 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeCafNet: Delegate and Conquer for Efficient Temporal Grounding in Long Videos
May 22, 2025Long Video Temporal Grounding (LVTG) aims at identifying specific moments within lengthy videos based on user-provided text queries for effective content retrieval. The approach taken by existing methods of dividing video into clips and processing each clip via a full-scale expert encoder is challenging to scale due to prohibitive computational costs of processing a large number of clips in long videos. To address this issue, we introduce DeCafNet, an approach employing ``delegate-and-conquer'' strategy to achieve computation efficiency without sacrificing grounding performance. DeCafNet introduces a sidekick encoder that performs dense feature extraction over all video clips in a resource-efficient manner, while generating a saliency map to identify the most relevant clips for full processing by the expert encoder. To effectively leverage features from sidekick and expert encoders that exist at different temporal resolutions, we introduce DeCaf-Grounder, which unifies and refines them via query-aware temporal aggregation and multi-scale temporal refinement for accurate grounding. Experiments on two LTVG benchmark datasets demonstrate that DeCafNet reduces computation by up to 47\% while still outperforming existing methods, establishing a new state-of-the-art for LTVG in terms of both efficiency and performance. Our code is available at https://github.com/ZijiaLewisLu/CVPR2025-DeCafNet.
Hummingbird: High Fidelity Image Generation via Multimodal Context Alignment
Feb 07, 2025



While diffusion models are powerful in generating high-quality, diverse synthetic data for object-centric tasks, existing methods struggle with scene-aware tasks such as Visual Question Answering (VQA) and Human-Object Interaction (HOI) Reasoning, where it is critical to preserve scene attributes in generated images consistent with a multimodal context, i.e. a reference image with accompanying text guidance query. To address this, we introduce Hummingbird, the first diffusion-based image generator which, given a multimodal context, generates highly diverse images w.r.t. the reference image while ensuring high fidelity by accurately preserving scene attributes, such as object interactions and spatial relationships from the text guidance. Hummingbird employs a novel Multimodal Context Evaluator that simultaneously optimizes our formulated Global Semantic and Fine-grained Consistency Rewards to ensure generated images preserve the scene attributes of reference images in relation to the text guidance while maintaining