 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially-guided Temporal Aggregation for Robust Event-RGB Optical Flow Estimation
Jan 01, 2025



Current optical flow methods exploit the stable appearance of frame (or RGB) data to establish robust correspondences across time. Event cameras, on the other hand, provide high-temporal-resolution motion cues and excel in challenging scenarios. These complementary characteristics underscore the potential of integrating frame and event data for optical flow estimation. However, most cross-modal approaches fail to fully utilize the complementary advantages, relying instead on simply stacking information. This study introduces a novel approach that uses a spatially dense modality to guide the aggregation of the temporally dense event modality, achieving effective cross-modal fusion. Specifically, we propose an event-enhanced frame representation that preserves the rich texture of frames and the basic structure of events. We use the enhanced representation as the guiding modality and employ events to capture temporally dense motion information. The robust motion features derived from the guiding modality direct the aggregation of motion information from events. To further enhance fusion, we propose a transformer-based module that complements sparse event motion features with spatially rich frame information and enhances global information propagation. Additionally, a mix-fusion encoder is designed to extract comprehensive spatiotemporal contextual features from both modalities. Extensive experiments on the MVSEC and DSEC-Flow datasets demonstrate the effectiveness of our framework. Leveraging the complementary strengths of frames and events, our method achieves leading performance on the DSEC-Flow dataset. Compared to the event-only model, frame guidance improves accuracy by 10\%. Furthermore, it outperforms the state-of-the-art fusion-based method with a 4\% accuracy gain and a 45\% reduction in inference time.
ResFlow: Fine-tuning Residual Optical Flow for Event-based High Temporal Resolution Motion Estimation
Dec 12, 2024



Event cameras hold significant promise for high-temporal-resolution (HTR) motion estimation. However, estimating event-based HTR optical flow faces two key challenges: the absence of HTR ground-truth data and the intrinsic sparsity of event data. Most existing approaches rely on the flow accumulation paradigms to indirectly supervise intermediate flows, often resulting in accumulation errors and optimization difficulties. To address these challenges, we propose a residual-based paradigm for estimating HTR optical flow with event data. Our approach separates HTR flow estimation into two stages: global linear motion estimation and HTR residual flow refinement. The residual paradigm effectively mitigates the impacts of event sparsity on optimization and is compatible with any LTR algorithm. Next, to address the challenge posed by the absence of HTR ground truth, we incorporate novel learning strategies. Specifically, we initially employ a shared refiner to estimate the residual flows, enabling both LTR supervision and HTR inference. Subsequently, we introduce regional noise to simulate the residual patterns of intermediate flows, facilitating the adaptation from LTR supervision to HTR inference. Additionally, we show that the noise-based strategy supports in-domain self-supervised training. Comprehensive experimental results demonstrate that our approach achieves state-of-the-art accuracy in both LTR and HTR metrics, highlighting its effectiveness and superiority.
SLAM-based Joint Calibration of Multiple Asynchronous Microphone Arrays and Sound Source Localization
May 30, 2024



Robot audition systems with multiple microphone arrays have many applications in practice. However, accurate calibration of multiple microphone arrays remains challenging because there are many unknown parameters to be identified, including the relative transforms (i.e., orientation, translation) and asynchronous factors (i.e., initial time offset and sampling clock difference) between microphone arrays. To tackle these challenges, in this paper, we adopt batch simultaneous localization and mapping (SLAM) for joint calibration of multiple asynchronous microphone arrays and sound source localization. Using the Fisher information matrix (FIM) approach, we first conduct the observability analysis (i.e., parameter identifiability) of the above-mentioned calibration problem and establish necessary/sufficient conditions under which the FIM and the Jacobian matrix have full column rank, which implies the identifiability of the unknown parameters. We also discover several scenarios where the unknown parameters are not uniquely identifiable. Subsequently, we propose an effective framework to initialize the unknown parameters, which is used as the initial guess in batch SLAM for multiple microphone arrays calibration, aiming to further enhance optimization accuracy and convergence. Extensive numerical simulations and real experiments have been conducted to verify the performance of the proposed method. The experiment results show that the proposed pipeline achieves higher accuracy with fast convergence in comparison to methods that use the noise-corrupted ground truth of the unknown parameters as the initial guess in the optimization and other existing frameworks.
