 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoogle Neural Network Models for Edge Devices: Analyzing and Mitigating Machine Learning Inference Bottlenecks
Sep 29, 2021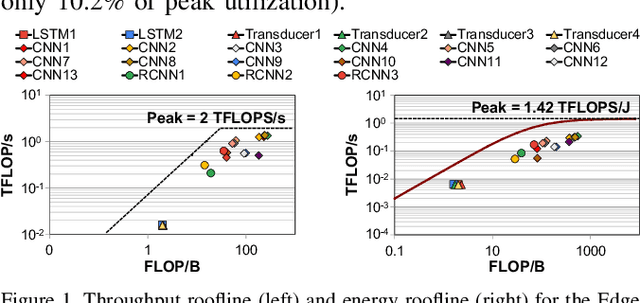
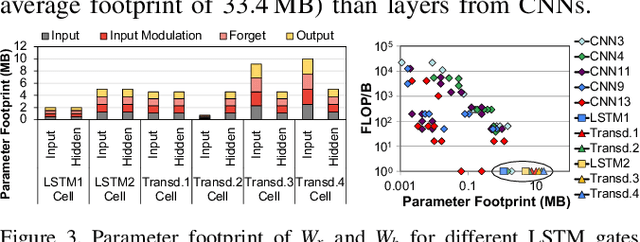
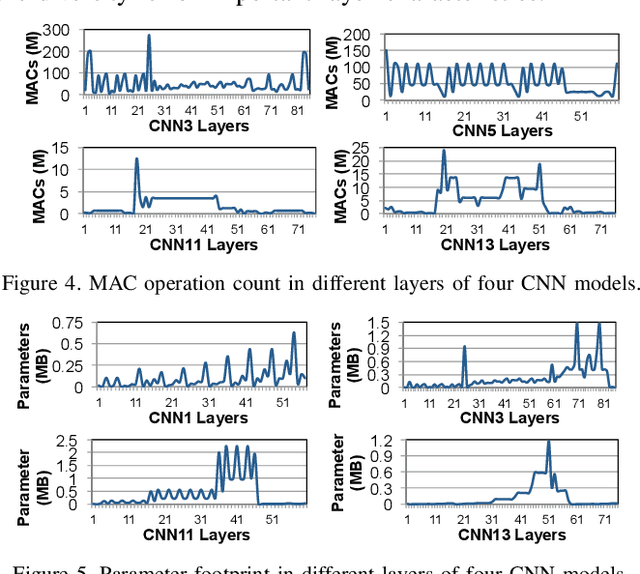
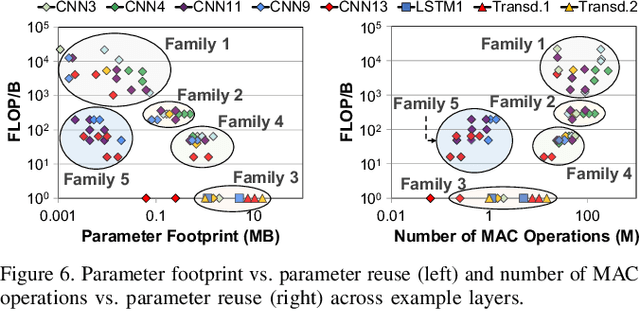
Emerging edge computing platforms often contain machine learning (ML) accelerators that can accelerate inference for a wide range of neural network (NN) models. These models are designed to fit within the limited area and energy constraints of the edge computing platforms, each targeting various applications (e.g., face detection, speech recognition, translation, image captioning, video analytics). To understand how edge ML accelerators perform, we characterize the performance of a commercial Google Edge TPU, using 24 Google edge NN models (which span a wide range of NN model types) and analyzing each NN layer within each model. We find that the Edge TPU suffers from three major shortcomings: (1) it operates significantly below peak computational throughput, (2) it operates significantly below its theoretical energy efficiency, and (3) its memory system is a large energy and performance bottleneck. Our characterization reveals that the one-size-fits-all, monolithic design of the Edge TPU ignores the high degree of heterogeneity both across different NN models and across different NN layers within the same NN model, leading to the shortcomings we observe. We propose a new acceleration framework called Mensa. Mensa incorporates multiple heterogeneous edge ML accelerators (including both on-chip and near-data accelerators), each of which caters to the characteristics of a particular subset of NN models and layers. During NN inference, for each NN layer, Mensa decides which accelerator to schedule the layer on, taking into account both the optimality of each accelerator for the layer and layer-to-layer communication costs. Averaged across all 24 Google edge NN models, Mensa improves energy efficiency and throughput by 3.0x and 3.1x over the Edge TPU, and by 2.4x and 4.3x over Eyeriss~v2, a state-of-the-art accelerator.