diversity. As the first model to address the task of maintaining both diversity and fidelity given a multimodal context, we introduce a new benchmark formulation incorporating MME Perception and Bongard HOI datasets. Benchmark experiments show Hummingbird outperforms all existing methods by achieving superior fidelity while maintaining diversity, validating Hummingbird's potential as a robust multimodal context-aligned image generator in complex visual tasks.
Revisiting Multi-Scale Feature Fusion for Semantic Segmentation
Mar 23, 2022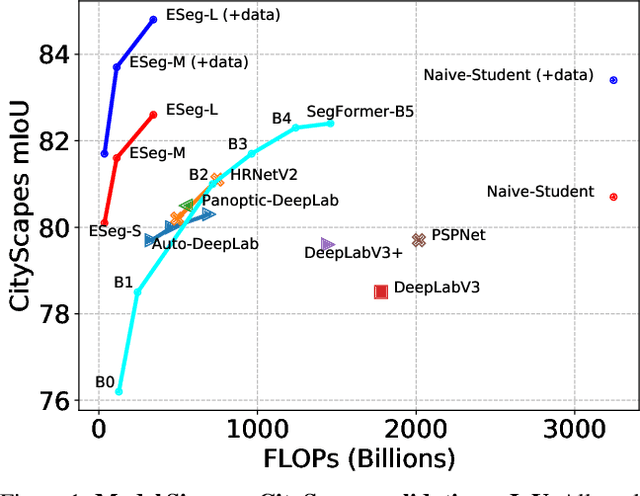

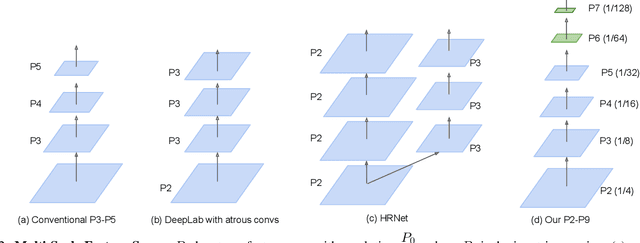
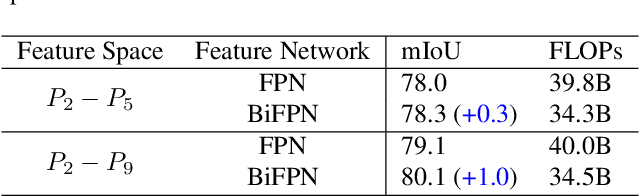
It is commonly believed that high internal resolution combined with expensive operations (e.g. atrous convolutions) are necessary for accurate semantic segmentation, resulting in slow speed and large memory usage. In this paper, we question this belief and demonstrate that neither high internal resolution nor atrous convolutions are necessary. Our intuition is that although segmentation is a dense per-pixel prediction task, the semantics of each pixel often depend on both nearby neighbors and far-away context; therefore, a more powerful multi-scale feature fusion network plays a critical role. Following this intuition, we revisit the conventional multi-scale feature space (typically capped at P5) and extend it to a much richer space, up to P9, where the smallest features are only 1/512 of the input size and thus have very large receptive fields. To process such a rich feature space, we leverage the recent BiFPN to fuse the multi-scale features. Based on these insights, we develop a simplified segmentation model, named ESeg, which has neither high internal resolution nor expensive atrous convolutions. Perhaps surprisingly, our simple method can achieve better accuracy with faster speed than prior art across multiple datasets. In real-time settings, ESeg-Lite-S achieves 76.0% mIoU on CityScapes [12] at 189 FPS, outperforming FasterSeg [9] (73.1% mIoU at 170 FPS). Our ESeg-Lite-L runs at 79 FPS and achieves 80.1% mIoU, largely closing the gap between real-time and high-performance segmentation models.
DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
Mar 15, 2022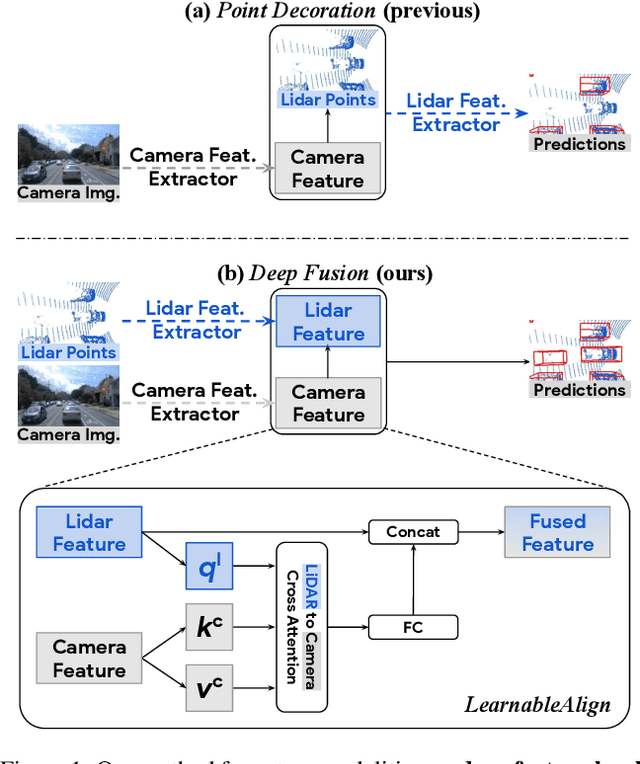
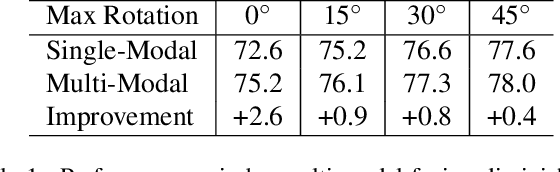
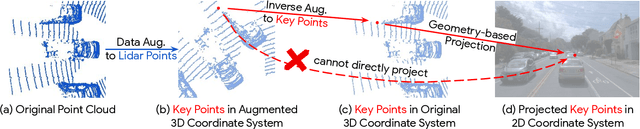
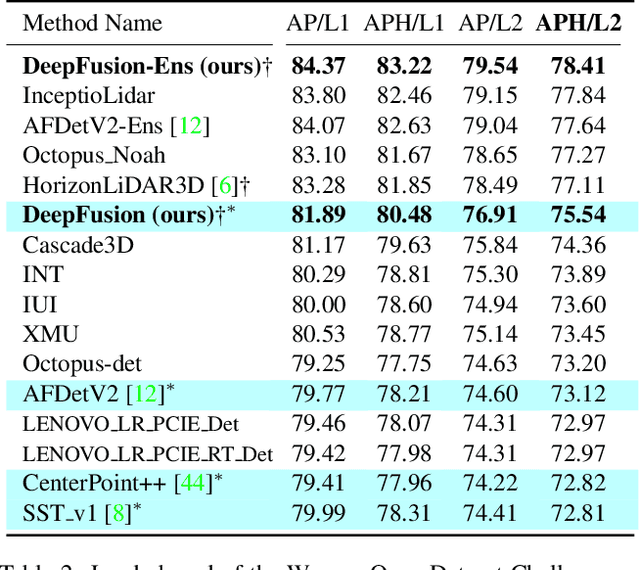
