 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect Smarter, Not More: Prompt-Aware Evaluation Scheduling with Submodular Guarantees
Apr 13, 2026Automatic prompt optimization (APO) hinges on the quality of its evaluation signal, yet scoring every prompt candidate on the full training set is prohibitively expensive. Existing methods either fix a single evaluation subset before optimization begins (principled but prompt-agnostic) or adapt it heuristically during optimization (flexible but unstable and lacking formal guarantees). We observe that APO naturally maps to an online adaptive testing problem: prompts are examinees, training examples are test items, and the scheduler should select items that best discriminate among the strongest candidates. This insight motivates Prompt-Aware Online Evaluation Scheduling (POES), which integrates an IRT-based discrimination utility, a facility-location coverage term, and switching-cost-aware warm-start swaps into a unified objective that is provably monotone submodular, yielding a (1-1/e) greedy guarantee for cold starts and bounded drift for warm-start updates. An adaptive controller modulates the exploration-exploitation balance based on optimization progress. Across 36 tasks spanning three benchmark families, POES achieves the highest overall average accuracy (6.2 percent improvement over the best baseline) with negligible token overhead (approximately 4 percent) at the same evaluation budget. Moreover, principled selection at k = 20 examples matches or exceeds the performance of naive evaluation at k = 30-50, reducing token consumption by 35-60 percent, showing that selecting smarter is more effective than selecting more. Our results demonstrate that evaluation scheduling is a first-class component of APO, not an implementation detail.
Advances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
Challenges and Research Directions for Large Language Model Inference Hardware
Jan 08, 2026Large Language Model (LLM) inference is hard. The autoregressive Decode phase of the underlying Transformer model makes LLM inference fundamentally different from training. Exacerbated by recent AI trends, the primary challenges are memory and interconnect rather than compute. To address these challenges, we highlight four architecture research opportunities: High Bandwidth Flash for 10X memory capacity with HBM-like bandwidth; Processing-Near-Memory and 3D memory-logic stacking for high memory bandwidth; and low-latency interconnect to speedup communication. While our focus is datacenter AI, we also review their applicability for mobile devices.
BLURR: A Boosted Low-Resource Inference for Vision-Language-Action Models
Dec 12, 2025Vision-language-action (VLA) models enable impressive zero shot manipulation, but their inference stacks are often too heavy for responsive web demos or high frequency robot control on commodity GPUs. We present BLURR, a lightweight inference wrapper that can be plugged into existing VLA controllers without retraining or changing model checkpoints. Instantiated on the pi-zero VLA controller, BLURR keeps the original observation interfaces and accelerates control by combining an instruction prefix key value cache, mixed precision execution, and a single step rollout schedule that reduces per step computation. In our SimplerEnv based evaluation, BLURR maintains task success rates comparable to the original controller while significantly lowering effective FLOPs and wall clock latency. We also build an interactive web demo that allows users to switch between controllers and toggle inference options in real time while watching manipulation episodes. This highlights BLURR as a practical approach for deploying modern VLA policies under tight compute budgets.
Revisit Modality Imbalance at the Decision Layer
Oct 16, 2025Multimodal learning integrates information from different modalities to enhance model performance, yet it often suffers from modality imbalance, where dominant modalities overshadow weaker ones during joint optimization. This paper reveals that such an imbalance not only occurs during representation learning but also manifests significantly at the decision layer. Experiments on audio-visual datasets (CREMAD and Kinetic-Sounds) show that even after extensive pretraining and balanced optimization, models still exhibit systematic bias toward certain modalities, such as audio. Further analysis demonstrates that this bias originates from intrinsic disparities in feature-space and decision-weight distributions rather than from optimization dynamics alone. We argue that aggregating uncalibrated modality outputs at the fusion stage leads to biased decision-layer weighting, hindering weaker modalities from contributing effectively. To address this, we propose that future multimodal systems should focus more on incorporate adaptive weight allocation mechanisms at the decision layer, enabling relative balanced according to the capabilities of each modality.
