 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBF-GAN: Development of an AI-driven Bubbly Flow Image Generation Model Using Generative Adversarial Networks
Feb 08, 2025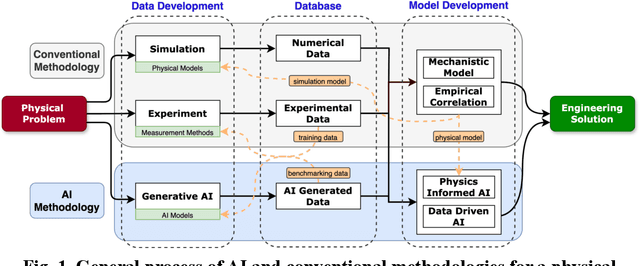
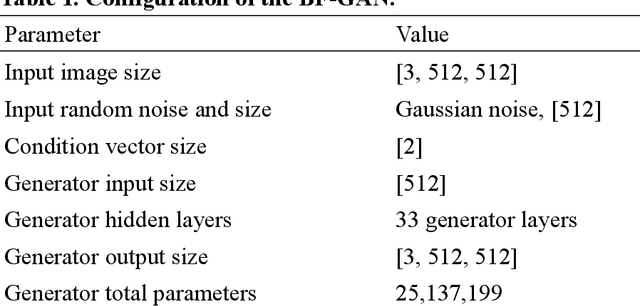

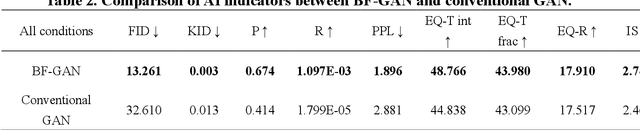
A generative AI architecture called bubbly flow generative adversarial networks (BF-GAN) is developed, designed to generate realistic and high-quality bubbly flow images through physically conditioned inputs, jg and jf. Initially, 52 sets of bubbly flow experiments under varying conditions are conducted to collect 140,000 bubbly flow images with physical labels of jg and jf for training data. A multi-scale loss function is then developed, incorporating mismatch loss and pixel loss to enhance the generative performance of BF-GAN further. Regarding evaluative metrics of generative AI, the BF-GAN has surpassed conventional GAN. Physically, key parameters of bubbly flow generated by BF-GAN are extracted and compared with measurement values and empirical correlations, validating BF-GAN's generative performance. The comparative analysis demonstrate that the BF-GAN can generate realistic and high-quality bubbly flow images with any given jg and jf within the research scope. BF-GAN offers a generative AI solution for two-phase flow research, substantially lowering the time and cost required to obtain high-quality data. In addition, it can function as a benchmark dataset generator for bubbly flow detection and segmentation algorithms, enhancing overall productivity in this research domain. The BF-GAN model is available online (https://github.com/zhouzhouwen/BF-GAN).
Dynamic data sampler for cross-language transfer learning in large language models
May 17, 2024Large Language Models (LLMs) have gained significant attention in the field of natural language processing (NLP) due to their wide range of applications. However, training LLMs for languages other than English poses significant challenges, due to the difficulty in acquiring large-scale corpus and the requisite computing resources. In this paper, we propose ChatFlow, a cross-language transfer-based LLM, to address these challenges and train large Chinese language models in a cost-effective manner. We employ a mix of Chinese, English, and parallel corpus to continuously train the LLaMA2 model, aiming to align cross-language representations and facilitate the knowledge transfer specifically to the Chinese language model. In addition, we use a dynamic data sampler to progressively transition the model from unsupervised pre-training to supervised fine-tuning. Experimental results demonstrate that our approach accelerates model convergence and achieves superior performance. We evaluate ChatFlow on popular Chinese and English benchmarks, the results indicate that it outperforms other Chinese models post-trained on LLaMA-2-7B.