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While prevalent multi-modal methods simply decorate raw lidar point clouds with camera features and feed them directly to existing 3D detection models, our study shows that fusing camera features with deep lidar features instead of raw points, can lead to better performance. However, as those features are often augmented and aggregated, a key challenge in fusion is how to effectively align the transformed features from two modalities. In this paper, we propose two novel techniques: InverseAug that inverses geometric-related augmentations, e.g., rotation, to enable accurate geometric alignment between lidar points and image pixels, and LearnableAlign that leverages cross-attention to dynamically capture the correlations between image and lidar features during fusion. Based on InverseAug and LearnableAlign, we develop a family of generic multi-modal 3D detection models named DeepFusion, which is more accurate than previous methods. For example, DeepFusion improves PointPillars, CenterPoint, and 3D-MAN baselines on Pedestrian detection for 6.7, 8.9, and 6.2 LEVEL_2 APH, respectively. Notably, our models achieve state-of-the-art performance on Waymo Open Dataset, and show strong model robustness against input corruptions and out-of-distribution data. Code will be publicly available at https://github.com/tensorflow/lingvo/tree/master/lingvo/.
A Design Space Study for LISTA and Beyond
Apr 08, 2021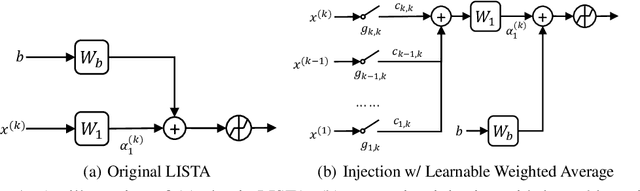
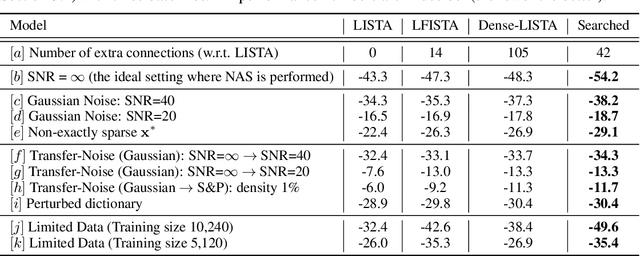
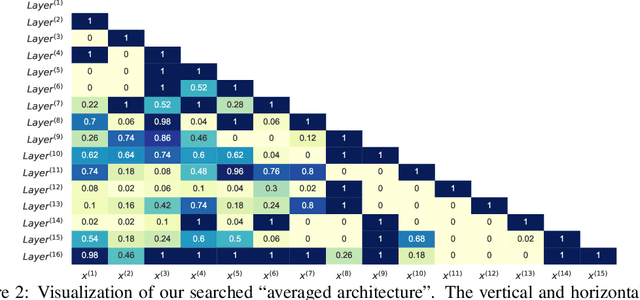

In recent years, great success has been witnessed in building problem-specific deep networks from unrolling iterative algorithms, for solving inverse problems and beyond. Unrolling is believed to incorporate the model-based prior with the learning capacity of deep learning. This paper revisits the role of unrolling as a design approach for deep networks: to what extent its resulting special architecture is superior, and can we find better? Using LISTA for sparse recovery as a representative example, we conduct the first thorough design space study for the unrolled models. Among all possible variations, we focus on extensively varying the connectivity patterns and neuron types, leading to a gigantic design space arising from LISTA. To efficiently explore this space and identify top performers, we leverage the emerging tool of neural architecture search (NAS). We carefully examine the searched top architectures in a number of settings, and are able to discover networks that are consistently better than LISTA. We further present more visualization and analysis to "open the black box", and find that the searched top architectures demonstrate highly consistent and potentially transferable patterns. We hope our study to spark more reflections and explorations on how to better mingle model-based optimization prior and data-driven learning.