Event-based Video Frame Interpolation with Edge Guided Motion Refinement
Apr 28, 2024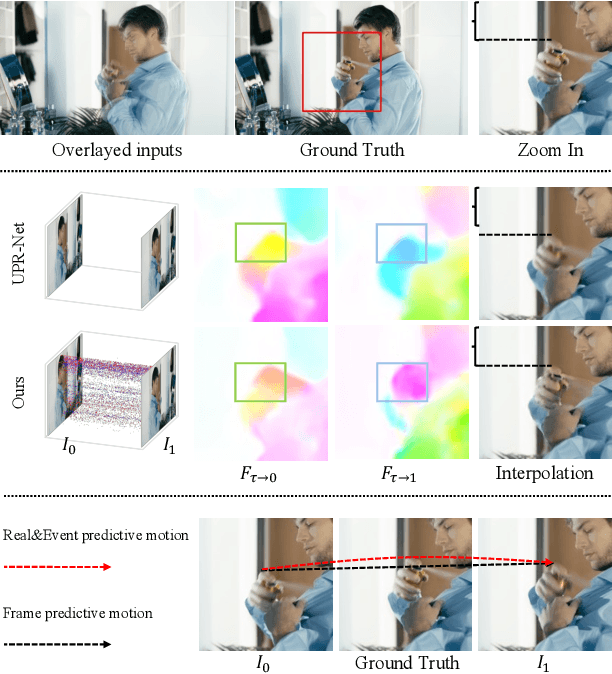

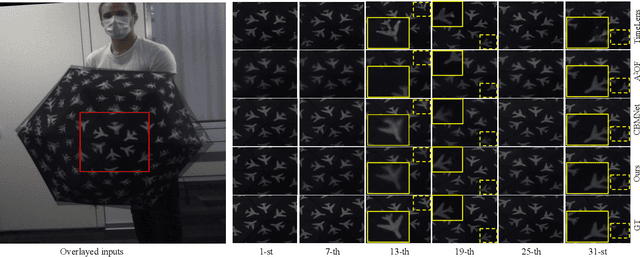

Video frame interpolation, the process of synthesizing intermediate frames between sequential video frames, has made remarkable progress with the use of event cameras. These sensors, with microsecond-level temporal resolution, fill information gaps between frames by providing precise motion cues. However, contemporary Event-Based Video Frame Interpolation (E-VFI) techniques often neglect the fact that event data primarily supply high-confidence features at scene edges during multi-modal feature fusion, thereby diminishing the role of event signals in optical flow (OF) estimation and warping refinement. To address this overlooked aspect, we introduce an end-to-end E-VFI learning method (referred to as EGMR) to efficiently utilize edge features from event signals for motion flow and warping enhancement. Our method incorporates an Edge Guided Attentive (EGA) module, which rectifies estimated video motion through attentive aggregation based on the local correlation of multi-modal features in a coarse-to-fine strategy. Moreover, given that event data can provide accurate visual references at scene edges between consecutive frames, we introduce a learned visibility map derived from event data to adaptively mitigate the occlusion problem in the warping refinement process. Extensive experiments on both synthetic and real datasets show the effectiveness of the proposed approach, demonstrating its potential for higher quality video frame interpolation.
ANMS: Asynchronous Non-Maximum Suppression in Event Stream
Mar 19, 2023The non-maximum suppression (NMS) is widely used in frame-based tasks as an essential post-processing algorithm. However, event-based NMS either has high computational complexity or leads to frequent discontinuities. As a result, the performance of event-based corner detectors is limited. This paper proposes a general-purpose asynchronous non-maximum suppression pipeline (ANMS), and applies it to corner event detection. The proposed pipeline extract fine feature stream from the output of original detectors and adapts to the speed of motion. The ANMS runs directly on the asynchronous event stream with extremely low latency, which hardly affects the speed of original detectors. Additionally, we evaluate the DAVIS-based ground-truth labeling method to fill the gap between frame and event. Evaluation on public dataset indicates that the proposed ANMS pipeline significantly improves the performance of three classical asynchronous detectors with negligible latency. More importantly, the proposed ANMS framework is a natural extension of NMS, which is applicable to other asynchronous scoring tasks for event cameras.
