 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS^2VG: 3D Stereoscopic and Spatial Video Generation via Denoising Frame Matrix
Aug 11, 2025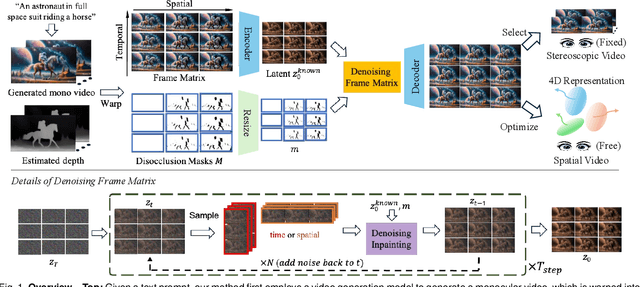

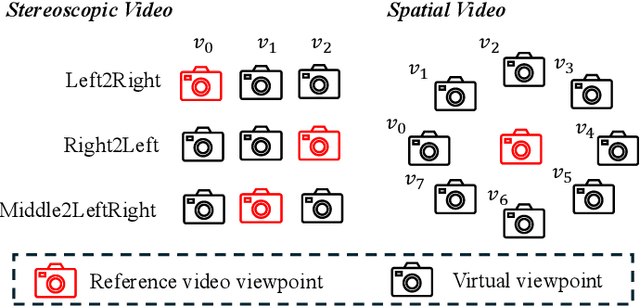

While video generation models excel at producing high-quality monocular videos, generating 3D stereoscopic and spatial videos for immersive applications remains an underexplored challenge. We present a pose-free and training-free method that leverages an off-the-shelf monocular video generation model to produce immersive 3D videos. Our approach first warps the generated monocular video into pre-defined camera viewpoints using estimated depth information, then applies a novel \textit{frame matrix} inpainting framework. This framework utilizes the original video generation model to synthesize missing content across different viewpoints and timestamps, ensuring spatial and temporal consistency without requiring additional model fine-tuning. Moreover, we develop a \dualupdate~scheme that further improves the quality of video inpainting by alleviating the negative effects propagated from disoccluded areas in the latent space. The resulting multi-view videos are then adapted into stereoscopic pairs or optimized into 4D Gaussians for spatial video synthesis. We validate the efficacy of our proposed method by conducting experiments on videos from various generative models, such as Sora, Lumiere, WALT, and Zeroscope. The experiments demonstrate that our method has a significant improvement over previous methods. Project page at: https://daipengwa.github.io/S-2VG_ProjectPage/
MMRAG-DocQA: A Multi-Modal Retrieval-Augmented Generation Method for Document Question-Answering with Hierarchical Index and Multi-Granularity Retrieval
Aug 01, 2025The multi-modal long-context document question-answering task aims to locate and integrate multi-modal evidences (such as texts, tables, charts, images, and layouts) distributed across multiple pages, for question understanding and answer generation. The existing methods can be categorized into Large Vision-Language Model (LVLM)-based and Retrieval-Augmented Generation (RAG)-based methods. However, the former were susceptible to hallucinations, while the latter struggled for inter-modal disconnection and cross-page fragmentation. To address these challenges, a novel multi-modal RAG model, named MMRAG-DocQA, was proposed, leveraging both textual and visual information across long-range pages to facilitate accurate question answering. A hierarchical indexing method with the integration of flattened in-page chunks and topological cross-page chunks was designed to jointly establish in-page multi-modal associations and long-distance cross-page dependencies. By means of joint similarity evaluation and large language model (LLM)-based re-ranking, a multi-granularity semantic retrieval method, including the page-level parent page retrieval and document-level summary retrieval, was proposed to foster multi-modal evidence connection and long-distance evidence integration and reasoning. Experimental results performed on public datasets, MMLongBench-Doc and LongDocURL, demonstrated the superiority of our MMRAG-DocQA method in understanding and answering modality-rich and multi-page documents.
