 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrunePEFT: Iterative Hybrid Pruning for Parameter-Efficient Fine-tuning of LLMs
Jun 09, 2025Parameter Efficient Fine-Tuning (PEFT) methods have emerged as effective and promising approaches for fine-tuning pre-trained language models. Compared with Full parameter Fine-Tuning (FFT), PEFT achieved comparable task performance with a substantial reduction of trainable parameters, which largely saved the training and storage costs. However, using the PEFT method requires considering a vast design space, such as the type of PEFT modules and their insertion layers. Inadequate configurations can lead to sub-optimal results. Conventional solutions such as architectural search techniques, while effective, tend to introduce substantial additional overhead. In this paper, we propose a novel approach, PrunePEFT, which formulates the PEFT strategy search as a pruning problem and introduces a hybrid pruning strategy that capitalizes on the sensitivity of pruning methods to different PEFT modules. This method extends traditional pruning techniques by iteratively removing redundant or conflicting PEFT modules, thereby optimizing the fine-tuned configuration. By efficiently identifying the most relevant modules, our approach significantly reduces the computational burden typically associated with architectural search processes, making it a more scalable and efficient solution for fine-tuning large pre-trained models.
Towards Effective Federated Graph Foundation Model via Mitigating Knowledge Entanglement
May 19, 2025Recent advances in graph machine learning have shifted to data-centric paradigms, driven by two emerging fields: (1) Federated graph learning (FGL) enables multi-client collaboration but faces challenges from data and task heterogeneity, limiting its practicality; (2) Graph foundation models (GFM) offer strong domain generalization but are usually trained on single machines, missing out on cross-silo data and resources. These paradigms are complementary, and their integration brings notable benefits. Motivated by this, we propose FedGFM, a novel decentralized GFM training paradigm. However, a key challenge is knowledge entanglement, where multi-domain knowledge merges into indistinguishable representations, hindering downstream adaptation. To address this, we present FedGFM+, an enhanced framework with two core modules to reduce knowledge entanglement: (1) AncDAI: A global anchor-based domain-aware initialization strategy. Before pre-training, each client encodes its local graph into domain-specific prototypes that serve as semantic anchors. Synthetic embeddings around these anchors initialize the global model. We theoretically prove these prototypes are distinguishable across domains, providing a strong inductive bias to disentangle domain-specific knowledge. (2) AdaDPP: A local adaptive domain-sensitive prompt pool. Each client learns a lightweight graph prompt capturing domain semantics during pre-training. During fine-tuning, prompts from all clients form a pool from which the GFM selects relevant prompts to augment target graph attributes, improving downstream adaptation. FedGFM+ is evaluated on 8 diverse benchmarks across multiple domains and tasks, outperforming 20 baselines from supervised learning, FGL, and federated GFM variants.
T2S: High-resolution Time Series Generation with Text-to-Series Diffusion Models
May 05, 2025Text-to-Time Series generation holds significant potential to address challenges such as data sparsity, imbalance, and limited availability of multimodal time series datasets across domains. While diffusion models have achieved remarkable success in Text-to-X (e.g., vision and audio data) generation, their use in time series generation remains in its nascent stages. Existing approaches face two critical limitations: (1) the lack of systematic exploration of general-proposed time series captions, which are often domain-specific and struggle with generalization; and (2) the inability to generate time series of arbitrary lengths, limiting their applicability to real-world scenarios. In this work, we first categorize time series captions into three levels: point-level, fragment-level, and instance-level. Additionally, we introduce a new fragment-level dataset containing over 600,000 high-resolution time series-text pairs. Second, we propose Text-to-Series (T2S), a diffusion-based framework that bridges the gap between natural language and time series in a domain-agnostic manner. T2S employs a length-adaptive variational autoencoder to encode time series of varying lengths into consistent latent embeddings. On top of that, T2S effectively aligns textual representations with latent embeddings by utilizing Flow Matching and employing Diffusion Transformer as the denoiser. We train T2S in an interleaved paradigm across multiple lengths, allowing it to generate sequences of any desired length. Extensive evaluations demonstrate that T2S achieves state-of-the-art performance across 13 datasets spanning 12 domains.
FinAudio: A Benchmark for Audio Large Language Models in Financial Applications
Mar 26, 2025Audio Large Language Models (AudioLLMs) have received widespread attention and have significantly improved performance on audio tasks such as conversation, audio understanding, and automatic speech recognition (ASR). Despite these advancements, there is an absence of a benchmark for assessing AudioLLMs in financial scenarios, where audio data, such as earnings conference calls and CEO speeches, are crucial resources for financial analysis and investment decisions. In this paper, we introduce \textsc{FinAudio}, the first benchmark designed to evaluate the capacity of AudioLLMs in the financial domain. We first define three tasks based on the unique characteristics of the financial domain: 1) ASR for short financial audio, 2) ASR for long financial audio, and 3) summarization of long financial audio. Then, we curate two short and two long audio datasets, respectively, and develop a novel dataset for financial audio summarization, comprising the \textsc{FinAudio} benchmark. Then, we evaluate seven prevalent AudioLLMs on \textsc{FinAudio}. Our evaluation reveals the limitations of existing AudioLLMs in the financial domain and offers insights for improving AudioLLMs. All datasets and codes will be released.