Event Voxel Set Transformer for Spatiotemporal Representation Learning on Event Streams
Mar 07, 2023Event cameras are neuromorphic vision sensors representing visual information as sparse and asynchronous event streams. Most state-of-the-art event-based methods project events into dense frames and process them with conventional learning models. However, these approaches sacrifice the sparsity and high temporal resolution of event data, resulting in a large model size and high computational complexity. To fit the sparse nature of events and sufficiently explore their implicit relationship, we develop a novel attention-aware framework named Event Voxel Set Transformer (EVSTr) for spatiotemporal representation learning on event streams. It first converts the event stream into a voxel set and then hierarchically aggregates voxel features to obtain robust representations. The core of EVSTr is an event voxel transformer encoder to extract discriminative spatiotemporal features, which consists of two well-designed components, including a multi-scale neighbor embedding layer (MNEL) for local information aggregation and a voxel self-attention layer (VSAL) for global representation modeling. Enabling the framework to incorporate a long-term temporal structure, we introduce a segmental consensus strategy for modeling motion patterns over a sequence of segmented voxel sets. We evaluate the proposed framework on two event-based tasks: object classification and action recognition. Comprehensive experiments show that EVSTr achieves state-of-the-art performance while maintaining low model complexity. Additionally, we present a new dataset (NeuroHAR) recorded in challenging visual scenarios to address the lack of real-world event-based datasets for action recognition.
A Dynamic Graph CNN with Cross-Representation Distillation for Event-Based Recognition
Feb 08, 2023It is a popular solution to convert events into dense frame-based representations to use the well-pretrained CNNs in hand. Although with appealing performance, this line of work sacrifices the sparsity/temporal precision of events and usually necessitates heavy-weight models, thereby largely weakening the advantages and real-life application potential of event cameras. A more application-friendly way is to design deep graph models for learning sparse point-based representations from events. Yet, the efficacy of these graph models is far behind the frame-based counterpart with two key limitations: ($i$) simple graph construction strategies without carefully integrating the variant attributes (i.e., semantics, spatial and temporal coordinates) for each vertex, leading to biased