Rethinking Co-design of Neural Architectures and Hardware Accelerators
Feb 17, 2021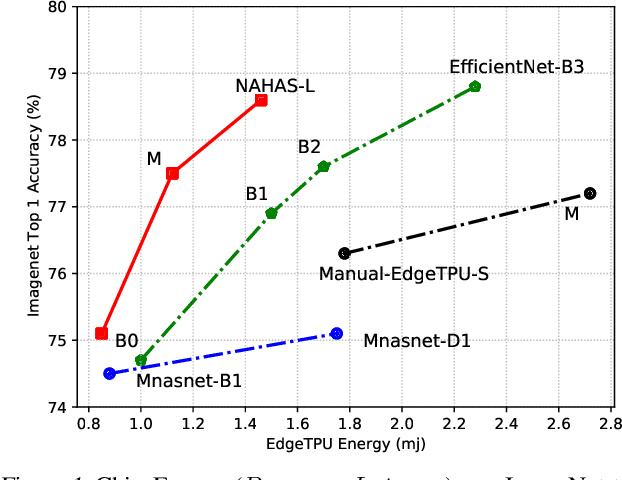
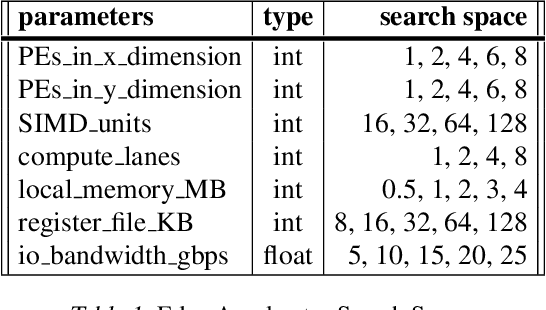
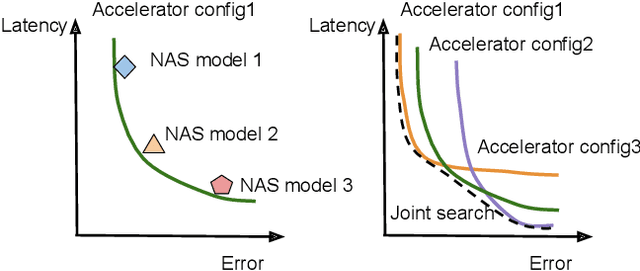
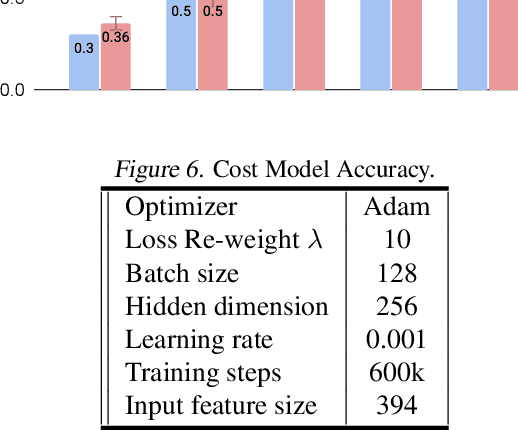
Neural architectures and hardware accelerators have been two driving forces for the progress in deep learning. Previous works typically attempt to optimize hardware given a fixed model architecture or model architecture given fixed hardware. And the dominant hardware architecture explored in this prior work is FPGAs. In our work, we target the optimization of hardware and software configurations on an industry-standard edge accelerator. We systematically study the importance and strategies of co-designing neural architectures and hardware accelerators. We make three observations: 1) the software search space has to be customized to fully leverage the targeted hardware architecture, 2) the search for the model architecture and hardware architecture should be done jointly to achieve the best of both worlds, and 3) different use cases lead to very different search outcomes. Our experiments show that the joint search method consistently outperforms previous platform-aware neural architecture search, manually crafted models, and the state-of-the-art EfficientNet on all latency targets by around 1% on ImageNet top-1 accuracy. Our method can reduce energy consumption of an edge accelerator by up to 2x under the same accuracy constraint, when co-adapting the model architecture and hardware accelerator configurations.
