 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeCafNet: Delegate and Conquer for Efficient Temporal Grounding in Long Videos
May 22, 2025Long Video Temporal Grounding (LVTG) aims at identifying specific moments within lengthy videos based on user-provided text queries for effective content retrieval. The approach taken by existing methods of dividing video into clips and processing each clip via a full-scale expert encoder is challenging to scale due to prohibitive computational costs of processing a large number of clips in long videos. To address this issue, we introduce DeCafNet, an approach employing ``delegate-and-conquer'' strategy to achieve computation efficiency without sacrificing grounding performance. DeCafNet introduces a sidekick encoder that performs dense feature extraction over all video clips in a resource-efficient manner, while generating a saliency map to identify the most relevant clips for full processing by the expert encoder. To effectively leverage features from sidekick and expert encoders that exist at different temporal resolutions, we introduce DeCaf-Grounder, which unifies and refines them via query-aware temporal aggregation and multi-scale temporal refinement for accurate grounding. Experiments on two LTVG benchmark datasets demonstrate that DeCafNet reduces computation by up to 47\% while still outperforming existing methods, establishing a new state-of-the-art for LTVG in terms of both efficiency and performance. Our code is available at https://github.com/ZijiaLewisLu/CVPR2025-DeCafNet.
BIT: Bi-Level Temporal Modeling for Efficient Supervised Action Segmentation
Aug 28, 2023



We address the task of supervised action segmentation which aims to partition a video into non-overlapping segments, each representing a different action. Recent works apply transformers to perform temporal modeling at the frame-level, which suffer from high computational cost and cannot well capture action dependencies over long temporal horizons. To address these issues, we propose an efficient BI-level Temporal modeling (BIT) framework that learns explicit action tokens to represent action segments, in parallel performs temporal modeling on frame and action levels, while maintaining a low computational cost. Our model contains (i) a frame branch that uses convolution to learn frame-level relationships, (ii) an action branch that uses transformer to learn action-level dependencies with a small set of action tokens and (iii) cross-attentions to allow communication between the two branches. We apply and extend a set-prediction objective to allow each action token to represent one or multiple action segments, thus can avoid learning a large number of tokens over long videos with many segments. Thanks to the design of our action branch, we can also seamlessly leverage textual transcripts of videos (when available) to help action segmentation by using them to initialize the action tokens. We evaluate our model on four video datasets (two egocentric and two third-person) for action segmentation with and without transcripts, showing that BIT significantly improves the state-of-the-art accuracy with much lower computational cost (30 times faster) compared to existing transformer-based methods.
Exploring the Role of Audio in Video Captioning
Jun 21, 2023Recent focus in video captioning has been on designing architectures that can consume both video and text modalities, and using large-scale video datasets with text transcripts for pre-training, such as HowTo100M. Though these approaches have achieved significant improvement, the audio modality is often ignored in video captioning. In this work, we present an audio-visual framework, which aims to fully exploit the potential of the audio modality for captioning. Instead of relying on text transcripts extracted via automatic speech recognition (ASR), we argue that learning with raw audio signals can be more beneficial, as audio has additional information including acoustic events, speaker identity, etc. Our contributions are twofold. First, we observed that the model overspecializes to the audio modality when pre-training with both video and audio modality, since the ground truth (i.e., text transcripts) can be solely predicted using audio. We proposed a Modality Balanced Pre-training (MBP) loss to mitigate this issue and significantly improve the performance on downstream tasks. Second, we slice and dice different design choices of the cross-modal module, which may become an information bottleneck and generate inferior results. We proposed new local-global fusion mechanisms to improve information exchange across audio and video. We demonstrate significant improvements by leveraging the audio modality on four datasets, and even outperform the state of the art on some metrics without relying on the text modality as the input.