BOASF: A Unified Framework for Speeding up Automatic Machine Learning via Adaptive Successive Filtering
Jul 28, 2025Machine learning has been making great success in many application areas. However, for the non-expert practitioners, it is always very challenging to address a machine learning task successfully and efficiently. Finding the optimal machine learning model or the hyperparameter combination set from a large number of possible alternatives usually requires considerable expert knowledge and experience. To tackle this problem, we propose a combined Bayesian Optimization and Adaptive Successive Filtering algorithm (BOASF) under a unified multi-armed bandit framework to automate the model selection or the hyperparameter optimization. Specifically, BOASF consists of multiple evaluation rounds in each of which we select promising configurations for each arm using the Bayesian optimization. Then, ASF can early discard the poor-performed arms adaptively using a Gaussian UCB-based probabilistic model. Furthermore, a Softmax model is employed to adaptively allocate available resources for each promising arm that advances to the next round. The arm with a higher probability of advancing will be allocated more resources. Experimental results show that BOASF is effective for speeding up the model selection and hyperparameter optimization processes while achieving robust and better prediction performance than the existing state-of-the-art automatic machine learning methods. Moreover, BOASF achieves better anytime performance under various time budgets.
PrunePEFT: Iterative Hybrid Pruning for Parameter-Efficient Fine-tuning of LLMs
Jun 09, 2025Parameter Efficient Fine-Tuning (PEFT) methods have emerged as effective and promising approaches for fine-tuning pre-trained language models. Compared with Full parameter Fine-Tuning (FFT), PEFT achieved comparable task performance with a substantial reduction of trainable parameters, which largely saved the training and storage costs. However, using the PEFT method requires considering a vast design space, such as the type of PEFT modules and their insertion layers. Inadequate configurations can lead to sub-optimal results. Conventional solutions such as architectural search techniques, while effective, tend to introduce substantial additional overhead. In this paper, we propose a novel approach, PrunePEFT, which formulates the PEFT strategy search as a pruning problem and introduces a hybrid pruning strategy that capitalizes on the sensitivity of pruning methods to different PEFT modules. This method extends traditional pruning techniques by iteratively removing redundant or conflicting PEFT modules, thereby optimizing the fine-tuned configuration. By efficiently identifying the most relevant modules, our approach significantly reduces the computational burden typically associated with architectural search processes, making it a more scalable and efficient solution for fine-tuning large pre-trained models.
KnowRA: Knowledge Retrieval Augmented Method for Document-level Relation Extraction with Comprehensive Reasoning Abilities
Jan 05, 2025



Document-level relation extraction (Doc-RE) aims to extract relations between entities across multiple sentences. Therefore, Doc-RE requires more comprehensive reasoning abilities like humans, involving complex cross-sentence interactions between entities, contexts, and external general knowledge, compared to the sentence-level RE. However, most existing Doc-RE methods focus on optimizing single reasoning ability, but lack the ability to utilize external knowledge for comprehensive reasoning on long documents. To solve these problems, a knowledge retrieval augmented method, named KnowRA, was proposed with comprehensive reasoning to autonomously determine whether to accept external knowledge to assist DocRE. Firstly, we constructed a document graph for semantic encoding and integrated the co-reference resolution model to augment the co-reference reasoning ability. Then, we expanded the document graph into a document knowledge graph by retrieving the external knowledge base for common-sense reasoning and a novel knowledge filtration method was presented to filter out irrelevant knowledge. Finally, we proposed the axis attention mechanism to build direct and indirect associations with intermediary entities for achieving cross-sentence logical reasoning. Extensive experiments conducted on two datasets verified the effectiveness of our method compared to the state-of-the-art baselines. Our code is available at https://anonymous.4open.science/r/KnowRA.
SA-GNAS: Seed Architecture Expansion for Efficient Large-scale Graph Neural Architecture Search
Dec 03, 2024


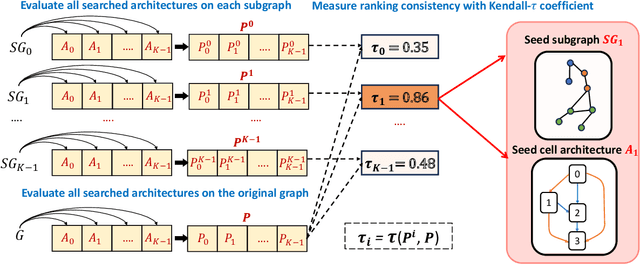
GNAS (Graph Neural Architecture Search) has demonstrated great effectiveness in automatically designing the optimal graph neural architectures for multiple downstream tasks, such as node classification and link prediction. However, most existing GNAS methods cannot efficiently handle large-scale graphs containing more than million-scale nodes and edges due to the expensive computational and memory overhead. To scale GNAS on large graphs while achieving better performance, we propose SA-GNAS, a novel framework based on seed architecture expansion for efficient large-scale GNAS. Similar to the cell expansion in biotechnology, we first construct a seed architecture and then expand the seed architecture iteratively. Specifically, we first propose a performance ranking consistency-based seed architecture selection method, which selects the architecture searched on the subgraph that best matches the original large-scale graph. Then, we propose an entropy minimization-based seed architecture expansion method to further improve the performance of the seed architecture. Extensive experimental results on five large-scale graphs demonstrate that the proposed SA-GNAS outperforms human-designed state-of-the-art GNN architectures and existing graph NAS methods. Moreover, SA-GNAS can significantly reduce the search time, showing better search efficiency. For the largest graph with billion edges, SA-GNAS can achieve 2.8 times speedup compared to the SOTA large-scale GNAS method GAUSS. Additionally, since SA-GNAS is inherently parallelized, the search efficiency can be further improved with more GPUs. SA-GNAS is available at https://github.com/PasaLab/SAGNAS.
