 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix3R: Mixing Feed-forward Reconstruction and Generative 3D Priors for Joint Multi-view Aligned 3D Reconstruction and Pose Estimation
May 05, 2026Recent trends in sparse-view 3D reconstruction have taken two different paths: feed-forward reconstruction that predicts pixel-aligned point maps without a complete geometry, and generative 3D reconstruction that generates complete geometry but often with poor input-alignment. We present Mix3R, a novel generative 3D reconstruction method which mixes feed-forward reconstruction and 3D generation into a single framework in an aligned manner. Mix3R generates a 3D shape in two stages: a sparse voxel generation stage and a textured geometry generation stage. Unlike pure generative methods, our first-stage generation jointly produces a coarse 3D structure (sparse voxels), per-view point maps and camera parameters aligned to that 3D structure. This is made possible by introducing a Mixture-of-Transformers architecture that inserts global self-attentions to a feed-forward reconstruction model and a 3D generative model, both pretrained on large-scale data. This design effectively retains the pretrained priors but enables better 2D-3D alignment. Based on the initial aligned generations of sparse 3D voxels and point maps, we compute an overlap-based attention bias that is directly added to another pretrained textured geometry generation model, enabling it to correctly place input textures onto generated shapes in a training-free manner. Our design brings mutual benefits to both feed-forward reconstruction and 3D generation: The feed-forward branch learns to ground its predictions to a generative 3D prior, and conversely, the 3D generation branch is conditioned on geometrically informative features from the feed-forward branch. As a result, our method produces 3D shapes with better input alignment compared with pure 3D generative methods, together with camera pose estimations more accurate than previous feed-forward reconstruction methods. Our project page is at https://jsnln.github.io/mix3r/
DreamStereo: Towards Real-Time Stereo Inpainting for HD Videos
Apr 14, 2026Stereo video inpainting, which aims to fill the occluded regions of warped videos with visually coherent content while maintaining temporal consistency, remains a challenging open problem. The regions to be filled are scattered along object boundaries and occupy only a small fraction of each frame, leading to two key challenges. First, existing approaches perform poorly on such tasks due to the scarcity of high-quality stereo inpainting datasets, which limits their ability to learn effective inpainting priors. Second, these methods apply equal processing to all regions of the frame, even though most pixels require no modification, resulting in substantial redundant computation. To address these issues, we introduce three interconnected components. We first propose Gradient-Aware Parallax Warping (GAPW), which leverages backward warping and the gradient of the coordinate mapping function to obtain continuous edges and smooth occlusion regions. Then, a Parallax-Based Dual Projection (PBDP) strategy is introduced, which incorporates GAPW to produce geometrically consistent stereo inpainting pairs and accurate occlusion masks without requiring stereo videos. Finally, we present Sparsity-Aware Stereo Inpainting (SASI), which reduces over 70% of redundant tokens, achieving a 10.7x speedup during diffusion inference and delivering results comparable to its full-computation counterpart, enabling real-time processing of HD (768 x 1280) videos at 25 FPS on a single A100 GPU.
Director: Instance-aware Gaussian Splatting for Dynamic Scene Modeling and Understanding
Apr 02, 2026Volumetric video seeks to model dynamic scenes as temporally coherent 4D representations. While recent Gaussian-based approaches achieve impressive rendering fidelity, they primarily emphasize appearance but are largely agnostic to instance-level structure, limiting stable tracking and semantic reasoning in highly dynamic scenarios. In this paper, we present Director, a unified spatio-temporal Gaussian representation that jointly models human performance, high-fidelity rendering, and instance-level semantics. Our key insight is that embedding instance-consistent semantics naturally complements 4D modeling, enabling more accurate scene decomposition while supporting robust dynamic scene understanding. To this end, we leverage temporally aligned instance masks and sentence embeddings derived from Multimodal Large Language Models to supervise the learnable semantic features of each Gaussian via two MLP decoders, enabling language-aligned 4D representations and enforcing identity consistency over time. To enhance temporal stability, we bridge 2D optical flow with 4D Gaussians and finetune their motions, yielding reliable initialization and reducing drift. For the training, we further introduce a geometry-aware SDF constraints, along with regularization terms that enforces surface continuity, enhancing temporal coherence in dynamic foreground modeling. Experiments demonstrate that Director achieves temporally coherent 4D reconstructions while simultaneously enabling instance segmentation and open-vocabulary querying.
Towards Universal Video MLLMs with Attribute-Structured and Quality-Verified Instructions
Feb 13, 2026Universal video understanding requires modeling fine-grained visual and audio information over time in diverse real-world scenarios. However, the performance of existing models is primarily constrained by video-instruction data that represents complex audiovisual content as single, incomplete descriptions, lacking fine-grained organization and reliable annotation. To address this, we introduce: (i) ASID-1M, an open-source collection of one million structured, fine-grained audiovisual instruction annotations with single- and multi-attribute supervision; (ii) ASID-Verify, a scalable data curation pipeline for annotation, with automatic verification and refinement that enforces semantic and temporal consistency between descriptions and the corresponding audiovisual content; and (iii) ASID-Captioner, a video understanding model trained via Supervised Fine-Tuning (SFT) on the ASID-1M. Experiments across seven benchmarks covering audiovisual captioning, attribute-wise captioning, caption-based QA, and caption-based temporal grounding show that ASID-Captioner improves fine-grained caption quality while reducing hallucinations and improving instruction following. It achieves state-of-the-art performance among open-source models and is competitive with Gemini-3-Pro.