Improving Multimodal Learning Balance and Sufficiency through Data Remixing
Jun 16, 2025
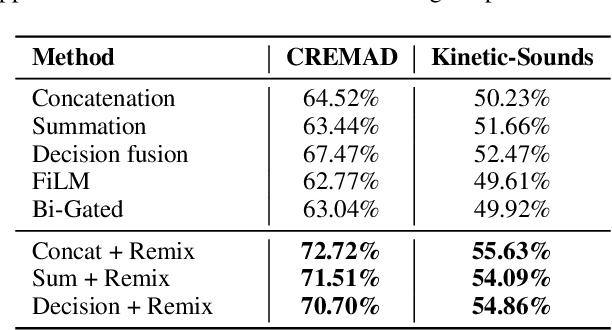


Different modalities hold considerable gaps in optimization trajectories, including speeds and paths, which lead to modality laziness and modality clash when jointly training multimodal models, resulting in insufficient and imbalanced multimodal learning. Existing methods focus on enforcing the weak modality by adding modality-specific optimization objectives, aligning their optimization speeds, or decomposing multimodal learning to enhance unimodal learning. These methods fail to achieve both unimodal sufficiency and multimodal balance. In this paper, we, for the first time, address both concerns by proposing multimodal Data Remixing, including decoupling multimodal data and filtering hard samples for each modality to mitigate modality imbalance; and then batch-level reassembling to align the gradient directions and avoid cross-modal interference, thus enhancing unimodal learning sufficiency. Experimental results demonstrate that our method can be seamlessly integrated with existing approaches, improving accuracy by approximately 6.50%$\uparrow$ on CREMAD and 3.41%$\uparrow$ on Kinetic-Sounds, without training set expansion or additional computational overhead during inference. The source code is available at https://github.com/MatthewMaxy/Remix_ICML2025.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Training a neural netwok for data reduction and better generalization
Nov 26, 2024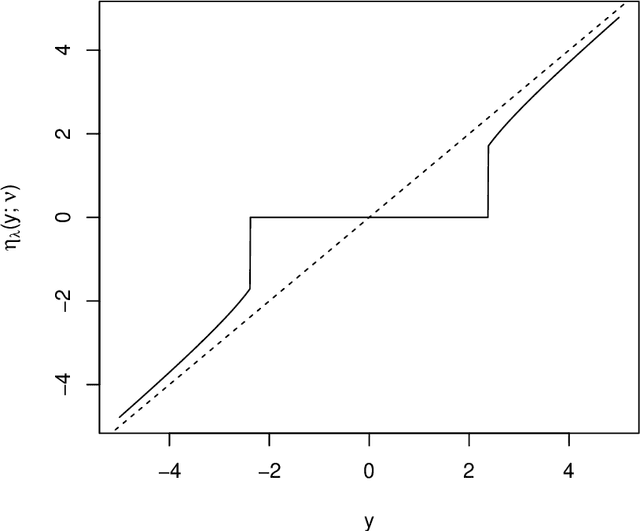

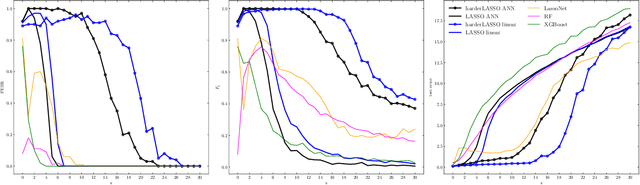
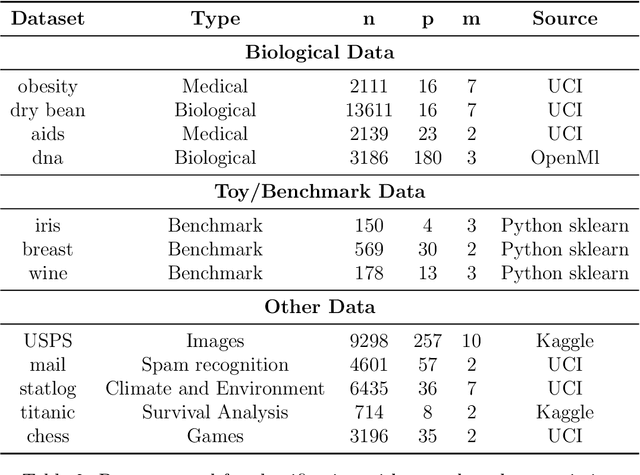
The motivation for sparse learners is to compress the inputs (features) by selecting only the ones needed for good generalization. Linear models with LASSO-type regularization achieve this by setting the weights of irrelevant features to zero, effectively identifying and ignoring them. In artificial neural networks, this selective focus can be achieved by pruning the input layer. Given a cost function enhanced with a sparsity-promoting penalty, our proposal selects a regularization term $\lambda$ (without the use of cross-validation or a validation set) that creates a local minimum in the cost function at the origin where no features are selected. This local minimum acts as a baseline, meaning that if there is no strong enough signal to justify a feature inclusion, the local minimum remains at zero with a high prescribed probability. The method is flexible, applying to complex models ranging from shallow to deep artificial neural networks and supporting various cost functions and sparsity-promoting penalties. We empirically show a remarkable phase transition in the probability of retrieving the relevant features, as well as good generalization thanks to the choice of $\lambda$, the non-convex penalty and the optimization scheme developed. This approach can be seen as a form of compressed sensing for complex models, allowing us to distill high-dimensional data into a compact, interpretable subset of meaningful features.