Towards Effective Multi-Label Recognition Attacks via Knowledge Graph Consistency
Jul 11, 2022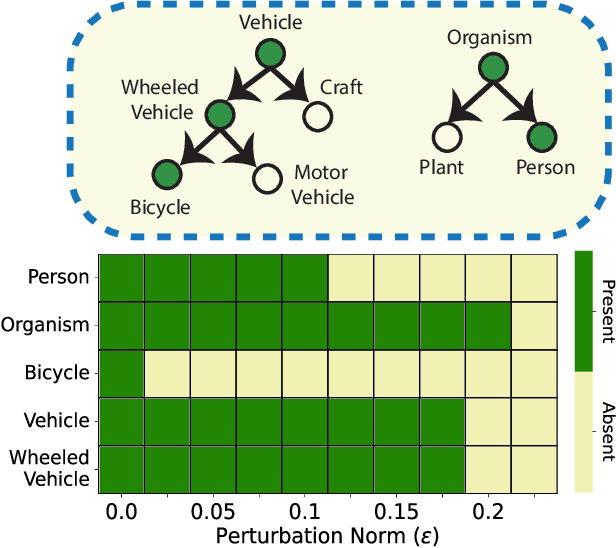
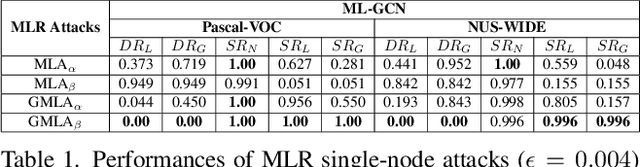

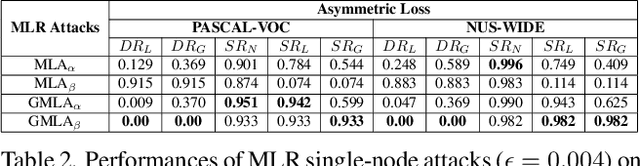
Many real-world applications of image recognition require multi-label learning, whose goal is to find all labels in an image. Thus, robustness of such systems to adversarial image perturbations is extremely important. However, despite a large body of recent research on adversarial attacks, the scope of the existing works is mainly limited to the multi-class setting, where each image contains a single label. We show that the naive extensions of multi-class attacks to the multi-label setting lead to violating label relationships, modeled by a knowledge graph, and can be detected using a consistency verification scheme. Therefore, we propose a graph-consistent multi-label attack framework, which searches for small image perturbations that lead to misclassifying a desired target set while respecting label hierarchies. By extensive experiments on two datasets and using several multi-label recognition models, we show that our method generates extremely successful attacks that, unlike naive multi-label perturbations, can produce model predictions consistent with the knowledge graph.
Open-Vocabulary Instance Segmentation via Robust Cross-Modal Pseudo-Labeling
Nov 24, 2021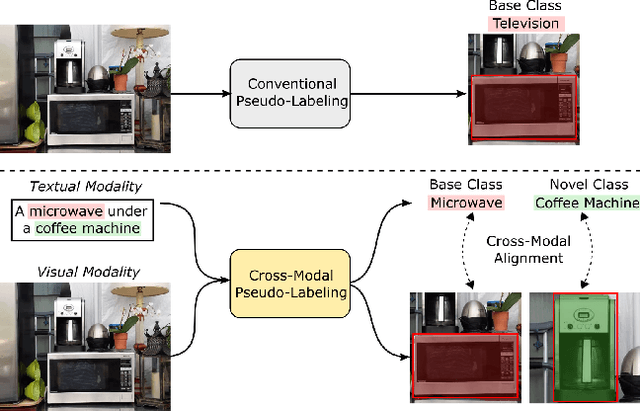
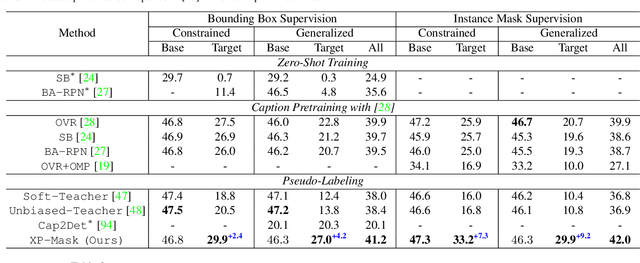
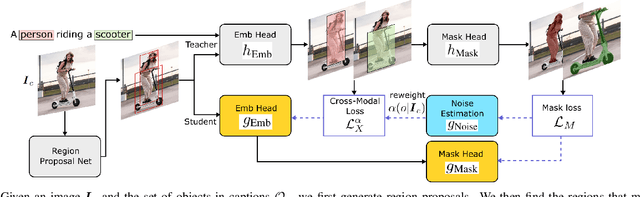
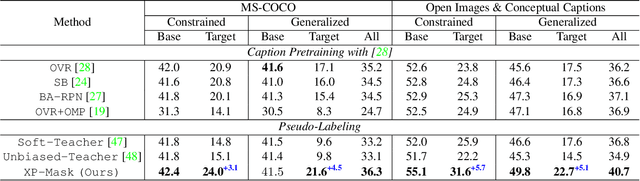
Open-vocabulary instance segmentation aims at segmenting novel classes without mask annotations. It is an important step toward reducing laborious human supervision. Most existing works first pretrain a model on captioned images covering many novel classes and then finetune it on limited base classes with mask annotations. However, the high-level textual information learned from caption pretraining alone cannot effectively encode the details required for pixel-wise segmentation. To address this, we propose a cross-modal pseudo-labeling framework, which generates training pseudo masks by aligning word semantics in captions with visual features of object masks in images. Thus, our framework is capable of labeling novel classes in captions via their word semantics to self-train a student model. To account for noises in pseudo masks, we design a robust student model that selectively distills mask knowledge by estimating the mask noise levels, hence mitigating the adverse impact of noisy pseudo masks. By extensive experiments, we show the effectiveness of our framework, where we significantly improve mAP score by 4.5% on MS-COCO and 5.1% on the large-scale Open Images & Conceptual Captions datasets compared to the state-of-the-art.