graph representation; ($ii$) deficient learning because the lack of well pretraining models available. Here we solve the first problem by introducing a new event-based graph CNN (EDGCN), with a dynamic aggregation module to integrate all attributes of vertices adaptively. To alleviate the learning difficulty, we propose to leverage the dense representation counterpart of events as a cross-representation auxiliary to supply additional supervision and prior knowledge for the event graph. To this end, we form a frame-to-graph transfer learning framework with a customized hybrid distillation loss to well respect the varying cross-representation gaps across layers. Extensive experiments on multiple vision tasks validate the effectiveness and high generalization ability of our proposed model and distillation strategy (Core components of our codes are submitted with supplementary material and will be made publicly available upon acceptance)
Observability Analysis of Graph SLAM-Based Joint Calibration of Multiple Microphone Arrays and Sound Source Localization
Oct 11, 2022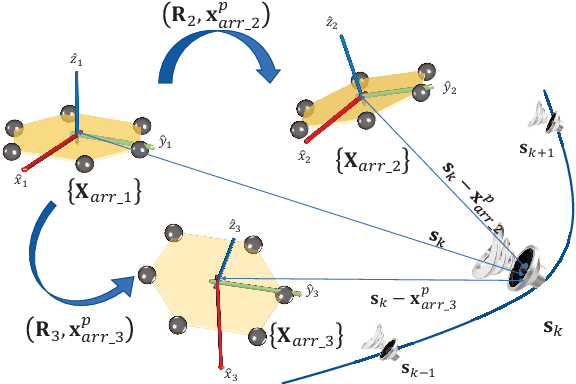
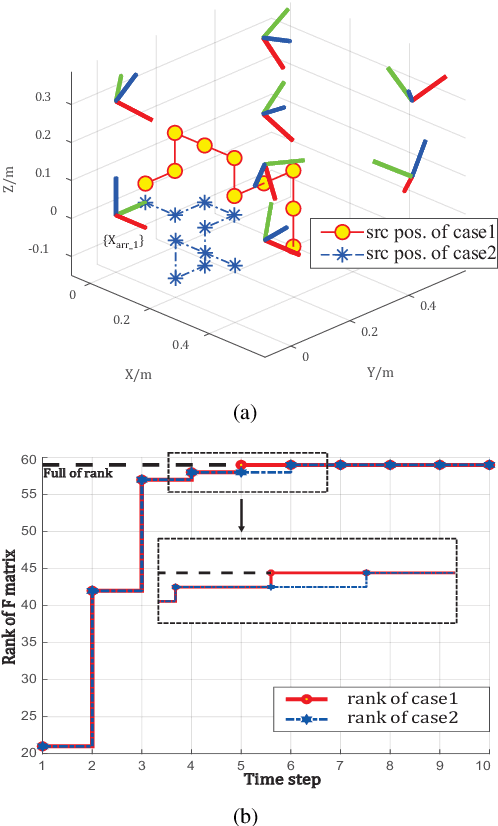
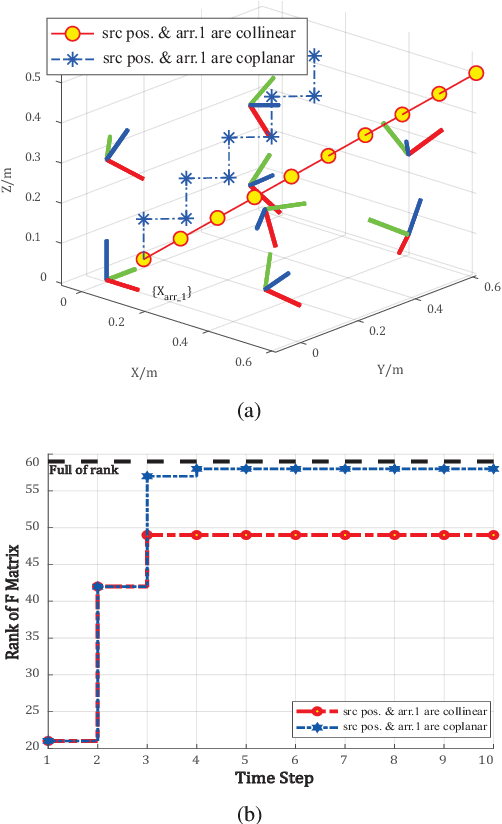
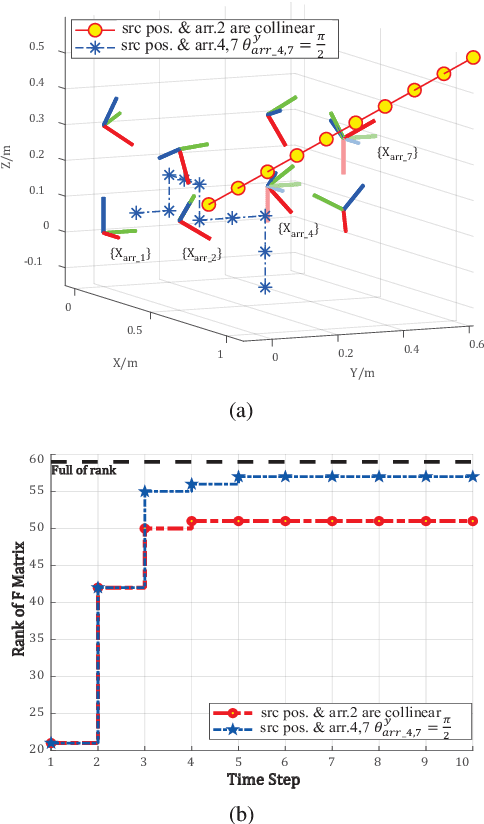
Multiple microphone arrays have many applications in robot audition, including sound source localization, audio scene perception and analysis, etc. However, accurate calibration of multiple microphone arrays remains a challenge because there are many unknown parameters to be identified, including the Euler angles, geometry, asynchronous factors between the microphone arrays. This paper is concerned with joint calibration of multiple microphone arrays and sound source localization using graph simultaneous localization and mapping (SLAM). By using a Fisher information matrix (FIM) approach, we focus on the observability analysis of the graph SLAM framework for the above-mentioned calibration problem. We thoroughly investigate the identifiability of the unknown parameters, including the Euler angles, geometry, asynchronous effects between the microphone arrays, and the sound source locations. We establish necessary/sufficient conditions under which the FIM and the Jacobian matrix have full column rank, which implies the identifiability of the unknown parameters. These conditions are closely related to the variation in the motion of the sound source and the configuration of microphone arrays, and have intuitive and physical interpretations. We also discover several scenarios where the unknown parameters are not uniquely identifiable. All theoretical findings are demonstrated using simulation data.