TJDR: A High-Quality Diabetic Retinopathy Pixel-Level Annotation Dataset
Dec 24, 2023Diabetic retinopathy (DR), as a debilitating ocular complication, necessitates prompt intervention and treatment. Despite the effectiveness of artificial intelligence in aiding DR grading, the progression of research toward enhancing the interpretability of DR grading through precise lesion segmentation faces a severe hindrance due to the scarcity of pixel-level annotated DR datasets. To mitigate this, this paper presents and delineates TJDR, a high-quality DR pixel-level annotation dataset, which comprises 561 color fundus images sourced from the Tongji Hospital Affiliated to Tongji University. These images are captured using diverse fundus cameras including Topcon's TRC-50DX and Zeiss CLARUS 500, exhibit high resolution. For the sake of adhering strictly to principles of data privacy, the private information of images is meticulously removed while ensuring clarity in displaying anatomical structures such as the optic disc, retinal blood vessels, and macular fovea. The DR lesions are annotated using the Labelme tool, encompassing four prevalent DR lesions: Hard Exudates (EX), Hemorrhages (HE), Microaneurysms (MA), and Soft Exudates (SE), labeled respectively from 1 to 4, with 0 representing the background. Significantly, experienced ophthalmologists conduct the annotation work with rigorous quality assurance, culminating in the construction of this dataset. This dataset has been partitioned into training and testing sets and publicly released to contribute to advancements in the DR lesion segmentation research community.
Flexible and efficient spatial extremes emulation via variational autoencoders
Jul 16, 2023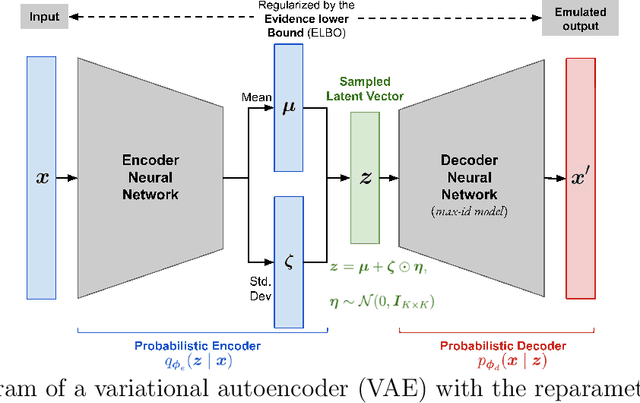
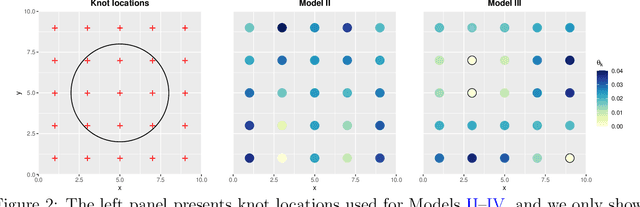
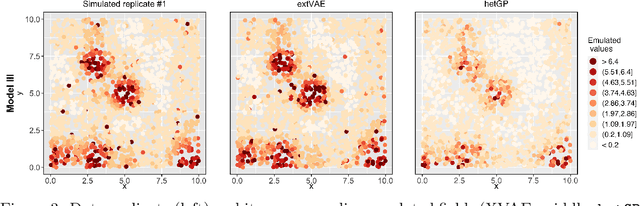
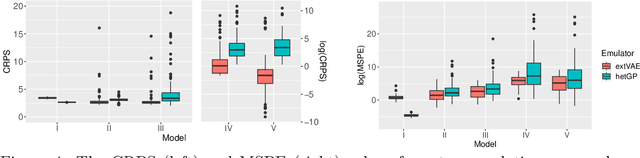
Many real-world processes have complex tail dependence structures that cannot be characterized using classical Gaussian processes. More flexible spatial extremes models such as Gaussian scale mixtures and single-station conditioning models exhibit appealing extremal dependence properties but are often exceedingly prohibitive to fit and simulate from. In this paper, we develop a new spatial extremes model that has flexible and non-stationary dependence properties, and we integrate it in the encoding-decoding structure of a variational autoencoder (extVAE). The extVAE can be used as a spatio-temporal emulator that characterizes the distribution of potential mechanistic model output states and produces outputs that have the same properties as the inputs, especially in the tail. Through extensive simulation studies, we show that our extVAE is vastly more time-efficient than traditional Bayesian inference while also outperforming many spatial extremes models with a stationary dependence structure. To further demonstrate the computational power of the extVAE, we analyze a high-resolution satellite-derived dataset of sea surface temperature in the Red Sea, which includes daily measurements at 16703 grid cells.