Spec-Gaussian: Anisotropic View-Dependent Appearance for 3D Gaussian Splatting
Feb 24, 2024
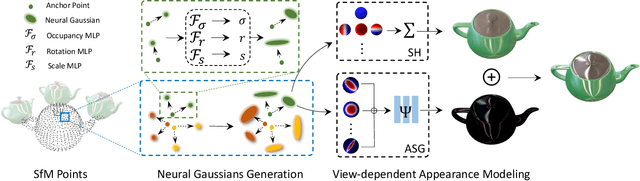
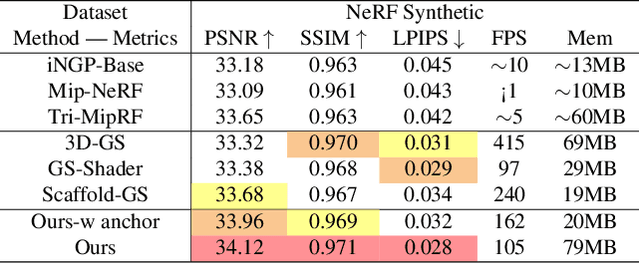
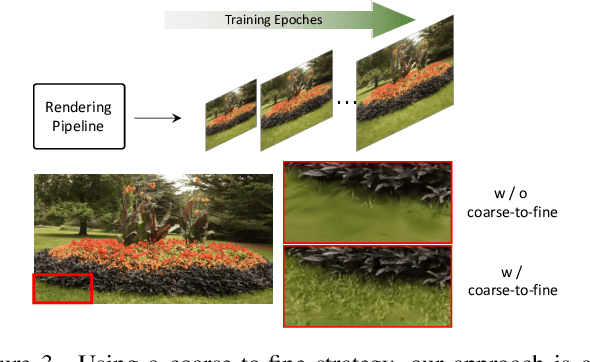
The recent advancements in 3D Gaussian splatting (3D-GS) have not only facilitated real-time rendering through modern GPU rasterization pipelines but have also attained state-of-the-art rendering quality. Nevertheless, despite its exceptional rendering quality and performance on standard datasets, 3D-GS frequently encounters difficulties in accurately modeling specular and anisotropic components. This issue stems from the limited ability of spherical harmonics (SH) to represent high-frequency information. To overcome this challenge, we introduce Spec-Gaussian, an approach that utilizes an anisotropic spherical Gaussian (ASG) appearance field instead of SH for modeling the view-dependent appearance of each 3D Gaussian. Additionally, we have developed a coarse-to-fine training strategy to improve learning efficiency and eliminate floaters caused by overfitting in real-world scenes. Our experimental results demonstrate that our method surpasses existing approaches in terms of rendering quality. Thanks to ASG, we have significantly improved the ability of 3D-GS to model scenes with specular and anisotropic components without increasing the number of 3D Gaussians. This improvement extends the applicability of 3D GS to handle intricate scenarios with specular and anisotropic surfaces.