Mitigating Edge Machine Learning Inference Bottlenecks: An Empirical Study on Accelerating Google Edge Models
Mar 01, 2021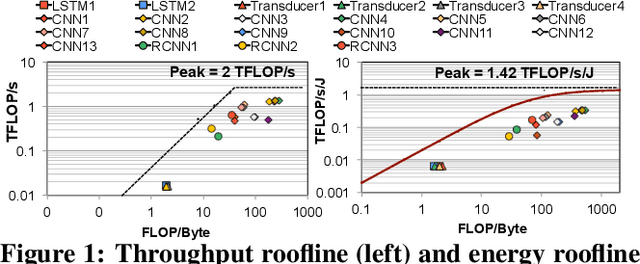
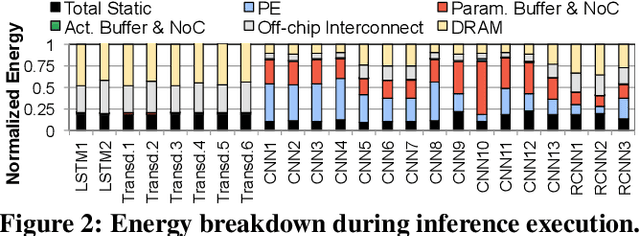
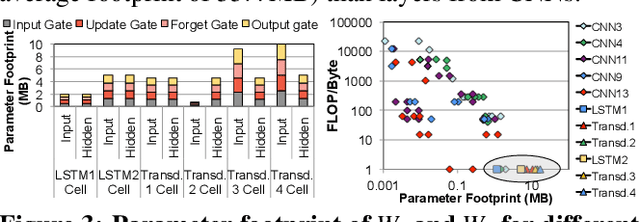
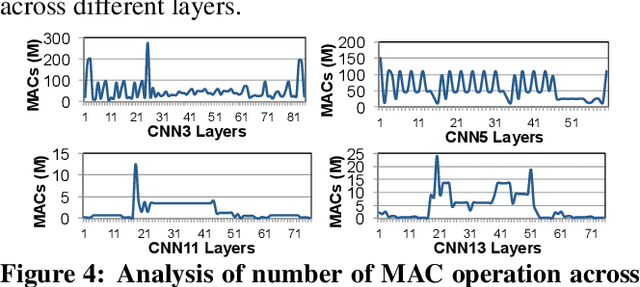
As the need for edge computing grows, many modern consumer devices now contain edge machine learning (ML) accelerators that can compute a wide range of neural network (NN) models while still fitting within tight resource constraints. We analyze a commercial Edge TPU using 24 Google edge NN models (including CNNs, LSTMs, transducers, and RCNNs), and find that the accelerator suffers from three shortcomings, in terms of computational throughput, energy efficiency, and memory access handling. We comprehensively study the characteristics of each NN layer in all of the Google edge models, and find that these shortcomings arise from the one-size-fits-all approach of the accelerator, as there is a high amount of heterogeneity in key layer characteristics both across different models and across different layers in the same model. We propose a new acceleration framework called Mensa. Mensa incorporates multiple heterogeneous ML edge accelerators (including both on-chip and near-data accelerators), each of which caters to the characteristics of a particular subset of models. At runtime, Mensa schedules each layer to run on the best-suited accelerator, accounting for both efficiency and inter-layer dependencies. As we analyze the Google edge NN models, we discover that all of the layers naturally group into a small number of clusters, which allows us to design an efficient implementation of Mensa for these models with only three specialized accelerators. Averaged across all 24 Google edge models, Mensa improves energy efficiency and throughput by 3.0x and 3.1x over the Edge TPU, and by 2.4x and 4.3x over Eyeriss v2, a state-of-the-art accelerator.