Spatiotemporal Contrastive Video Representation Learning
Aug 09, 2020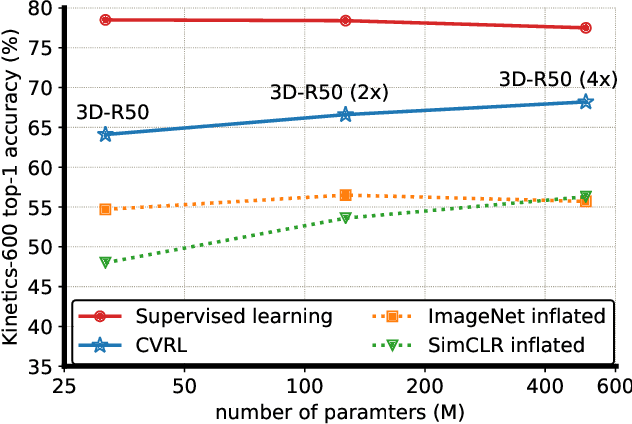

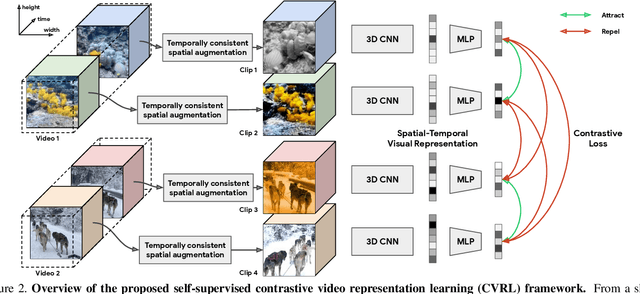
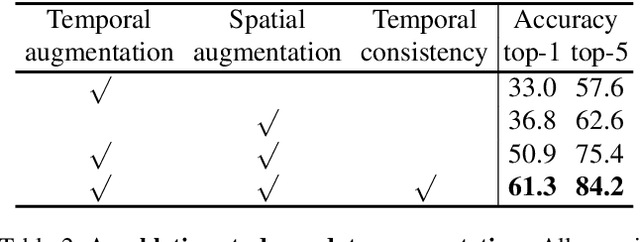
We present a self-supervised Contrastive Video Representation Learning (CVRL) method to learn spatiotemporal visual representations from unlabeled videos. Inspired by the recently proposed self-supervised contrastive learning framework, our representations are learned using a contrastive loss, where two clips from the same short video are pulled together in the embedding space, while clips from different videos are pushed away. We study what makes for good data augmentation for video self-supervised learning and find both spatial and temporal information are crucial. In particular, we propose a simple yet effective temporally consistent spatial augmentation method to impose strong spatial augmentations on each frame of a video clip while maintaining the temporal consistency across frames. For Kinetics-600 action recognition, a linear classifier trained on representations learned by CVRL achieves 64.1\% top-1 accuracy with a 3D-ResNet50 backbone, outperforming ImageNet supervised pre-training by 9.4\% and SimCLR unsupervised pre-training by 16.1\% using the same inflated 3D-ResNet50. The performance of CVRL can be further improved to 68.2\% with a larger 3D-ResNet50 (4$\times$) backbone, significantly closing the gap between unsupervised and supervised video representation learning.