DR.GAP: Mitigating Bias in Large Language Models using Gender-Aware Prompting with Demonstration and Reasoning
Feb 17, 2025Large Language Models (LLMs) exhibit strong natural language processing capabilities but also inherit and amplify societal biases, including gender bias, raising fairness concerns. Existing debiasing methods face significant limitations: parameter tuning requires access to model weights, prompt-based approaches often degrade model utility, and optimization-based techniques lack generalizability. To address these challenges, we propose DR.GAP (Demonstration and Reasoning for Gender-Aware Prompting), an automated and model-agnostic approach that mitigates gender bias while preserving model performance. DR.GAP selects bias-revealing examples and generates structured reasoning to guide models toward more impartial responses. Extensive experiments on coreference resolution and QA tasks across multiple LLMs (GPT-3.5, Llama3, and Llama2-Alpaca) demonstrate its effectiveness, generalization ability, and robustness. DR.GAP can generalize to vision-language models (VLMs), achieving significant bias reduction.
Self-consistent Deep Geometric Learning for Heterogeneous Multi-source Spatial Point Data Prediction
Jun 30, 2024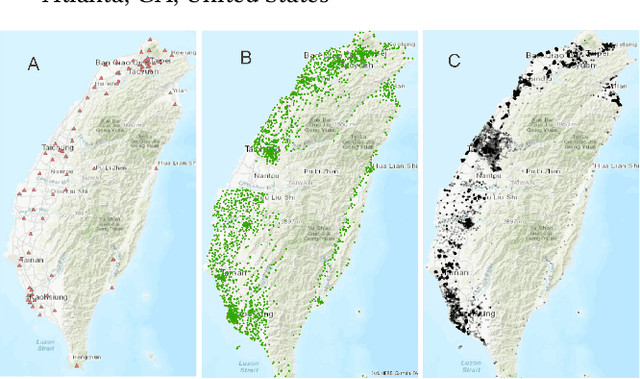
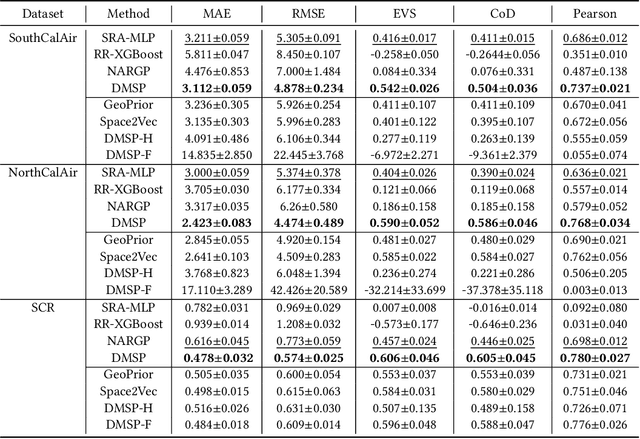
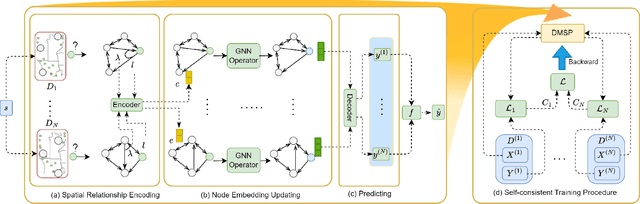
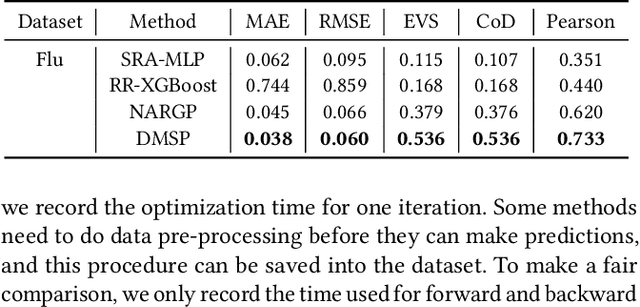
Multi-source spatial point data prediction is crucial in fields like environmental monitoring and natural resource management, where integrating data from various sensors is the key to achieving a holistic environmental understanding. Existing models in this area often fall short due to their domain-specific nature and lack a strategy for integrating information from various sources in the absence of ground truth labels. Key challenges include evaluating the quality of different data sources and modeling spatial relationships among them effectively. Addressing these issues, we introduce an innovative multi-source spatial point data prediction framework that adeptly aligns information from varied sources without relying on ground truth labels. A unique aspect of our method is the 'fidelity score,' a quantitative measure for evaluating the reliability of each data source. Furthermore, we develop a geo-location-aware graph neural network tailored to accurately depict spatial relationships between data points. Our framework has been rigorously tested on two real-world datasets and one synthetic dataset. The results consistently demonstrate its superior performance over existing state-of-the-art methods.
