 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeCafNet: Delegate and Conquer for Efficient Temporal Grounding in Long Videos
May 22, 2025Long Video Temporal Grounding (LVTG) aims at identifying specific moments within lengthy videos based on user-provided text queries for effective content retrieval. The approach taken by existing methods of dividing video into clips and processing each clip via a full-scale expert encoder is challenging to scale due to prohibitive computational costs of processing a large number of clips in long videos. To address this issue, we introduce DeCafNet, an approach employing ``delegate-and-conquer'' strategy to achieve computation efficiency without sacrificing grounding performance. DeCafNet introduces a sidekick encoder that performs dense feature extraction over all video clips in a resource-efficient manner, while generating a saliency map to identify the most relevant clips for full processing by the expert encoder. To effectively leverage features from sidekick and expert encoders that exist at different temporal resolutions, we introduce DeCaf-Grounder, which unifies and refines them via query-aware temporal aggregation and multi-scale temporal refinement for accurate grounding. Experiments on two LTVG benchmark datasets demonstrate that DeCafNet reduces computation by up to 47\% while still outperforming existing methods, establishing a new state-of-the-art for LTVG in terms of both efficiency and performance. Our code is available at https://github.com/ZijiaLewisLu/CVPR2025-DeCafNet.
Self-Supervised Multi-Object Tracking with Path Consistency
Apr 08, 2024In this paper, we propose a novel concept of path consistency to learn robust object matching without using manual object identity supervision. Our key idea is that, to track a object through frames, we can obtain multiple different association results from a model by varying the frames it can observe, i.e., skipping frames in observation. As the differences in observations do not alter the identities of objects, the obtained association results should be consistent. Based on this rationale, we generate multiple observation paths, each specifying a different set of frames to be skipped, and formulate the Path Consistency Loss that enforces the association results are consistent across different observation paths. We use the proposed loss to train our object matching model with only self-supervision. By extensive experiments on three tracking datasets (MOT17, PersonPath22, KITTI), we demonstrate that our method outperforms existing unsupervised methods with consistent margins on various evaluation metrics, and even achieves performance close to supervised methods.
BIT: Bi-Level Temporal Modeling for Efficient Supervised Action Segmentation
Aug 28, 2023



We address the task of supervised action segmentation which aims to partition a video into non-overlapping segments, each representing a different action. Recent works apply transformers to perform temporal modeling at the frame-level, which suffer from high computational cost and cannot well capture action dependencies over long temporal horizons. To address these issues, we propose an efficient BI-level Temporal modeling (BIT) framework that learns explicit action tokens to represent action segments, in parallel performs temporal modeling on frame and action levels, while maintaining a low computational cost. Our model contains (i) a frame branch that uses convolution to learn frame-level relationships, (ii) an action branch that uses transformer to learn action-level dependencies with a small set of action tokens and (iii) cross-attentions to allow communication between the two branches. We apply and extend a set-prediction objective to allow each action token to represent one or multiple action segments, thus can avoid learning a large number of tokens over long videos with many segments. Thanks to the design of our action branch, we can also seamlessly leverage textual transcripts of videos (when available) to help action segmentation by using them to initialize the action tokens. We evaluate our model on four video datasets (two egocentric and two third-person) for action segmentation with and without transcripts, showing that BIT significantly improves the state-of-the-art accuracy with much lower computational cost (30 times faster) compared to existing transformer-based methods.
MediaGPT : A Large Language Model For Chinese Media
Jul 26, 2023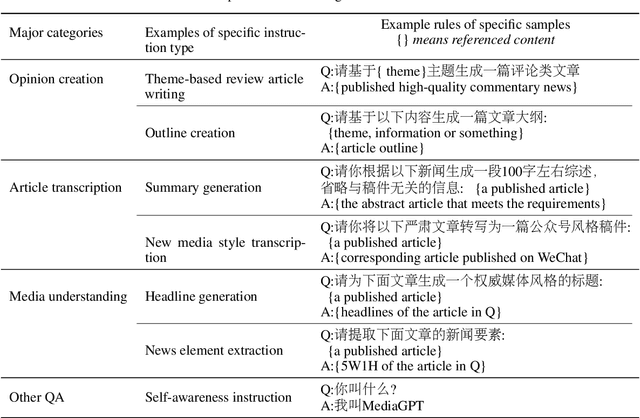



Large language models (LLMs) have shown remarkable capabilities in generating high-quality text and making predictions based on large amounts of data, including the media domain. However, in practical applications, the differences between the media's use cases and the general-purpose applications of LLMs have become increasingly apparent, especially Chinese. This paper examines the unique characteristics of media-domain-specific LLMs compared to general LLMs, designed a diverse set of task instruction types to cater the specific requirements of the domain and constructed unique datasets that are tailored to the media domain. Based on these, we proposed MediaGPT, a domain-specific LLM for the Chinese media domain, training by domain-specific data and experts SFT data. By performing human experts evaluation and strong model evaluation on a validation set, this paper demonstrated that MediaGPT outperforms mainstream models on various Chinese media domain tasks and verifies the importance of domain data and domain-defined prompt types for building an effective domain-specific LLM.