 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Multimodal Learning through Label Space Reshaping
May 22, 2026Multimodal learning often suffers from modality imbalance, where modalities that converge faster dominate optimization while others remain undertrained. Existing approaches typically mitigate this issue by strengthening the weak modality or adjusting optimization gradients. However, such strategies mainly compensate for optimization rate discrepancies, often at the expense of the strong modality's optimization capacity, without analyzing how these discrepancies arise at the modality level. Based on theoretical insights and empirical observations, we argue that the discrepancy of learning pace arises from differences in the mapping difficulty between modality-specific feature space and the shared label space. To address this issue, we propose Balanced Multimodal Label Reshaping (BMLR), the first method that promotes multimodal balance from the label-side design. BMLR reshapes the cross-modal label space to equalize mapping difficulty across modalities, thereby facilitating modality interaction and injecting richer inter-class information into each modality. Extensive experiments across multiple architectures demonstrate that BMLR consistently improves multimodal performance and exhibits strong compatibility with diverse model designs. The source code will be released soon.
Improving Multimodal Learning Balance and Sufficiency through Data Remixing
Jun 16, 2025
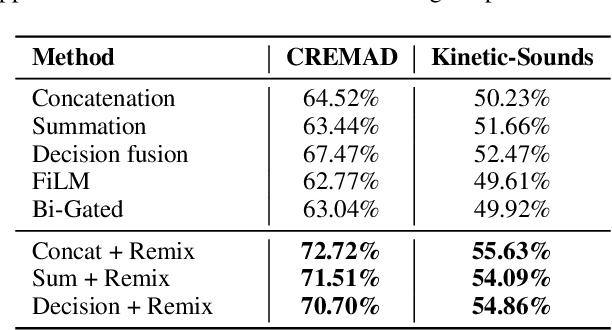


Different modalities hold considerable gaps in optimization trajectories, including speeds and paths, which lead to modality laziness and modality clash when jointly training multimodal models, resulting in insufficient and imbalanced multimodal learning. Existing methods focus on enforcing the weak modality by adding modality-specific optimization objectives, aligning their optimization speeds, or decomposing multimodal learning to enhance unimodal learning. These methods fail to achieve both unimodal sufficiency and multimodal balance. In this paper, we, for the first time, address both concerns by proposing multimodal Data Remixing, including decoupling multimodal data and filtering hard samples for each modality to mitigate modality imbalance; and then batch-level reassembling to align the gradient directions and avoid cross-modal interference, thus enhancing unimodal learning sufficiency. Experimental results demonstrate that our method can be seamlessly integrated with existing approaches, improving accuracy by approximately 6.50%$\uparrow$ on CREMAD and 3.41%$\uparrow$ on Kinetic-Sounds, without training set expansion or additional computational overhead during inference. The source code is available at https://github.com/MatthewMaxy/Remix_ICML2025.
Spatially-guided Temporal Aggregation for Robust Event-RGB Optical Flow Estimation
Jan 01, 2025



Current optical flow methods exploit the stable appearance of frame (or RGB) data to establish robust correspondences across time. Event cameras, on the other hand, provide high-temporal-resolution motion cues and excel in challenging scenarios. These complementary characteristics underscore the potential of integrating frame and event data for optical flow estimation. However, most cross-modal approaches fail to fully utilize the complementary advantages, relying instead on simply stacking information. This study introduces a novel approach that uses a spatially dense modality to guide the aggregation of the temporally dense event modality, achieving effective cross-modal fusion. Specifically, we propose an event-enhanced frame representation that preserves the rich texture of frames and the basic structure of events. We use the enhanced representation as the guiding modality and employ events to capture temporally dense motion information. The robust motion features derived from the guiding modality direct the aggregation of motion information from events. To further enhance fusion, we propose a transformer-based module that complements sparse event motion features with spatially rich frame information and enhances global information propagation. Additionally, a mix-fusion encoder is designed to extract comprehensive spatiotemporal contextual features from both modalities. Extensive experiments on the MVSEC and DSEC-Flow datasets demonstrate the effectiveness of our framework. Leveraging the complementary strengths of frames and events, our method achieves leading performance on the DSEC-Flow dataset. Compared to the event-only model, frame guidance improves accuracy by 10\%. Furthermore, it outperforms the state-of-the-art fusion-based method with a 4\% accuracy gain and a 45\% reduction in inference time.