Go Wide, Then Narrow: Efficient Training of Deep Thin Networks
Jul 01, 2020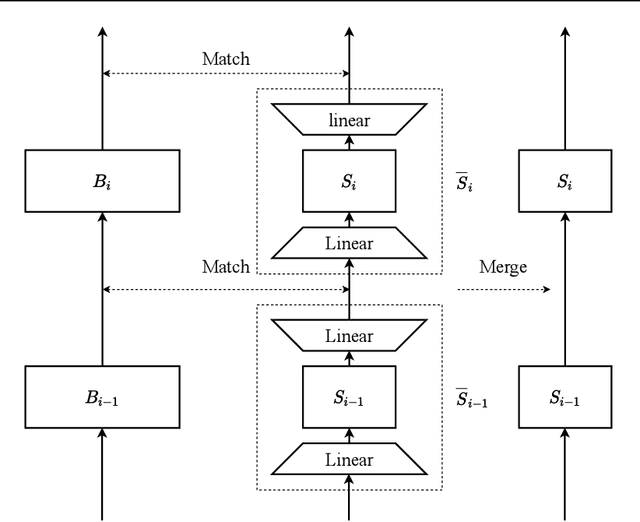
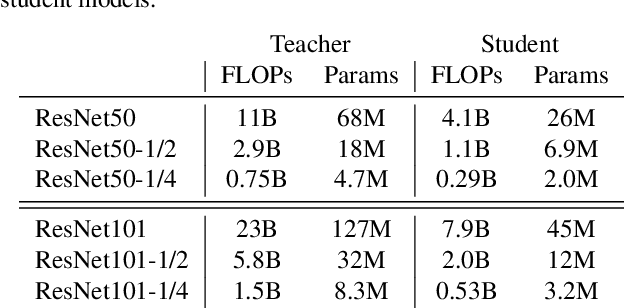
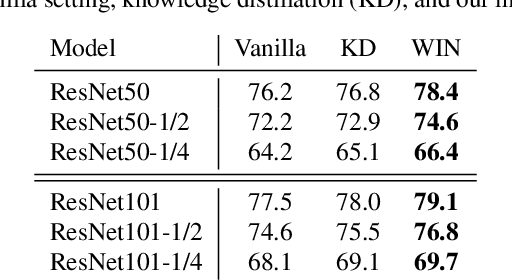
For deploying a deep learning model into production, it needs to be both accurate and compact to meet the latency and memory constraints. This usually results in a network that is deep (to ensure performance) and yet thin (to improve computational efficiency). In this paper, we propose an efficient method to train a deep thin network with a theoretic guarantee. Our method is motivated by model compression. It consists of three stages. In the first stage, we sufficiently widen the deep thin network and train it until convergence. In the second stage, we use this well-trained deep wide network to warm up (or initialize) the original deep thin network. This is achieved by letting the thin network imitate the immediate outputs of the wide network from layer to layer. In the last stage, we further fine tune this well initialized deep thin network. The theoretical guarantee is established by using mean field analysis, which shows the advantage of layerwise imitation over traditional training deep thin networks from scratch by backpropagation. We also conduct large-scale empirical experiments to validate our approach. By training with our method, ResNet50 can outperform ResNet101, and BERT_BASE can be comparable with BERT_LARGE, where both the latter models are trained via the standard training procedures as in the literature.
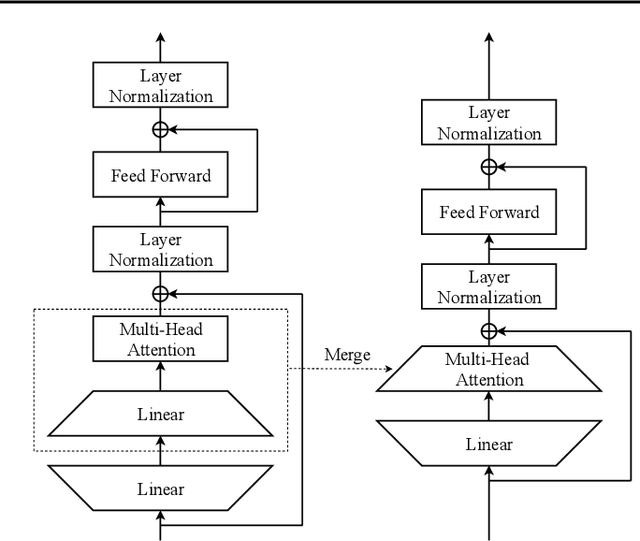