Compositional Fine-Grained Low-Shot Learning
May 21, 2021

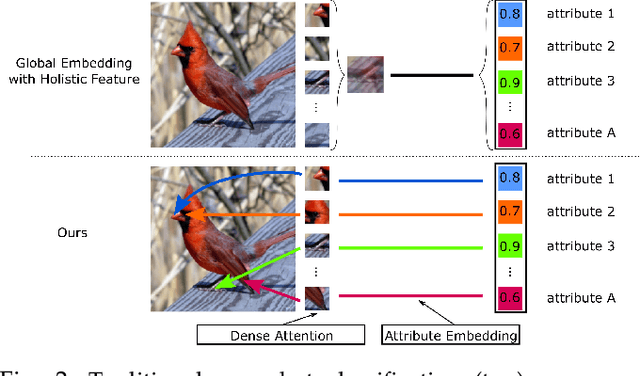

We develop a novel compositional generative model for zero- and few-shot learning to recognize fine-grained classes with a few or no training samples. Our key observation is that generating holistic features for fine-grained classes fails to capture small attribute differences between classes. Therefore, we propose a feature composition framework that learns to extract attribute features from training samples and combines them to construct fine-grained features for rare and unseen classes. Feature composition allows us to not only selectively compose features of every class from only relevant training samples, but also obtain diversity among composed features via changing samples used for the composition. In addition, instead of building holistic features for classes, we use our attribute features to form dense representations capable of capturing fine-grained attribute details of classes. We propose a training scheme that uses a discriminative model to construct features that are subsequently used to train the model itself. Therefore, we directly train the discriminative model on the composed features without learning a separate generative model. We conduct experiments on four popular datasets of DeepFashion, AWA2, CUB, and SUN, showing the effectiveness of our method.
Weighting Is Worth the Wait: Bayesian Optimization with Importance Sampling
Feb 23, 2020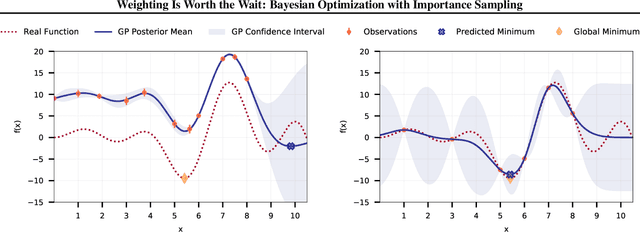
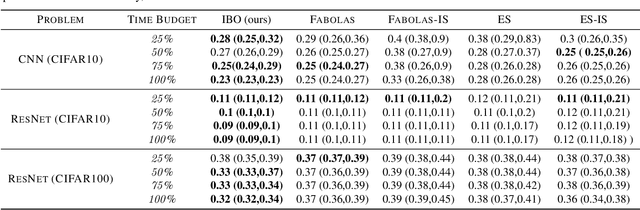
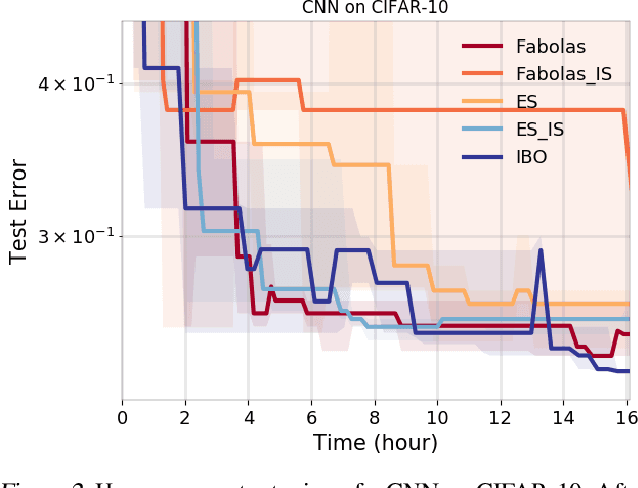
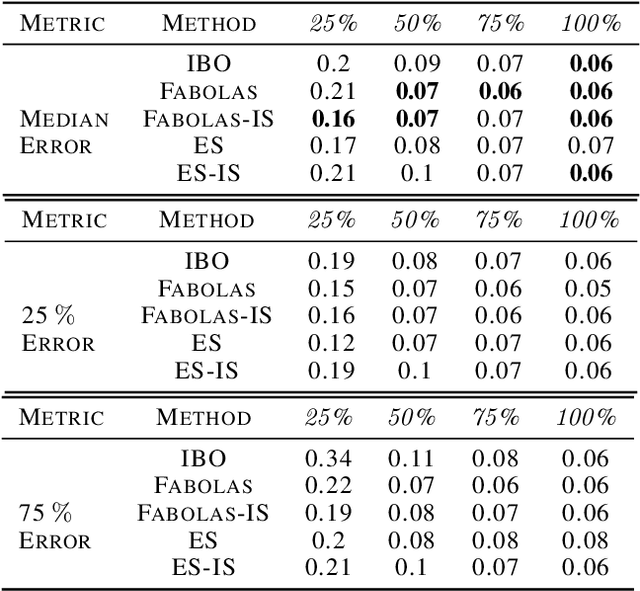
Many contemporary machine learning models require extensive tuning of hyperparameters to perform well. A variety of methods, such as Bayesian optimization, have been developed to automate and expedite this process. However, tuning remains extremely costly as it typically requires repeatedly fully training models. We propose to accelerate the Bayesian optimization approach to hyperparameter tuning for neural networks by taking into account the relative amount of information contributed by each training example. To do so, we leverage importance sampling (IS); this significantly increases the quality of the black-box function evaluations, but also their runtime, and so must be done carefully. Casting hyperparameter