IDCNet: Guided Video Diffusion for Metric-Consistent RGBD Scene Generation with Precise Camera Control
Aug 06, 2025We present IDC-Net (Image-Depth Consistency Network), a novel framework designed to generate RGB-D video sequences under explicit camera trajectory control. Unlike approaches that treat RGB and depth generation separately, IDC-Net jointly synthesizes both RGB images and corresponding depth maps within a unified geometry-aware diffusion model. The joint learning framework strengthens spatial and geometric alignment across frames, enabling more precise camera control in the generated sequences. To support the training of this camera-conditioned model and ensure high geometric fidelity, we construct a camera-image-depth consistent dataset with metric-aligned RGB videos, depth maps, and accurate camera poses, which provides precise geometric supervision with notably improved inter-frame geometric consistency. Moreover, we introduce a geometry-aware transformer block that enables fine-grained camera control, enhancing control over the generated sequences. Extensive experiments show that IDC-Net achieves improvements over state-of-the-art approaches in both visual quality and geometric consistency of generated scene sequences. Notably, the generated RGB-D sequences can be directly feed for downstream 3D Scene reconstruction tasks without extra post-processing steps, showcasing the practical benefits of our joint learning framework. See more at https://idcnet-scene.github.io.
EvolvingGS: High-Fidelity Streamable Volumetric Video via Evolving 3D Gaussian Representation
Mar 07, 2025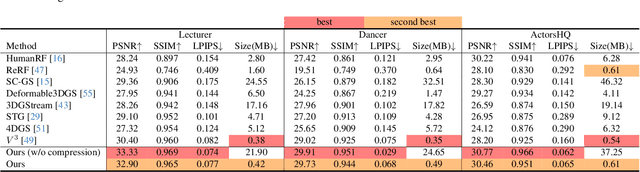
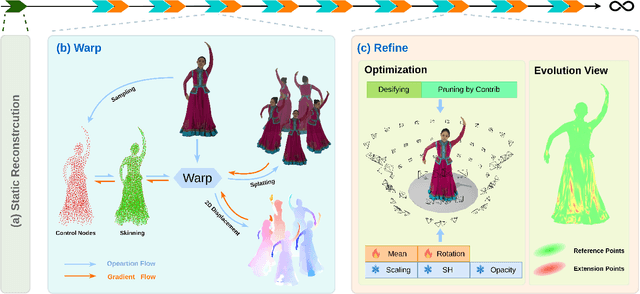
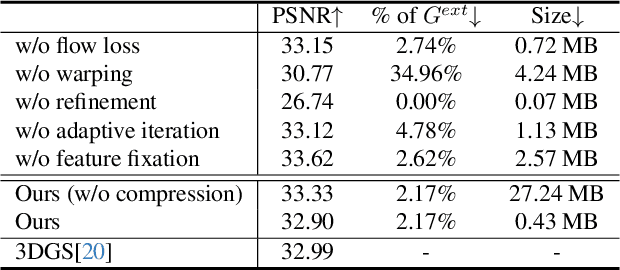

We have recently seen great progress in 3D scene reconstruction through explicit point-based 3D Gaussian Splatting (3DGS), notable for its high quality and fast rendering speed. However, reconstructing dynamic scenes such as complex human performances with long durations remains challenging. Prior efforts fall short of modeling a long-term sequence with drastic motions, frequent topology changes or interactions with props, and resort to segmenting the whole sequence into groups of frames that are processed independently, which undermines temporal stability and thereby leads to an unpleasant viewing experience and inefficient storage footprint. In view of this, we introduce EvolvingGS, a two-stage strategy that first deforms the Gaussian model to coarsely align with the target frame, and then refines it with minimal point addition/subtraction, particularly in fast-changing areas. Owing to the flexibility of the incrementally evolving representation, our method outperforms existing approaches in terms of both per-frame and temporal quality metrics while maintaining fast rendering through its purely explicit representation. Moreover, by exploiting temporal coherence between successive frames, we propose a simple yet effective compression algorithm that achieves over 50x compression rate. Extensive experiments on both public benchmarks and challenging custom datasets demonstrate that our method significantly advances the state-of-the-art in dynamic scene reconstruction, particularly for extended sequences with complex human performances.