Spec-Gaussian: Anisotropic View-Dependent Appearance for 3D Gaussian Splatting
Feb 24, 2024
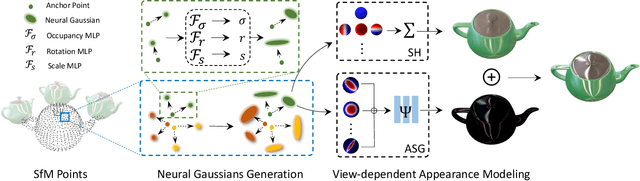
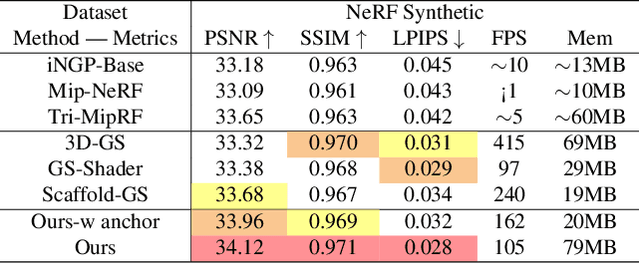
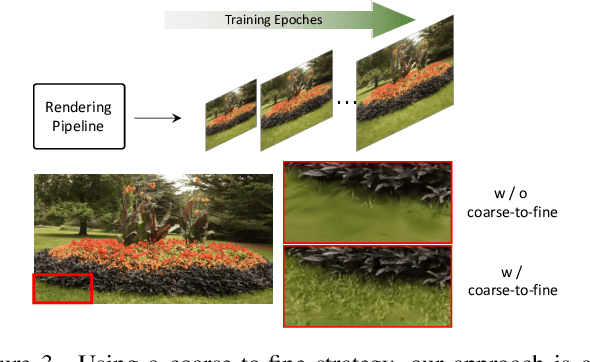
The recent advancements in 3D Gaussian splatting (3D-GS) have not only facilitated real-time rendering through modern GPU rasterization pipelines but have also attained state-of-the-art rendering quality. Nevertheless, despite its exceptional rendering quality and performance on standard datasets, 3D-GS frequently encounters difficulties in accurately modeling specular and anisotropic components. This issue stems from the limited ability of spherical harmonics (SH) to represent high-frequency information. To overcome this challenge, we introduce Spec-Gaussian, an approach that utilizes an anisotropic spherical Gaussian (ASG) appearance field instead of SH for modeling the view-dependent appearance of each 3D Gaussian. Additionally, we have developed a coarse-to-fine training strategy to improve learning efficiency and eliminate floaters caused by overfitting in real-world scenes. Our experimental results demonstrate that our method surpasses existing approaches in terms of rendering quality. Thanks to ASG, we have significantly improved the ability of 3D-GS to model scenes with specular and anisotropic components without increasing the number of 3D Gaussians. This improvement extends the applicability of 3D GS to handle intricate scenarios with specular and anisotropic surfaces.
Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction
Sep 22, 2023Implicit neural representation has opened up new avenues for dynamic scene reconstruction and rendering. Nonetheless, state-of-the-art methods of dynamic neural rendering rely heavily on these implicit representations, which frequently struggle with accurately capturing the intricate details of objects in the scene. Furthermore, implicit methods struggle to achieve real-time rendering in general dynamic scenes, limiting their use in a wide range of tasks. To address the issues, we propose a deformable 3D Gaussians Splatting method that reconstructs scenes using explicit 3D Gaussians and learns Gaussians in canonical space with a deformation field to model monocular dynamic scenes. We also introduced a smoothing training mechanism with no extra overhead to mitigate the impact of inaccurate poses in real datasets on the smoothness of time interpolation tasks. Through differential gaussian rasterization, the deformable 3D Gaussians not only achieve higher rendering quality but also real-time rendering speed. Experiments show that our method outperforms existing methods significantly in terms of both rendering quality and speed, making it well-suited for tasks such as novel-view synthesis, time synthesis, and real-time rendering.