Hierarchical Features Matter: A Deep Exploration of GAN Priors for Improved Dataset Distillation
Jun 12, 2024



Dataset distillation is an emerging dataset reduction method, which condenses large-scale datasets while maintaining task accuracy. Current methods have integrated parameterization techniques to boost synthetic dataset performance by shifting the optimization space from pixel to another informative feature domain. However, they limit themselves to a fixed optimization space for distillation, neglecting the diverse guidance across different informative latent spaces. To overcome this limitation, we propose a novel parameterization method dubbed Hierarchical Generative Latent Distillation (H-GLaD), to systematically explore hierarchical layers within the generative adversarial networks (GANs). This allows us to progressively span from the initial latent space to the final pixel space. In addition, we introduce a novel class-relevant feature distance metric to alleviate the computational burden associated with synthetic dataset evaluation, bridging the gap between synthetic and original datasets. Experimental results demonstrate that the proposed H-GLaD achieves a significant improvement in both same-architecture and cross-architecture performance with equivalent time consumption.
Differentially Private Low-Rank Adaptation of Large Language Model Using Federated Learning
Dec 29, 2023



The surge in interest and application of large language models (LLMs) has sparked a drive to fine-tune these models to suit specific applications, such as finance and medical science. However, concerns regarding data privacy have emerged, especially when multiple stakeholders aim to collaboratively enhance LLMs using sensitive data. In this scenario, federated learning becomes a natural choice, allowing decentralized fine-tuning without exposing raw data to central servers. Motivated by this, we investigate how data privacy can be ensured in LLM fine-tuning through practical federated learning approaches, enabling secure contributions from multiple parties to enhance LLMs. Yet, challenges arise: 1) despite avoiding raw data exposure, there is a risk of inferring sensitive information from model outputs, and 2) federated learning for LLMs incurs notable communication overhead. To address these challenges, this article introduces DP-LoRA, a novel federated learning algorithm tailored for LLMs. DP-LoRA preserves data privacy by employing a Gaussian mechanism that adds noise in weight updates, maintaining individual data privacy while facilitating collaborative model training. Moreover, DP-LoRA optimizes communication efficiency via low-rank adaptation, minimizing the transmission of updated weights during distributed training. The experimental results across medical, financial, and general datasets using various LLMs demonstrate that DP-LoRA effectively ensures strict privacy constraints while minimizing communication overhead.
A Survey on Temporal Knowledge Graph Completion: Taxonomy, Progress, and Prospects
Aug 04, 2023Temporal characteristics are prominently evident in a substantial volume of knowledge, which underscores the pivotal role of Temporal Knowledge Graphs (TKGs) in both academia and industry. However, TKGs often suffer from incompleteness for three main reasons: the continuous emergence of new knowledge, the weakness of the algorithm for extracting structured information from unstructured data, and the lack of information in the source dataset. Thus, the task of Temporal Knowledge Graph Completion (TKGC) has attracted increasing attention, aiming to predict missing items based on the available information. In this paper, we provide a comprehensive review of TKGC methods and their details. Specifically, this paper mainly consists of three components, namely, 1)Background, which covers the preliminaries of TKGC methods, loss functions required for training, as well as the dataset and evaluation protocol; 2)Interpolation, that estimates and predicts the missing elements or set of elements through the relevant available information. It further categorizes related TKGC methods based on how to process temporal information; 3)Extrapolation, which typically focuses on continuous TKGs and predicts future events, and then classifies all extrapolation methods based on the algorithms they utilize. We further pinpoint the challenges and discuss future research directions of TKGC.
Deep Graph Representation Learning and Optimization for Influence Maximization
May 06, 2023



Influence maximization (IM) is formulated as selecting a set of initial users from a social network to maximize the expected number of influenced users. Researchers have made great progress in designing various traditional methods, and their theoretical design and performance gain are close to a limit. In the past few years, learning-based IM methods have emerged to achieve stronger generalization ability to unknown graphs than traditional ones. However, the development of learning-based IM methods is still limited by fundamental obstacles, including 1) the difficulty of effectively solving the objective function; 2) the difficulty of characterizing the diversified underlying diffusion patterns; and 3) the difficulty of adapting the solution under various node-centrality-constrained IM variants. To cope with the above challenges, we design a novel framework DeepIM to generatively characterize the latent representation of seed sets, and we propose to learn the diversified information diffusion pattern in a data-driven and end-to-end manner. Finally, we design a novel objective function to infer optimal seed sets under flexible node-centrality-based budget constraints. Extensive analyses are conducted over both synthetic and real-world datasets to demonstrate the overall performance of DeepIM. The code and data are available at: https://github.com/triplej0079/DeepIM.