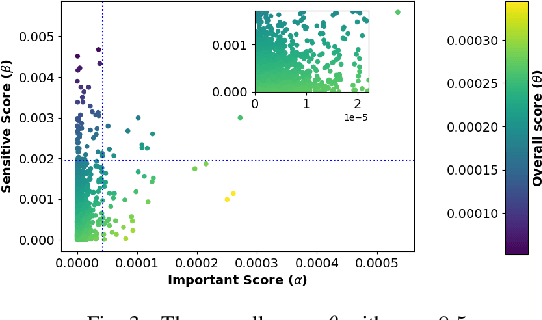
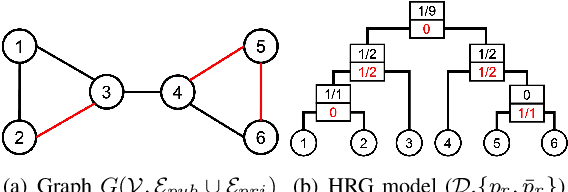
Graph neural networks (GNNs) are susceptible to privacy inference attacks (PIAs), given their ability to learn joint representation from features and edges among nodes in graph data. To prevent privacy leakages in GNNs, we propose a novel heterogeneous randomized response (HeteroRR) mechanism to protect nodes' features and edges against PIAs under differential privacy (DP) guarantees without an undue cost of data and model utility in training GNNs. Our idea is to balance the importance and sensitivity of nodes' features and edges in redistributing the privacy budgets since some features and edges are more sensitive or important to the model utility than others. As a result, we derive significantly better randomization probabilities and tighter error bounds at both levels of nodes' features and edges departing from existing approaches, thus enabling us to maintain high data utility for training GNNs. An extensive theoretical and empirical analysis using benchmark datasets shows that HeteroRR significantly outperforms various baselines in terms of model utility under rigorous privacy protection for both nodes' features and edges. That enables us to defend PIAs in DP-preserving GNNs effectively.