A Temporal Densely Connected Recurrent Network for Event-based Human Pose Estimation
Sep 15, 2022
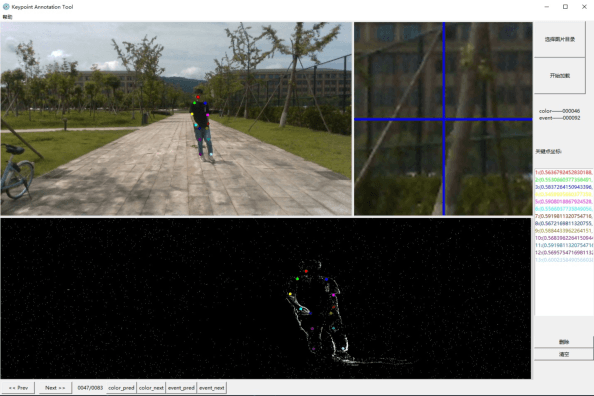

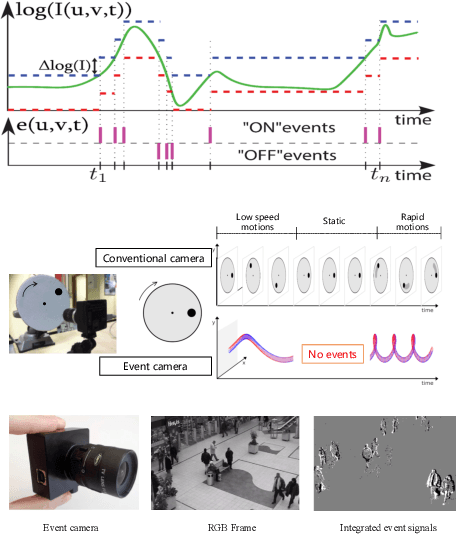
Event camera is an emerging bio-inspired vision sensors that report per-pixel brightness changes asynchronously. It holds noticeable advantage of high dynamic range, high speed response, and low power budget that enable it to best capture local motions in uncontrolled environments. This motivates us to unlock the potential of event cameras for human pose estimation, as the human pose estimation with event cameras is rarely explored. Due to the novel paradigm shift from conventional frame-based cameras, however, event signals in a time interval contain very limited information, as event cameras can only capture the moving body parts and ignores those static body parts, resulting in some parts to be incomplete or even disappeared in the time interval. This paper proposes a novel densely connected recurrent architecture to address the problem of incomplete information. By this recurrent architecture, we can explicitly model not only the sequential but also non-sequential geometric consistency across time steps to accumulate information from previous frames to recover the entire human bodies, achieving a stable and accurate human pose estimation from event data. Moreover, to better evaluate our model, we collect a large scale multimodal event-based dataset that comes with human pose annotations, which is by far the most challenging one to the best of our knowledge. The experimental results on two public datasets and our own dataset demonstrate the effectiveness and strength of our approach. Code can be available online for facilitating the future research.