VMCDL: Vulnerability Mining Based on Cascaded Deep Learning Under Source Control Flow
Mar 24, 2023With the rapid development of the computer industry and computer software, the risk of software vulnerabilities being exploited has greatly increased. However, there are still many shortcomings in the existing mining techniques for leakage source research, such as high false alarm rate, coarse-grained detection, and dependence on expert experience. In this paper, we mainly use the c/c++ source code data of the SARD dataset, process the source code of CWE476, CWE469, CWE516 and CWE570 vulnerability types, test the Joern vulnerability scanning function of the cutting-edge tool, and propose a new cascading deep learning model VMCDL based on source code control flow to effectively detect vulnerabilities. First, this paper uses joern to locate and extract sensitive functions and statements to form a sensitive statement library of vulnerable code. Then, the CFG flow vulnerability code snippets are generated by bidirectional breadth-first traversal, and then vectorized by Doc2vec. Finally, the cascade deep learning model based on source code control flow is used for classification to obtain the classification results. In the experimental evaluation, we give the test results of Joern on specific vulnerabilities, and give the confusion matrix and label data of the binary classification results of the model algorithm on single vulnerability type source code, and compare and verify the five indicators of FPR, FNR, ACC, P and F1, respectively reaching 10.30%, 5.20%, 92.50%,85.10% and 85.40%,which shows that it can effectively reduce the false alarm rate of static analysis.
Based on particle swarm optimization support vector machine model of the electric car sales strategy research
Dec 03, 2022From the perspective of constructing the classification model, this paper uses the weight coefficient (influencing factors) in the model to analyze the sales impact on different brands of electric vehicles, and optimizes the existing sales strategy.
DCDetector: An IoT terminal vulnerability mining system based on distributed deep ensemble learning under source code representation
Dec 03, 2022Context: The IoT system infrastructure platform facility vulnerability attack has become the main battlefield of network security attacks. Most of the traditional vulnerability mining methods rely on vulnerability detection tools to realize vulnerability discovery. However, due to the inflexibility of tools and the limitation of file size, its scalability It is relatively low and cannot be applied to large-scale power big data fields. Objective: The goal of the research is to intelligently detect vulnerabilities in source codes of high-level languages such as C/C++. This enables us to propose a code representation of sensitive sentence-related slices of source code, and to detect vulnerabilities by designing a distributed deep ensemble learning model. Method: In this paper, a new directional vulnerability mining method of parallel ensemble learning is proposed to solve the problem of large-scale data vulnerability mining. By extracting sensitive functions and statements, a sensitive statement library of vulnerable codes is formed. The AST stream-based vulnerability code slice with higher granularity performs doc2vec sentence vectorization on the source code through the random sampling module, obtains different classification results through distributed training through the Bi-LSTM trainer, and obtains the final classification result by voting. Results: This method designs and implements a distributed deep ensemble learning system software vulnerability mining system called DCDetector. It can make accurate predictions by using the syntactic information of the code, and is an effective method for analyzing large-scale vulnerability data. Conclusion: Experiments show that this method can reduce the false positive rate of traditional static analysis and improve the performance and accuracy of machine learning.
A Temporal Densely Connected Recurrent Network for Event-based Human Pose Estimation
Sep 15, 2022

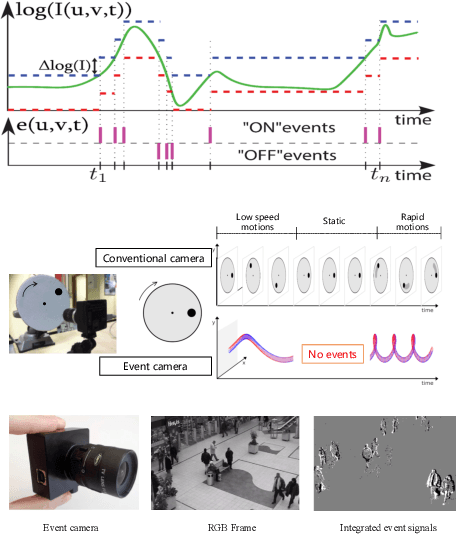
Event camera is an emerging bio-inspired vision sensors that report per-pixel brightness changes asynchronously. It holds noticeable advantage of high dynamic range, high speed response, and low power budget that enable it to best capture local motions in uncontrolled environments. This motivates us to unlock the potential of event cameras for human pose estimation, as the human pose estimation with event cameras is rarely explored. Due to the novel paradigm shift from conventional frame-based cameras, however, event signals in a time interval contain very limited information, as event cameras can only capture the moving body parts and ignores those static body parts, resulting in some parts to be incomplete or even disappeared in the time interval. This paper proposes a novel densely connected recurrent architecture to address the problem of incomplete information. By this recurrent architecture, we can explicitly model not only the sequential but also non-sequential geometric consistency across time steps to accumulate information from previous frames to recover the entire human bodies, achieving a stable and accurate human pose estimation from event data. Moreover, to better evaluate our model, we collect a large scale multimodal event-based dataset that comes with human pose annotations, which is by far the most challenging one to the best of our knowledge. The experimental results on two public datasets and our own dataset demonstrate the effectiveness and strength of our approach. Code can be available online for facilitating the future research.
