 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards General and Fast Video Derain via Knowledge Distillation
Aug 10, 2023



As a common natural weather condition, rain can obscure video frames and thus affect the performance of the visual system, so video derain receives a lot of attention. In natural environments, rain has a wide variety of streak types, which increases the difficulty of the rain removal task. In this paper, we propose a Rain Review-based General video derain Network via knowledge distillation (named RRGNet) that handles different rain streak types with one pre-training weight. Specifically, we design a frame grouping-based encoder-decoder network that makes full use of the temporal information of the video. Further, we use the old task model to guide the current model in learning new rain streak types while avoiding forgetting. To consolidate the network's ability to derain, we design a rain review module to play back data from old tasks for the current model. The experimental results show that our developed general method achieves the best results in terms of running speed and derain effect.
Event Voxel Set Transformer for Spatiotemporal Representation Learning on Event Streams
Mar 07, 2023Event cameras are neuromorphic vision sensors representing visual information as sparse and asynchronous event streams. Most state-of-the-art event-based methods project events into dense frames and process them with conventional learning models. However, these approaches sacrifice the sparsity and high temporal resolution of event data, resulting in a large model size and high computational complexity. To fit the sparse nature of events and sufficiently explore their implicit relationship, we develop a novel attention-aware framework named Event Voxel Set Transformer (EVSTr) for spatiotemporal representation learning on event streams. It first converts the event stream into a voxel set and then hierarchically aggregates voxel features to obtain robust representations. The core of EVSTr is an event voxel transformer encoder to extract discriminative spatiotemporal features, which consists of two well-designed components, including a multi-scale neighbor embedding layer (MNEL) for local information aggregation and a voxel self-attention layer (VSAL) for global representation modeling. Enabling the framework to incorporate a long-term temporal structure, we introduce a segmental consensus strategy for modeling motion patterns over a sequence of segmented voxel sets. We evaluate the proposed framework on two event-based tasks: object classification and action recognition. Comprehensive experiments show that EVSTr achieves state-of-the-art performance while maintaining low model complexity. Additionally, we present a new dataset (NeuroHAR) recorded in challenging visual scenarios to address the lack of real-world event-based datasets for action recognition.
A Temporal Densely Connected Recurrent Network for Event-based Human Pose Estimation
Sep 15, 2022

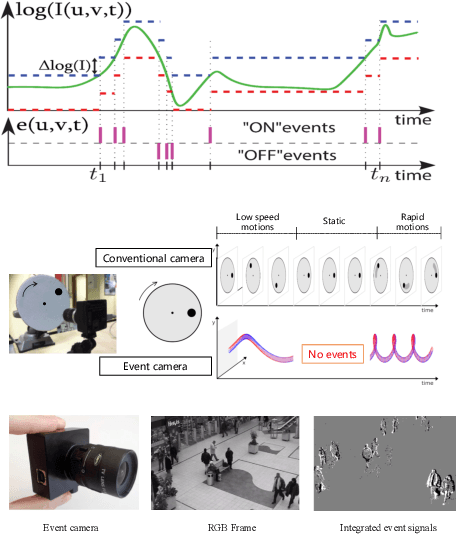
Event camera is an emerging bio-inspired vision sensors that report per-pixel brightness changes asynchronously. It holds noticeable advantage of high dynamic range, high speed response, and low power budget that enable it to best capture local motions in uncontrolled environments. This motivates us to unlock the potential of event cameras for human pose estimation, as the human pose estimation with event cameras is rarely explored. Due to the novel paradigm shift from conventional frame-based cameras, however, event signals in a time interval contain very limited information, as event cameras can only capture the moving body parts and ignores those static body parts, resulting in some parts to be incomplete or even disappeared in the time interval. This paper proposes a novel densely connected recurrent architecture to address the problem of incomplete information. By this recurrent architecture, we can explicitly model not only the sequential but also non-sequential geometric consistency across time steps to accumulate information from previous frames to recover the entire human bodies, achieving a stable and accurate human pose estimation from event data. Moreover, to better evaluate our model, we collect a large scale multimodal event-based dataset that comes with human pose annotations, which is by far the most challenging one to the best of our knowledge. The experimental results on two public datasets and our own dataset demonstrate the effectiveness and strength of our approach. Code can be available online for facilitating the future research.
RRV: A Spatiotemporal Descriptor for Rigid Body Motion Recognition
Jun 04, 2017
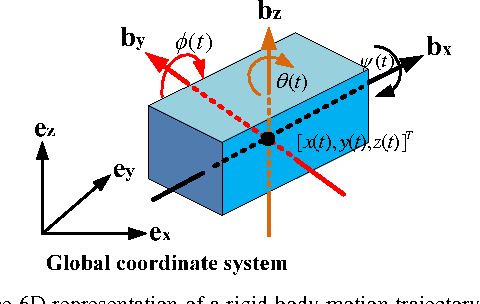
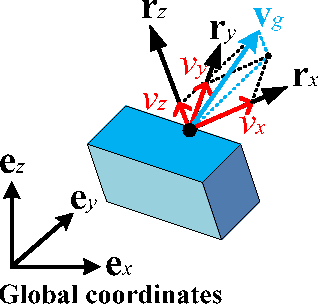
Motion behaviors of a rigid body can be characterized by a 6-dimensional motion trajectory, which contains position vectors of a reference point on the rigid body and rotations of this rigid body over time. This paper devises a Rotation and Relative Velocity (RRV) descriptor by exploring the local translational and rotational invariants of motion trajectories of rigid bodies, which is insensitive to noise, invariant to rigid transformation and scaling. A flexible metric is also introduced to measure the distance between two RRV descriptors. The RRV descriptor is then applied to characterize motions of a human body skeleton modeled as articulated interconnections of multiple rigid bodies. To illustrate the descriptive ability of the RRV descriptor, we explore it for different rigid body motion recognition tasks. The experimental results on benchmark datasets demonstrate that this simple RRV descriptor outperforms the previous ones regarding recognition accuracy without increasing computational cost.