search as a multi-task Bayesian optimization problem over both hyperparameters and importance sampling design achieves the best of both worlds: by learning a parameterization of IS that trades-off evaluation complexity and quality, we improve upon Bayesian optimization state-of-the-art runtime and final validation error across a variety of datasets and complex neural architectures.
Dissimilarity-based Sparse Subset Selection
Apr 09, 2016
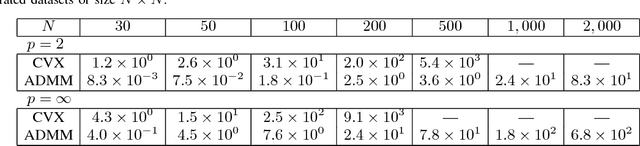
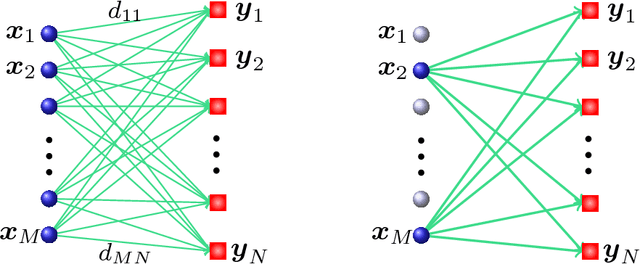
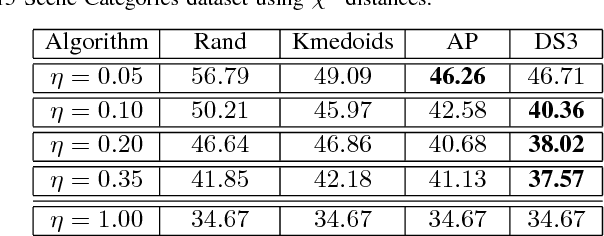
Finding an informative subset of a large collection of data points or models is at the center of many problems in computer vision, recommender systems, bio/health informatics as well as image and natural language processing. Given pairwise dissimilarities between the elements of a `source set' and a `target set,' we consider the problem of finding a subset of the source set, called representatives or exemplars, that can efficiently describe the target set. We formulate the problem as a row-sparsity regularized trace minimization problem. Since the proposed formulation is, in general, NP-hard, we consider a convex relaxation. The solution of our optimization finds representatives and the assignment of each element of the target set to each representative, hence, obtaining a clustering. We analyze the solution of our proposed optimization as a function of the regularization parameter. We show that when the two sets jointly partition into multiple groups, our algorithm finds representatives from all groups and reveals clustering of the sets. In addition, we show that the proposed framework can effectively deal with outliers. Our algorithm works with arbitrary dissimilarities, which can be asymmetric or violate the triangle inequality. To efficiently implement our algorithm, we consider an Alternating Direction Method of Multipliers (ADMM) framework, which results in quadratic complexity in the problem size. We show that the ADMM implementation allows to parallelize the algorithm, hence further reducing the computational time. Finally, by experiments on real-world datasets, we show that our proposed algorithm improves the state of the art on the two problems of scene categorization using representative images and time-series modeling and segmentation using representative~models.