Modeling High-Dimensional Data with Unknown Cut Points: A Fusion Penalized Logistic Threshold Regression
Feb 17, 2022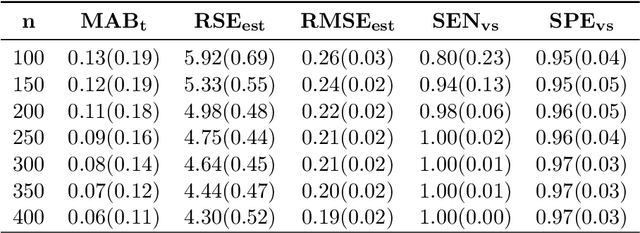
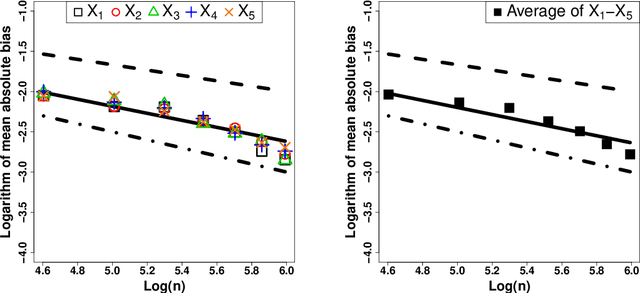
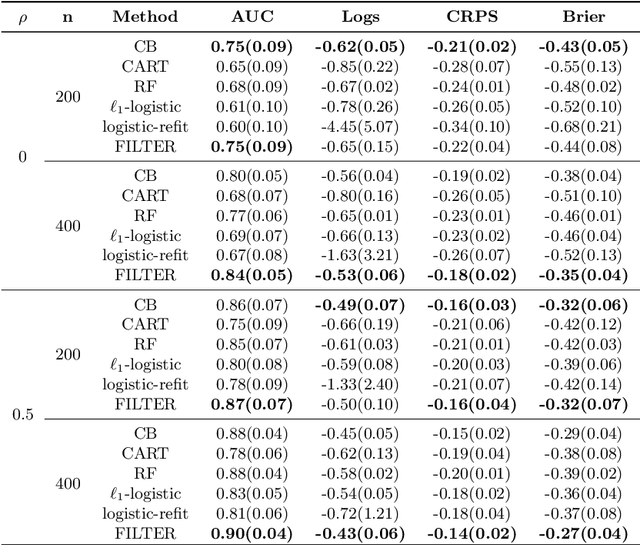
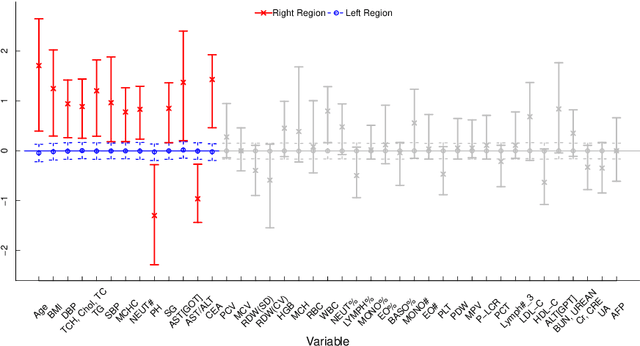
In traditional logistic regression models, the link function is often assumed to be linear and continuous in predictors. Here, we consider a threshold model that all continuous features are discretized into ordinal levels, which further determine the binary responses. Both the threshold points and regression coefficients are unknown and to be estimated. For high dimensional data, we propose a fusion penalized logistic threshold regression (FILTER) model, where a fused lasso penalty is employed to control the total variation and shrink the coefficients to zero as a method of variable selection. Under mild conditions on the estimate of unknown threshold points, we establish the non-asymptotic error bound for coefficient estimation and the model selection consistency. With a careful characterization of the error propagation, we have also shown that the tree-based method, such as CART, fulfill the threshold estimation conditions. We find the FILTER model is well suited in the problem of early detection and prediction for chronic disease like diabetes, using physical examination data. The finite sample behavior of our proposed method are also explored and compared with extensive Monte Carlo studies, which supports our theoretical discoveries.