An Evaluation of Edge TPU Accelerators for Convolutional Neural Networks
Feb 20, 2021


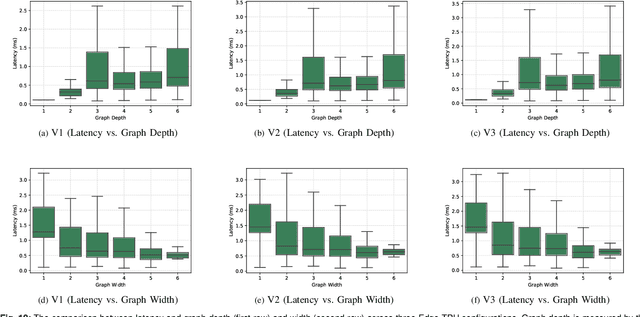
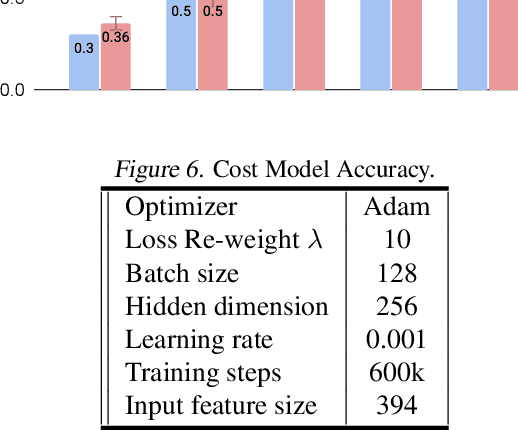
Edge TPUs are a domain of accelerators for low-power, edge devices and are widely used in various Google products such as Coral and Pixel devices. In this paper, we first discuss the major microarchitectural details of Edge TPUs. Then, we extensively evaluate three classes of Edge TPUs, covering different computing ecosystems, that are either currently deployed in Google products or are the product pipeline, across 423K unique convolutional neural networks. Building upon this extensive study, we discuss critical and interpretable microarchitectural insights about the studied classes of Edge TPUs. Mainly, we discuss how Edge TPU accelerators perform across convolutional neural networks with different structures. Finally, we present our ongoing efforts in developing high-accuracy learned machine learning models to estimate the major performance metrics of accelerators such as latency and energy consumption. These learned models enable significantly faster (in the order of milliseconds) evaluations of accelerators as an alternative to time-consuming cycle-accurate simulators and establish an exciting opportunity for rapid hard-ware/software co-design.
Rethinking Co-design of Neural Architectures and Hardware Accelerators
Feb 17, 2021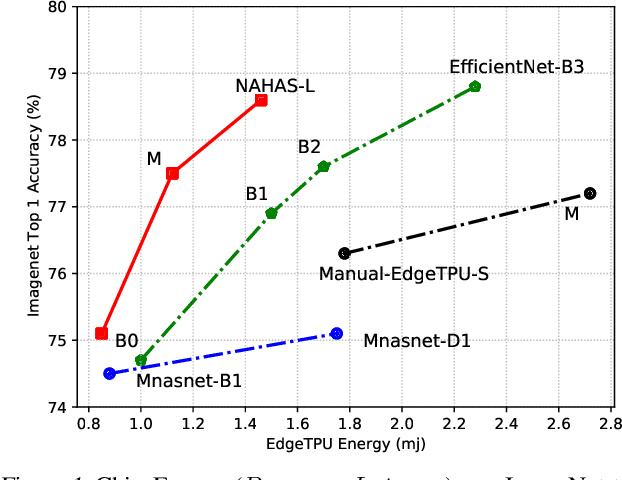
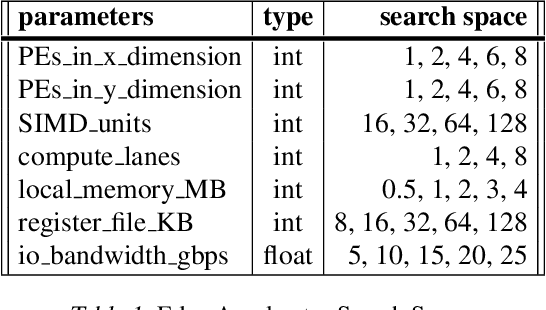
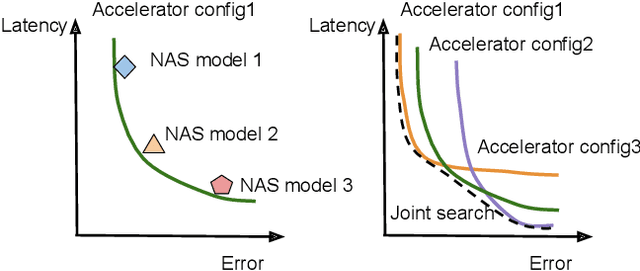
Neural architectures and hardware accelerators have been two driving forces for the progress in deep learning. Previous works typically attempt to optimize hardware given a fixed model architecture or model architecture given fixed hardware. And the dominant hardware architecture explored in this prior work is FPGAs. In our work, we target the optimization of hardware and software configurations on an industry-standard edge accelerator. We systematically study the importance and strategies of co-designing neural architectures and hardware accelerators. We make three observations: 1) the software search space has to be customized to fully leverage the targeted hardware architecture, 2) the search for