EV-VGCNN: A Voxel Graph CNN for Event-based Object Classification
Jun 01, 2021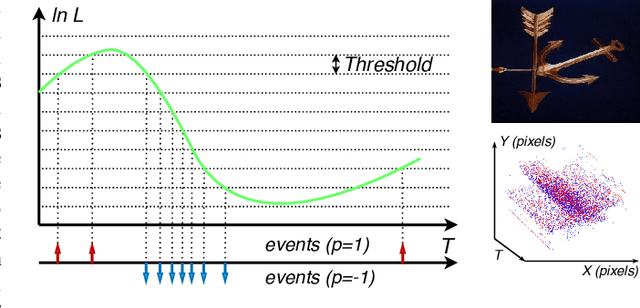
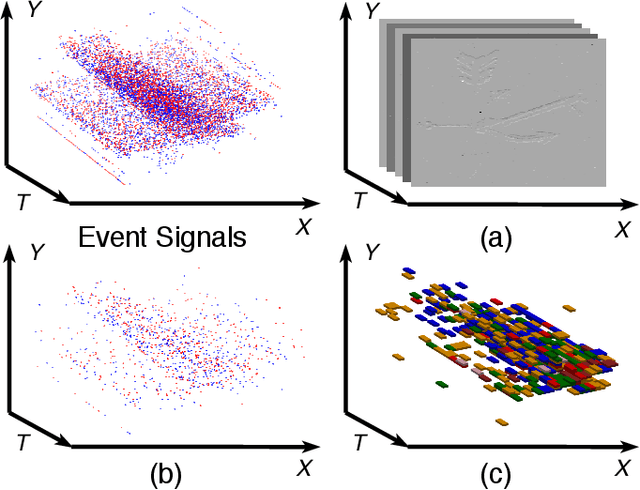
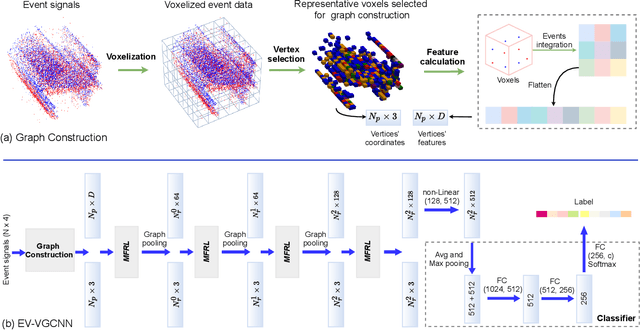
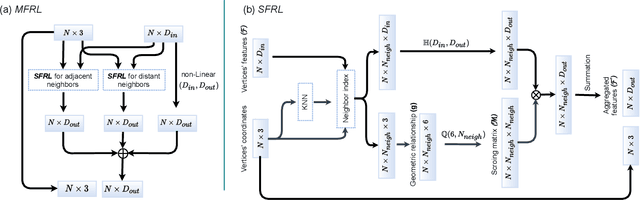
Event cameras report sparse intensity changes and hold noticeable advantages of low power consumption, high dynamic range, and high response speed for visual perception and understanding on portable devices. Event-based learning methods have recently achieved massive success on object recognition by integrating events into dense frame-based representations to apply traditional 2D learning algorithms. However, these approaches introduce much redundant information during the sparse-to-dense conversion and necessitate models with heavy-weight and large capacities, limiting the potential of event cameras on real-life applications. To address the core problem of balancing accuracy and model complexity for event-based classification models, we (1) construct graph representations for event data to utilize their sparsity nature better and design a lightweight end-to-end graph neural network (EV-VGCNN) for classification; (2) use voxel-wise vertices rather than traditional point-wise methods to incorporate the information from more points; (3) introduce a multi-scale feature relational layer (MFRL) to extract semantic and motion cues from each vertex adaptively concerning its distances to neighbors. Comprehensive experiments show that our approach advances state-of-the-art classification accuracy while achieving nearly 20 times parameter reduction (merely 0.84M parameters).