Approximate Subspace-Sparse Recovery with Corrupted Data via Constrained $\ell_1$-Minimization
Feb 13, 2016
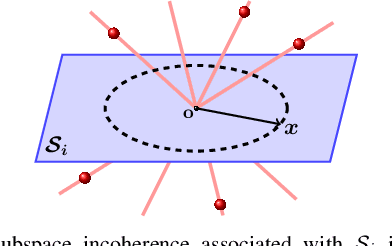
High-dimensional data often lie in low-dimensional subspaces corresponding to different classes they belong to. Finding sparse representations of data points in a dictionary built using the collection of data helps to uncover low-dimensional subspaces and address problems such as clustering, classification, subset selection and more. In this paper, we address the problem of recovering sparse representations for noisy data points in a dictionary whose columns correspond to corrupted data lying close to a union of subspaces. We consider a constrained $\ell_1$-minimization and study conditions under which the solution of the proposed optimization satisfies the approximate subspace-sparse recovery condition. More specifically, we show that each noisy data point, perturbed from a subspace by a noise of the magnitude of $\varepsilon$, will be reconstructed using data points from the same subspace with a small error of the order of $O(\varepsilon)$ and that the coefficients corresponding to data points in other subspaces will be sufficiently small, \ie, of the order of $O(\varepsilon)$. We do not impose any randomness assumption on the arrangement of subspaces or distribution of data points in each subspace. Our framework is based on a novel generalization of the null-space property to the setting where data lie in multiple subspaces, the number of data points in each subspace exceeds the dimension of the subspace, and all data points are corrupted by noise. Moreover, assuming a random distribution for data points, we further show that coefficients from the desired support not only reconstruct a given point with high accuracy, but also have sufficiently large values, \ie, of the order of $O(1)$.
Robust subspace clustering
May 23, 2014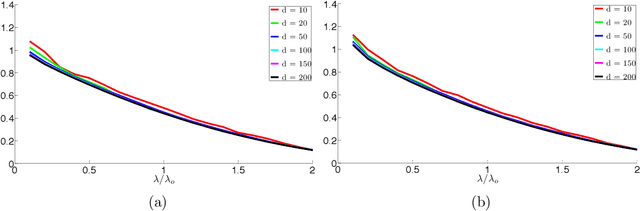

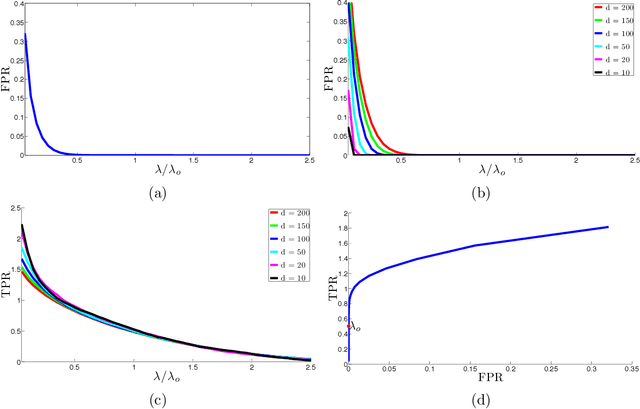

Subspace clustering refers to the task of finding a multi-subspace representation that best fits a collection of points taken from a high-dimensional space. This paper introduces an algorithm inspired by sparse subspace clustering (SSC) [In IEEE Conference on Computer Vision and Pattern Recognition, CVPR (2009) 2790-2797] to cluster noisy data, and develops some novel theory demonstrating its correctness. In particular, the theory uses ideas from geometric functional analysis to show that the algorithm can accurately recover the underlying subspaces under minimal requirements on their orientation, and on the number of samples per subspace. Synthetic as well as real data experiments complement our theoretical study, illustrating our approach and demonstrating its effectiveness.
* Published in at http://dx.doi.org/10.1214/13-AOS1199 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)