the model architecture and hardware architecture should be done jointly to achieve the best of both worlds, and 3) different use cases lead to very different search outcomes. Our experiments show that the joint search method consistently outperforms previous platform-aware neural architecture search, manually crafted models, and the state-of-the-art EfficientNet on all latency targets by around 1% on ImageNet top-1 accuracy. Our method can reduce energy consumption of an edge accelerator by up to 2x under the same accuracy constraint, when co-adapting the model architecture and hardware accelerator configurations.
Apollo: Transferable Architecture Exploration
Feb 02, 2021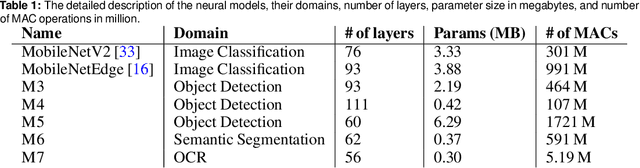
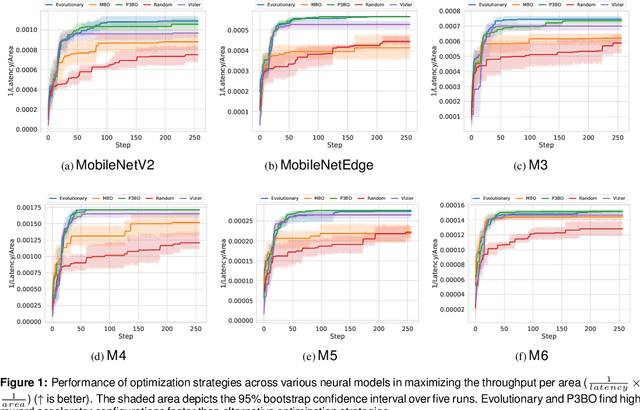

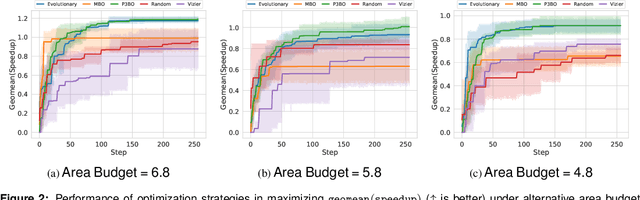
The looming end of Moore's Law and ascending use of deep learning drives the design of custom accelerators that are optimized for specific neural architectures. Architecture exploration for such accelerators forms a challenging constrained optimization problem over a complex, high-dimensional, and structured input space with a costly to evaluate objective function. Existing approaches for accelerator design are sample-inefficient and do not transfer knowledge between related optimizations tasks with different design constraints, such as area and/or latency budget, or neural architecture configurations. In this work, we propose a transferable architecture exploration framework, dubbed Apollo, that leverages recent advances in black-box function optimization for sample-efficient accelerator design. We use this framework to optimize accelerator configurations of a diverse set of neural architectures with alternative design constraints. We show that our framework finds high reward design configurations (up to 24.6% speedup) more sample-efficiently than a baseline black-box optimization approach. We further show that by transferring knowledge between target architectures with different design constraints, Apollo is able to find optimal configurations faster and often with better objective value (up to 25% improvements). This encouraging outcome portrays a promising path forward to facilitate generating higher quality accelerators.