Spec-Gaussian: Anisotropic View-Dependent Appearance for 3D Gaussian Splatting
Feb 24, 2024
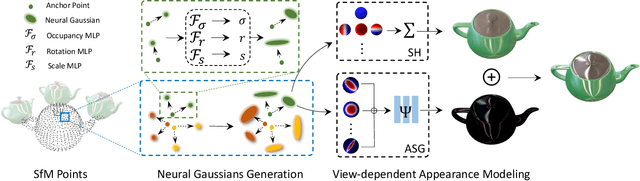
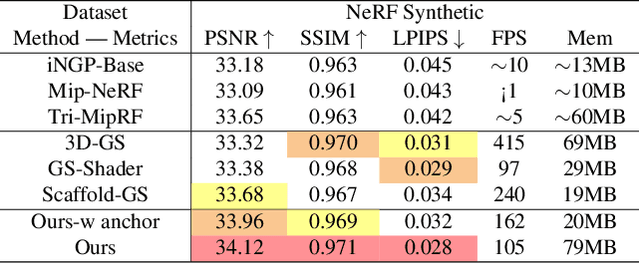
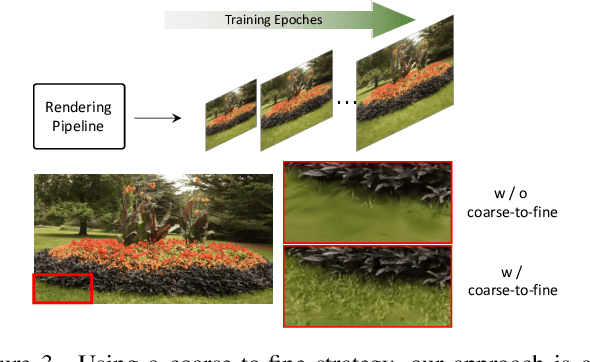
The recent advancements in 3D Gaussian splatting (3D-GS) have not only facilitated real-time rendering through modern GPU rasterization pipelines but have also attained state-of-the-art rendering quality. Nevertheless, despite its exceptional rendering quality and performance on standard datasets, 3D-GS frequently encounters difficulties in accurately modeling specular and anisotropic components. This issue stems from the limited ability of spherical harmonics (SH) to represent high-frequency information. To overcome this challenge, we introduce Spec-Gaussian, an approach that utilizes an anisotropic spherical Gaussian (ASG) appearance field instead of SH for modeling the view-dependent appearance of each 3D Gaussian. Additionally, we have developed a coarse-to-fine training strategy to improve learning efficiency and eliminate floaters caused by overfitting in real-world scenes. Our experimental results demonstrate that our method surpasses existing approaches in terms of rendering quality. Thanks to ASG, we have significantly improved the ability of 3D-GS to model scenes with specular and anisotropic components without increasing the number of 3D Gaussians. This improvement extends the applicability of 3D GS to handle intricate scenarios with specular and anisotropic surfaces.
Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction
Sep 22, 2023Implicit neural representation has opened up new avenues for dynamic scene reconstruction and rendering. Nonetheless, state-of-the-art methods of dynamic neural rendering rely heavily on these implicit representations, which frequently struggle with accurately capturing the intricate details of objects in the scene. Furthermore, implicit methods struggle to achieve real-time rendering in general dynamic scenes, limiting their use in a wide range of tasks. To address the issues, we propose a deformable 3D Gaussians Splatting method that reconstructs scenes using explicit 3D Gaussians and learns Gaussians in canonical space with a deformation field to model monocular dynamic scenes. We also introduced a smoothing training mechanism with no extra overhead to mitigate the impact of inaccurate poses in real datasets on the smoothness of time interpolation tasks. Through differential gaussian rasterization, the deformable 3D Gaussians not only achieve higher rendering quality but also real-time rendering speed. Experiments show that our method outperforms existing methods significantly in terms of both rendering quality and speed, making it well-suited for tasks such as novel-view synthesis, time synthesis, and real-time rendering.
SQLdepth: Generalizable Self-Supervised Fine-Structured Monocular Depth Estimation
Sep 01, 2023



Recently, self-supervised monocular depth estimation has gained popularity with numerous applications in autonomous driving and robotics. However, existing solutions primarily seek to estimate depth from immediate visual features, and struggle to recover fine-grained scene details with limited generalization. In this paper, we introduce SQLdepth, a novel approach that can effectively learn fine-grained scene structures from motion. In SQLdepth, we propose a novel Self Query Layer (SQL) to build a self-cost volume and infer depth from it, rather than inferring depth from feature maps. The self-cost volume implicitly captures the intrinsic geometry of the scene within a single frame. Each individual slice of the volume signifies the relative distances between points and objects within a latent space. Ultimately, this volume is compressed to the depth map via a novel decoding approach. Experimental results on KITTI and Cityscapes show that our method attains remarkable state-of-the-art performance (AbsRel = $0.082$ on KITTI, $0.052$ on KITTI with improved ground-truth and $0.106$ on Cityscapes), achieves $9.9\%$, $5.5\%$ and $4.5\%$ error reduction from the previous best. In addition, our approach showcases reduced training complexity, computational efficiency, improved generalization, and the ability to recover fine-grained scene details. Moreover, the self-supervised pre-trained and metric fine-tuned SQLdepth can surpass existing supervised methods by significant margins (AbsRel = $0.043$, $14\%$ error reduction). self-matching-oriented relative distance querying in SQL improves the robustness and zero-shot generalization capability of SQLdepth. Code and the pre-trained weights will be publicly available. Code is available at \href{https://github.com/hisfog/SQLdepth-Impl}{https://github.com/hisfog/SQLdepth-Impl}.