 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-based Video Frame Interpolation with Edge Guided Motion Refinement
Apr 28, 2024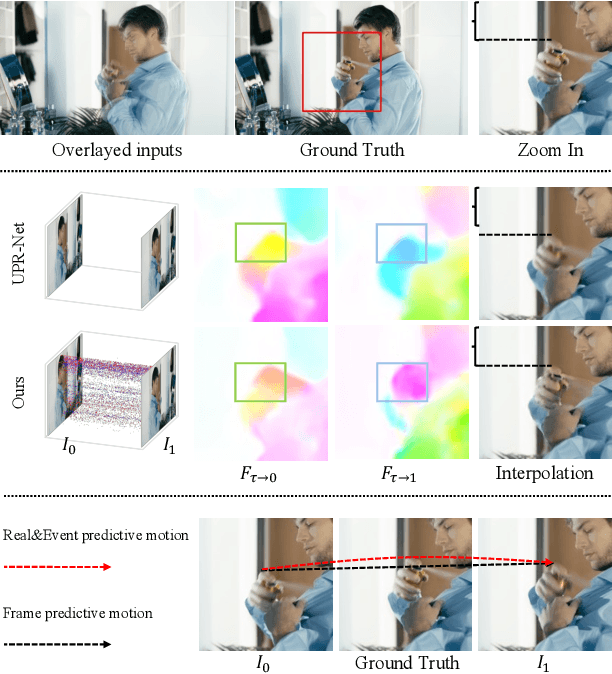

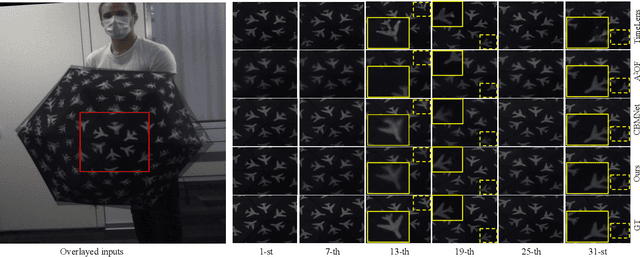

Video frame interpolation, the process of synthesizing intermediate frames between sequential video frames, has made remarkable progress with the use of event cameras. These sensors, with microsecond-level temporal resolution, fill information gaps between frames by providing precise motion cues. However, contemporary Event-Based Video Frame Interpolation (E-VFI) techniques often neglect the fact that event data primarily supply high-confidence features at scene edges during multi-modal feature fusion, thereby diminishing the role of event signals in optical flow (OF) estimation and warping refinement. To address this overlooked aspect, we introduce an end-to-end E-VFI learning method (referred to as EGMR) to efficiently utilize edge features from event signals for motion flow and warping enhancement. Our method incorporates an Edge Guided Attentive (EGA) module, which rectifies estimated video motion through attentive aggregation based on the local correlation of multi-modal features in a coarse-to-fine strategy. Moreover, given that event data can provide accurate visual references at scene edges between consecutive frames, we introduce a learned visibility map derived from event data to adaptively mitigate the occlusion problem in the warping refinement process. Extensive experiments on both synthetic and real datasets show the effectiveness of the proposed approach, demonstrating its potential for higher quality video frame interpolation.
Event Voxel Set Transformer for Spatiotemporal Representation Learning on Event Streams
Mar 07, 2023Event cameras are neuromorphic vision sensors representing visual information as sparse and asynchronous event streams. Most state-of-the-art event-based methods project events into dense frames and process them with conventional learning models. However, these approaches sacrifice the sparsity and high temporal resolution of event data, resulting in a large model size and high computational complexity. To fit the sparse nature of events and sufficiently explore their implicit relationship, we develop a novel attention-aware framework named Event Voxel Set Transformer (EVSTr) for spatiotemporal representation learning on event streams. It first converts the event stream into a voxel set and then hierarchically aggregates voxel features to obtain robust representations. The core of EVSTr is an event voxel transformer encoder to extract discriminative spatiotemporal features, which consists of two well-designed components, including a multi-scale neighbor embedding layer (MNEL) for local information aggregation and a voxel self-attention layer (VSAL) for global representation modeling. Enabling the framework to incorporate a long-term temporal structure, we introduce a segmental consensus strategy for modeling motion patterns over a sequence of segmented voxel sets. We evaluate the proposed framework on two event-based tasks: object classification and action recognition. Comprehensive experiments show that EVSTr achieves state-of-the-art performance while maintaining low model complexity. Additionally, we present a new dataset (NeuroHAR) recorded in challenging visual scenarios to address the lack of real-world event-based datasets for action recognition.
A Dynamic Graph CNN with Cross-Representation Distillation for Event-Based Recognition
Feb 08, 2023It is a popular solution to convert events into dense frame-based representations to use the well-pretrained CNNs in hand. Although with appealing performance, this line of work sacrifices the sparsity/temporal precision of events and usually necessitates heavy-weight models, thereby largely weakening the advantages and real-life application potential of event cameras. A more application-friendly way is to design deep graph models for learning sparse point-based representations from events. Yet, the efficacy of these graph models is far behind the frame-based counterpart with two key limitations: ($i$) simple graph construction strategies without carefully integrating the variant attributes (i.e., semantics, spatial and temporal coordinates) for each vertex, leading to biased graph representation; ($ii$) deficient learning because the lack of well pretraining models available. Here we solve the first problem by introducing a new event-based graph CNN (EDGCN), with a dynamic aggregation module to integrate all attributes of vertices adaptively. To alleviate the learning difficulty, we propose to leverage the dense representation counterpart of events as a cross-representation auxiliary to supply additional supervision and prior knowledge for the event graph. To this end, we form a frame-to-graph transfer learning framework with a customized hybrid distillation loss to well respect the varying cross-representation gaps across layers. Extensive experiments on multiple vision tasks validate the effectiveness and high generalization ability of our proposed model and distillation strategy (Core components of our codes are submitted with supplementary material and will be made publicly available upon acceptance)