Improving Code Autocompletion with Transfer Learning
May 12, 2021
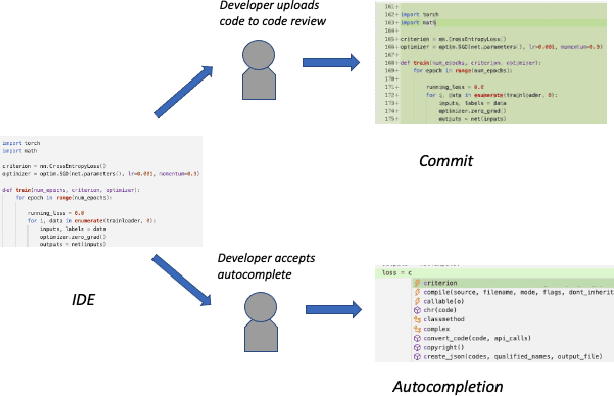
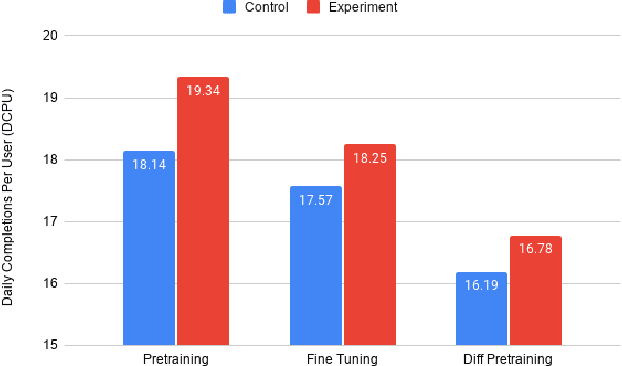
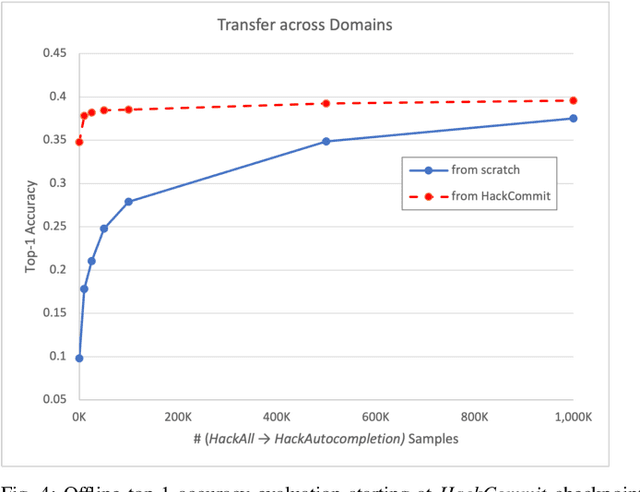
Software language models have achieved promising results predicting code completion usages, and several industry studies have described successful IDE integrations. Recently, accuracy in autocompletion prediction improved 12.8% from training on a real-world dataset collected from programmers' IDE activity. But what if limited examples of IDE autocompletion in the target programming language are available for model training? In this paper, we investigate the efficacy of pretraining autocompletion models on non-IDE, non-autocompletion, and different-language example code sequences. We find that these unsupervised pretrainings improve model accuracy by over 50% on very small fine-tuning datasets and over 10% on 50k labeled examples. We confirm the real-world impact of these pretrainings in an online setting through A/B testing on thousands of IDE autocompletion users, finding that pretraining is responsible for increases of up to 6.63% autocompletion usage.