ResFlow: Fine-tuning Residual Optical Flow for Event-based High Temporal Resolution Motion Estimation
Dec 12, 2024



Event cameras hold significant promise for high-temporal-resolution (HTR) motion estimation. However, estimating event-based HTR optical flow faces two key challenges: the absence of HTR ground-truth data and the intrinsic sparsity of event data. Most existing approaches rely on the flow accumulation paradigms to indirectly supervise intermediate flows, often resulting in accumulation errors and optimization difficulties. To address these challenges, we propose a residual-based paradigm for estimating HTR optical flow with event data. Our approach separates HTR flow estimation into two stages: global linear motion estimation and HTR residual flow refinement. The residual paradigm effectively mitigates the impacts of event sparsity on optimization and is compatible with any LTR algorithm. Next, to address the challenge posed by the absence of HTR ground truth, we incorporate novel learning strategies. Specifically, we initially employ a shared refiner to estimate the residual flows, enabling both LTR supervision and HTR inference. Subsequently, we introduce regional noise to simulate the residual patterns of intermediate flows, facilitating the adaptation from LTR supervision to HTR inference. Additionally, we show that the noise-based strategy supports in-domain self-supervised training. Comprehensive experimental results demonstrate that our approach achieves state-of-the-art accuracy in both LTR and HTR metrics, highlighting its effectiveness and superiority.
Prune and Repaint: Content-Aware Image Retargeting for any Ratio
Oct 30, 2024



Image retargeting is the task of adjusting the aspect ratio of images to suit different display devices or presentation environments. However, existing retargeting methods often struggle to balance the preservation of key semantics and image quality, resulting in either deformation or loss of important objects, or the introduction of local artifacts such as discontinuous pixels and inconsistent regenerated content. To address these issues, we propose a content-aware retargeting method called PruneRepaint. It incorporates semantic importance for each pixel to guide the identification of regions that need to be pruned or preserved in order to maintain key semantics. Additionally, we introduce an adaptive repainting module that selects image regions for repainting based on the distribution of pruned pixels and the proportion between foreground size and target aspect ratio, thus achieving local smoothness after pruning. By focusing on the content and structure of the foreground, our PruneRepaint approach adaptively avoids key content loss and deformation, while effectively mitigating artifacts with local repainting. We conduct experiments on the public RetargetMe benchmark and demonstrate through objective experimental results and subjective user studies that our method outperforms previous approaches in terms of preserving semantics and aesthetics, as well as better generalization across diverse aspect ratios. Codes will be available at https://github.com/fhshen2022/PruneRepaint.