Simple and Efficient Partial Graph Adversarial Attack: A New Perspective
Aug 15, 2023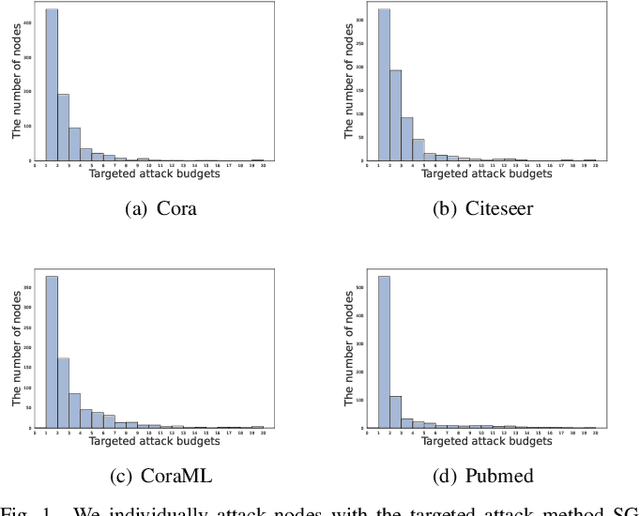
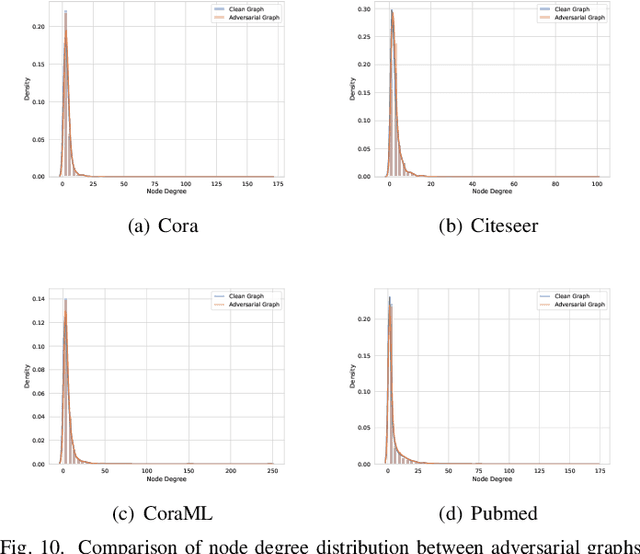
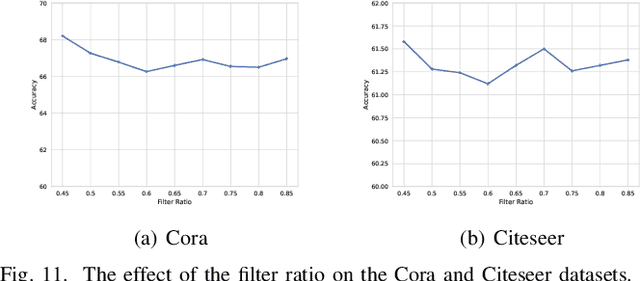
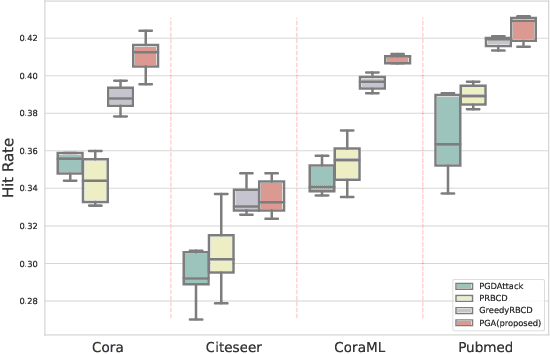
As the study of graph neural networks becomes more intensive and comprehensive, their robustness and security have received great research interest. The existing global attack methods treat all nodes in the graph as their attack targets. Although existing methods have achieved excellent results, there is still considerable space for improvement. The key problem is that the current approaches rigidly follow the definition of global attacks. They ignore an important issue, i.e., different nodes have different robustness and are not equally resilient to attacks. From a global attacker's view, we should arrange the attack budget wisely, rather than wasting them on highly robust nodes. To this end, we propose a totally new method named partial graph attack (PGA), which selects the vulnerable nodes as attack targets. First, to select the vulnerable items, we propose a hierarchical target selection policy, which allows attackers to only focus on easy-to-attack nodes. Then, we propose a cost-effective anchor-picking policy to pick the most promising anchors for adding or removing edges, and a more aggressive iterative greedy-based attack method to perform more efficient attacks. Extensive experimental results demonstrate that PGA can achieve significant improvements in both attack effect and attack efficiency compared to other existing graph global attack methods.