SSN: Learning Sparse Switchable Normalization via SparsestMax
Mar 09, 2019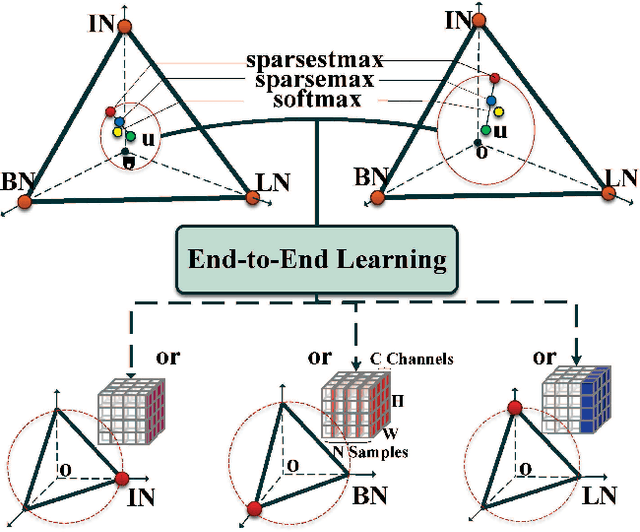
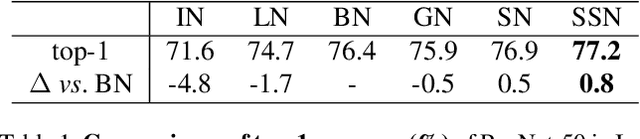
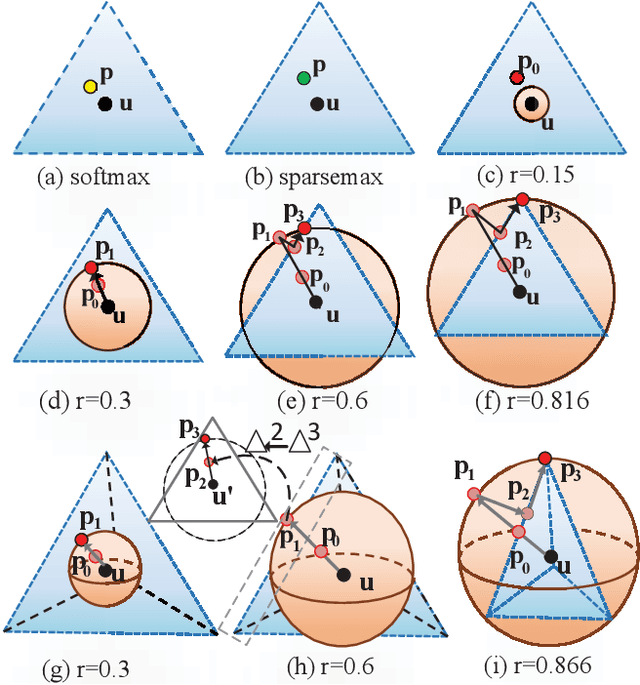
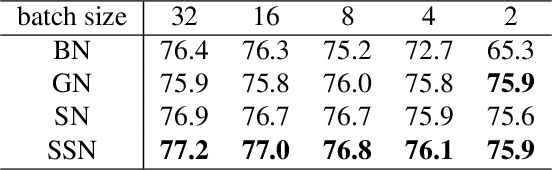
Normalization methods improve both optimization and generalization of ConvNets. To further boost performance, the recently-proposed switchable normalization (SN) provides a new perspective for deep learning: it learns to select different normalizers for different convolution layers of a ConvNet. However, SN uses softmax function to learn importance ratios to combine normalizers, leading to redundant computations compared to a single normalizer. This work addresses this issue by presenting Sparse Switchable Normalization (SSN) where the importance ratios are constrained to be sparse. Unlike $\ell_1$ and $\ell_0$ constraints that impose difficulties in optimization, we turn this constrained optimization problem into feed-forward computation by proposing SparsestMax, which is a sparse version of softmax. SSN has several appealing properties. (1) It inherits all benefits from SN such as applicability in various tasks and robustness to a wide range of batch sizes. (2) It is guaranteed to select only one normalizer for each normalization layer, avoiding redundant computations. (3) SSN can be transferred to various tasks in an end-to-end manner. Extensive experiments show that SSN outperforms its counterparts on various challenging benchmarks such as ImageNet, Cityscapes, ADE20K, and Kinetics.