EventAug: Multifaceted Spatio-Temporal Data Augmentation Methods for Event-based Learning
Sep 18, 2024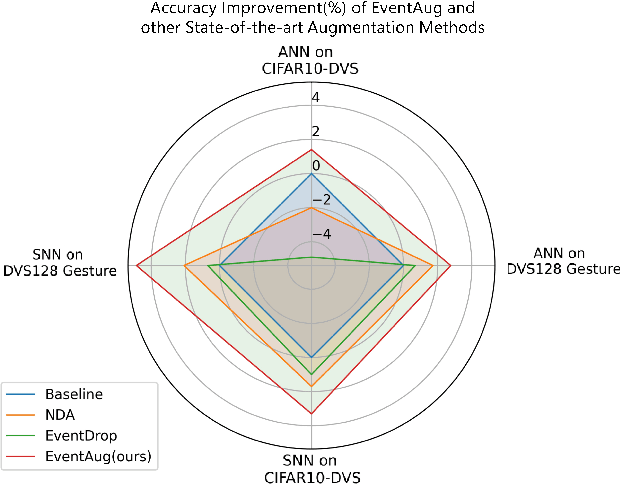
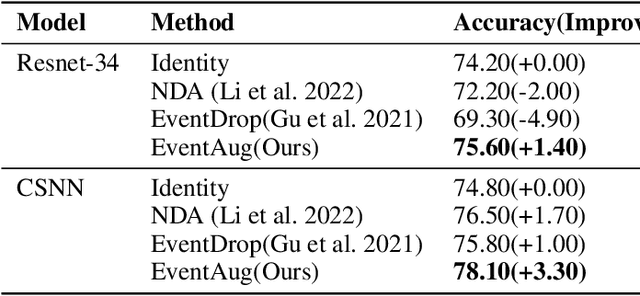
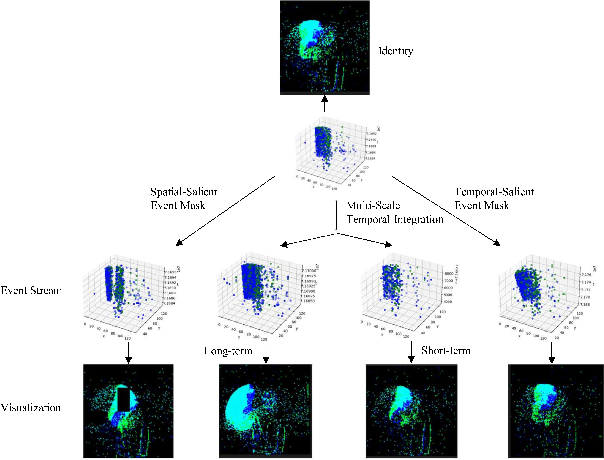
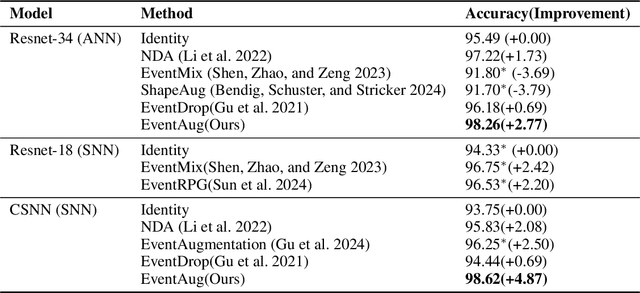
The event camera has demonstrated significant success across a wide range of areas due to its low time latency and high dynamic range. However, the community faces challenges such as data deficiency and limited diversity, often resulting in over-fitting and inadequate feature learning. Notably, the exploration of data augmentation techniques in the event community remains scarce. This work aims to address this gap by introducing a systematic augmentation scheme named EventAug to enrich spatial-temporal diversity. In particular, we first propose Multi-scale Temporal Integration (MSTI) to diversify the motion speed of objects, then introduce Spatial-salient Event Mask (SSEM) and Temporal-salient Event Mask (TSEM) to enrich object variants. Our EventAug can facilitate models learning with richer motion patterns, object variants and local spatio-temporal relations, thus improving model robustness to varied moving speeds, occlusions, and action disruptions. Experiment results show that our augmentation method consistently yields significant improvements across different tasks and backbones (e.g., a 4.87% accuracy gain on DVS128 Gesture). Our code will be publicly available for this community.
Event-based Video Frame Interpolation with Edge Guided Motion Refinement
Apr 28, 2024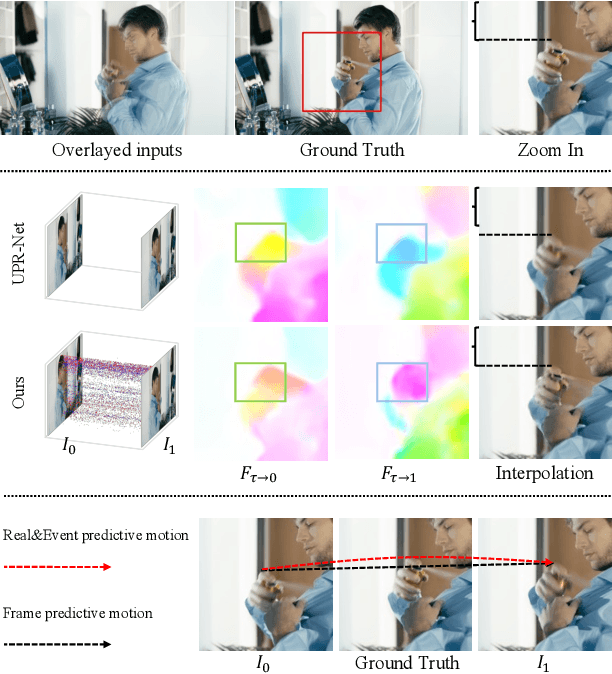

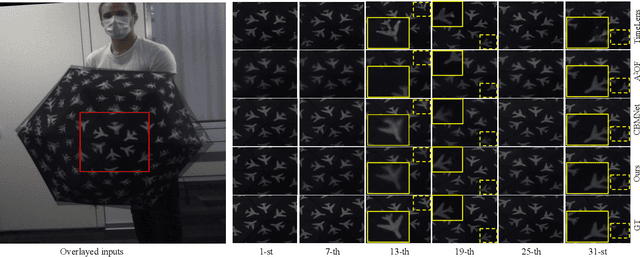

Video frame interpolation, the process of synthesizing intermediate frames between sequential video frames, has made remarkable progress with the use of event cameras. These sensors, with microsecond-level temporal resolution, fill information gaps between frames by providing precise motion cues. However, contemporary Event-Based Video Frame Interpolation (E-VFI) techniques often neglect the fact that event data primarily supply high-confidence features at scene edges during multi-modal feature fusion, thereby diminishing the role of event signals in optical flow (OF) estimation and warping refinement. To address this overlooked aspect, we introduce an end-to-end E-VFI learning method (referred to as EGMR) to efficiently utilize edge features from event signals for motion flow and warping enhancement. Our method incorporates an Edge Guided Attentive (EGA) module, which rectifies estimated video motion through attentive aggregation based on the local correlation of multi-modal features in a coarse-to-fine strategy. Moreover, given that event data can provide accurate visual references at scene edges between consecutive frames, we introduce a learned visibility map derived from event data to adaptively mitigate the occlusion problem in the warping refinement process. Extensive experiments on both synthetic and real datasets show the effectiveness of the proposed approach, demonstrating its potential for higher quality video frame interpolation.