HAGNN: Hybrid Aggregation for Heterogeneous Graph Neural Networks
Jul 04, 2023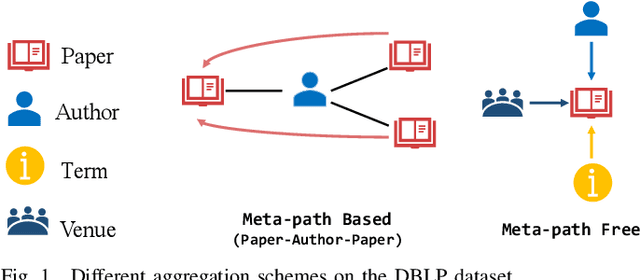
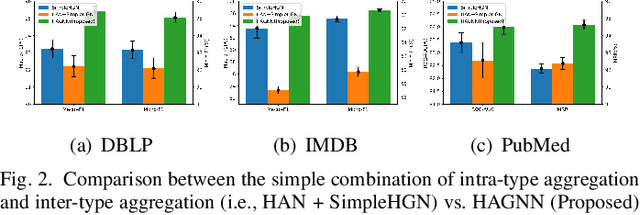
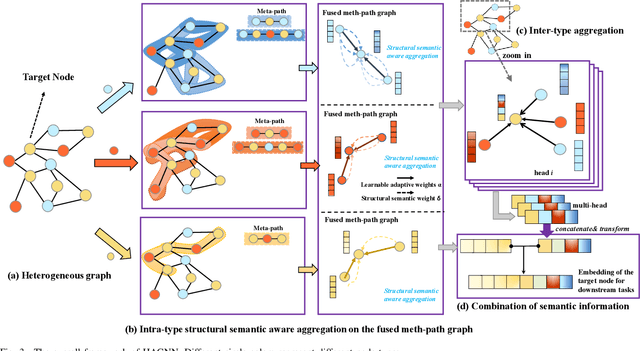
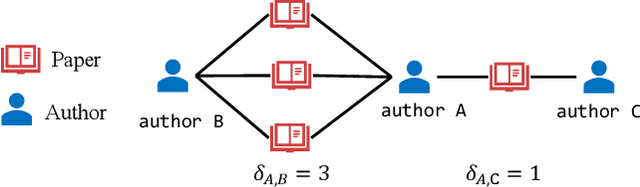
Heterogeneous graph neural networks (GNNs) have been successful in handling heterogeneous graphs. In existing heterogeneous GNNs, meta-path plays an essential role. However, recent work pointed out that simple homogeneous graph model without meta-path can also achieve comparable results, which calls into question the necessity of meta-path. In this paper, we first present the intrinsic difference about meta-path-based and meta-path-free models, i.e., how to select neighbors for node aggregation. Then, we propose a novel framework to utilize the rich type semantic information in heterogeneous graphs comprehensively, namely HAGNN (Hybrid Aggregation for Heterogeneous GNNs). The core of HAGNN is to leverage the meta-path neighbors and the directly connected neighbors simultaneously for node aggregations. HAGNN divides the overall aggregation process into two phases: meta-path-based intra-type aggregation and meta-path-free inter-type aggregation. During the intra-type aggregation phase, we propose a new data structure called fused meta-path graph and perform structural semantic aware aggregation on it. Finally, we combine the embeddings generated by each phase. Compared with existing heterogeneous GNN models, HAGNN can take full advantage of the heterogeneity in heterogeneous graphs. Extensive experimental results on node classification, node clustering, and link prediction tasks show that HAGNN outperforms the existing modes, demonstrating the effectiveness of HAGNN.
AutoAC: Towards Automated Attribute Completion for Heterogeneous Graph Neural Network
Jan 08, 2023



Many real-world data can be modeled as heterogeneous graphs that contain multiple types of nodes and edges. Meanwhile, due to excellent performance, heterogeneous graph neural networks (GNNs) have received more and more attention. However, the existing work mainly focuses on the design of novel GNN models, while ignoring another important issue that also has a large impact on the model performance, namely the missing attributes of some node types. The handcrafted attribute completion requires huge expert experience and domain knowledge. Also, considering the differences in semantic characteristics between nodes, the attribute completion should be fine-grained, i.e., the attribute completion operation should be node-specific. Moreover, to improve the performance of the downstream graph learning task, attribute completion and the training of the heterogeneous GNN should be jointly optimized rather than viewed as two separate processes. To address the above challenges, we propose a differentiable attribute completion framework called AutoAC for automated completion operation search in heterogeneous GNNs. We first propose an expressive completion operation search space, including topology-dependent and topology-independent completion operations. Then, we propose a continuous relaxation schema and further propose a differentiable completion algorithm where the completion operation search is formulated as a bi-level joint optimization problem. To improve the search efficiency, we leverage two optimization techniques: discrete constraints and auxiliary unsupervised graph node clustering. Extensive experimental results on real-world datasets reveal that AutoAC outperforms the SOTA handcrafted heterogeneous GNNs and the existing attribute completion method