Data-efficient Event Camera Pre-training via Disentangled Masked Modeling
Mar 01, 2024In this paper, we present a new data-efficient voxel-based self-supervised learning method for event cameras. Our pre-training overcomes the limitations of previous methods, which either sacrifice temporal information by converting event sequences into 2D images for utilizing pre-trained image models or directly employ paired image data for knowledge distillation to enhance the learning of event streams. In order to make our pre-training data-efficient, we first design a semantic-uniform masking method to address the learning imbalance caused by the varying reconstruction difficulties of different regions in non-uniform data when using random masking. In addition, we ease the traditional hybrid masked modeling process by explicitly decomposing it into two branches, namely local spatio-temporal reconstruction and global semantic reconstruction to encourage the encoder to capture local correlations and global semantics, respectively. This decomposition allows our selfsupervised learning method to converge faster with minimal pre-training data. Compared to previous approaches, our self-supervised learning method does not rely on paired RGB images, yet enables simultaneous exploration of spatial and temporal cues in multiple scales. It exhibits excellent generalization performance and demonstrates significant improvements across various tasks with fewer parameters and lower computational costs.
Interpretation on Multi-modal Visual Fusion
Aug 19, 2023In this paper, we present an analytical framework and a novel metric to shed light on the interpretation of the multimodal vision community. Our approach involves measuring the proposed semantic variance and feature similarity across modalities and levels, and conducting semantic and quantitative analyses through comprehensive experiments. Specifically, we investigate the consistency and speciality of representations across modalities, evolution rules within each modality, and the collaboration logic used when optimizing a multi-modality model. Our studies reveal several important findings, such as the discrepancy in cross-modal features and the hybrid multi-modal cooperation rule, which highlights consistency and speciality simultaneously for complementary inference. Through our dissection and findings on multi-modal fusion, we facilitate a rethinking of the reasonability and necessity of popular multi-modal vision fusion strategies. Furthermore, our work lays the foundation for designing a trustworthy and universal multi-modal fusion model for a variety of tasks in the future.
Event Voxel Set Transformer for Spatiotemporal Representation Learning on Event Streams
Mar 07, 2023Event cameras are neuromorphic vision sensors representing visual information as sparse and asynchronous event streams. Most state-of-the-art event-based methods project events into dense frames and process them with conventional learning models. However, these approaches sacrifice the sparsity and high temporal resolution of event data, resulting in a large model size and high computational complexity. To fit the sparse nature of events and sufficiently explore their implicit relationship, we develop a novel attention-aware framework named Event Voxel Set Transformer (EVSTr) for spatiotemporal representation learning on event streams. It first converts the event stream into a voxel set and then hierarchically aggregates voxel features to obtain robust representations. The core of EVSTr is an event voxel transformer encoder to extract discriminative spatiotemporal features, which consists of two well-designed components, including a multi-scale neighbor embedding layer (MNEL) for local information aggregation and a voxel self-attention layer (VSAL) for global representation modeling. Enabling the framework to incorporate a long-term temporal structure, we introduce a segmental consensus strategy for modeling motion patterns over a sequence of segmented voxel sets. We evaluate the proposed framework on two event-based tasks: object classification and action recognition. Comprehensive experiments show that EVSTr achieves state-of-the-art performance while maintaining low model complexity. Additionally, we present a new dataset (NeuroHAR) recorded in challenging visual scenarios to address the lack of real-world event-based datasets for action recognition.