 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective Multi-Label Recognition Attacks via Knowledge Graph Consistency
Jul 11, 2022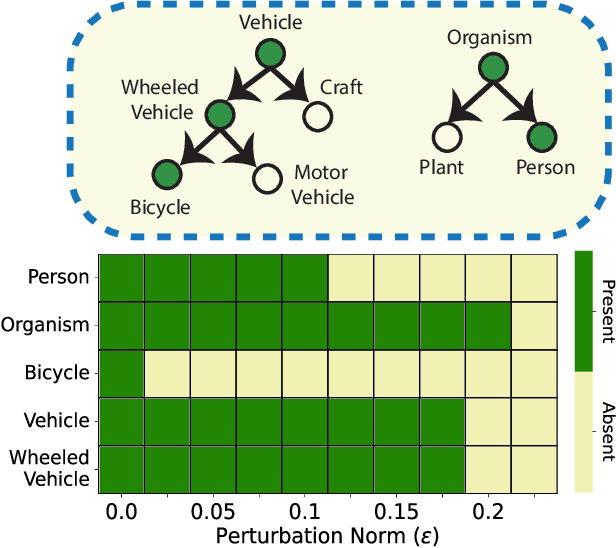
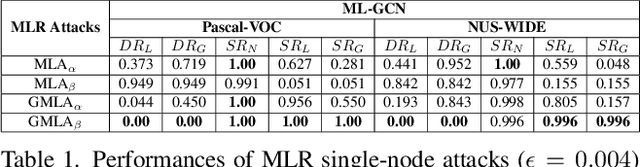

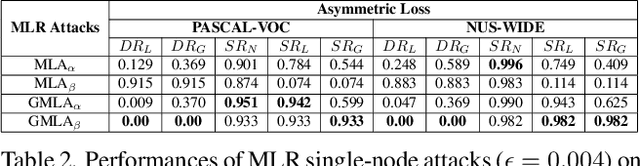
Many real-world applications of image recognition require multi-label learning, whose goal is to find all labels in an image. Thus, robustness of such systems to adversarial image perturbations is extremely important. However, despite a large body of recent research on adversarial attacks, the scope of the existing works is mainly limited to the multi-class setting, where each image contains a single label. We show that the naive extensions of multi-class attacks to the multi-label setting lead to violating label relationships, modeled by a knowledge graph, and can be detected using a consistency verification scheme. Therefore, we propose a graph-consistent multi-label attack framework, which searches for small image perturbations that lead to misclassifying a desired target set while respecting label hierarchies. By extensive experiments on two datasets and using several multi-label recognition models, we show that our method generates extremely successful attacks that, unlike naive multi-label perturbations, can produce model predictions consistent with the knowledge graph.
Exploring Intensity Invariance in Deep Neural Networks for Brain Image Registration
Sep 21, 2020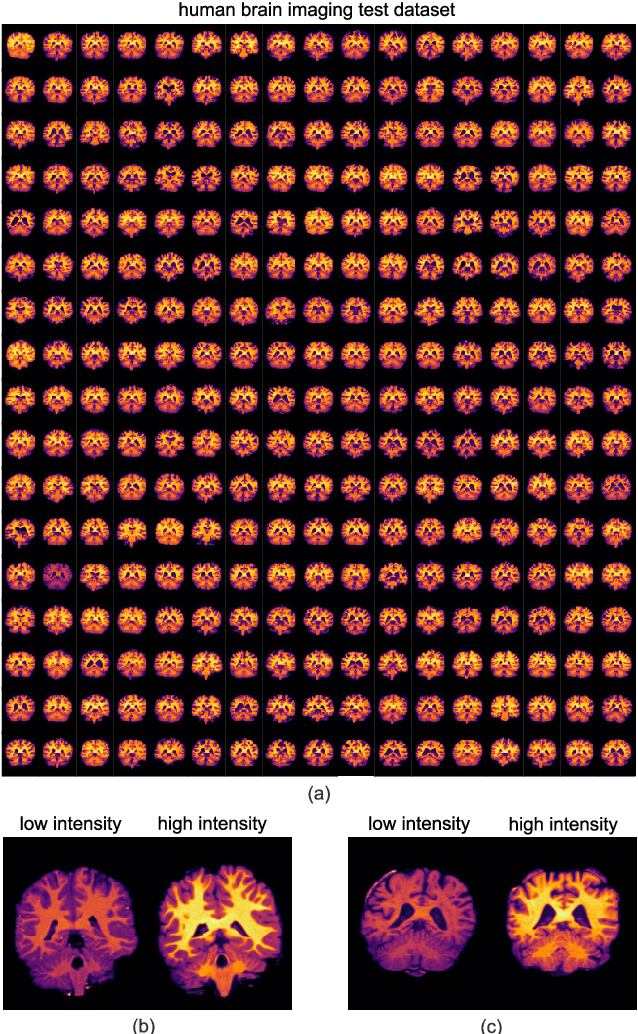
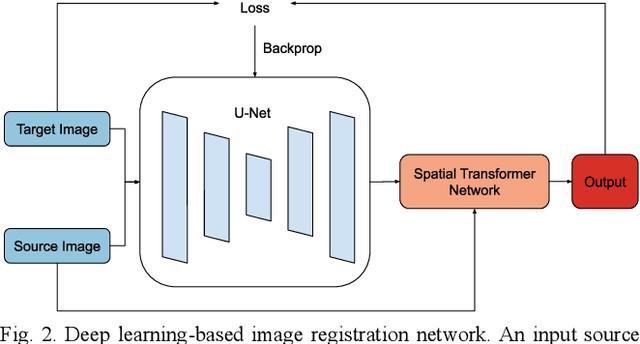

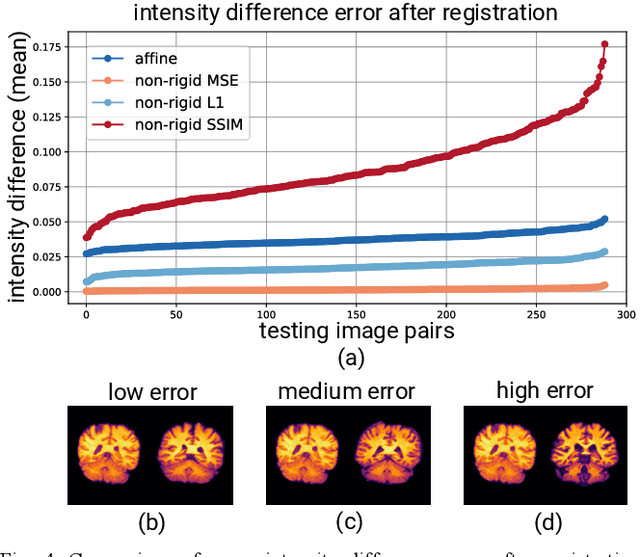
Image registration is a widely-used technique in analysing large scale datasets that are captured through various imaging modalities and techniques in biomedical imaging such as MRI, X-Rays, etc. These datasets are typically collected from various sites and under different imaging protocols using a variety of scanners. Such heterogeneity in the data collection process causes inhomogeneity or variation in intensity (brightness) and noise distribution. These variations play a detrimental role in the performance of image registration, segmentation and detection algorithms. Classical image registration methods are computationally expensive but are able to handle these artifacts relatively better. However, deep learning-based techniques are shown to be computationally efficient for automated brain registration but are sensitive to the intensity variations. In this study, we investigate the effect of variation in intensity distribution among input image pairs for deep learning-based image registration methods. We find a performance degradation of these models when brain image pairs with different intensity distribution are presented even with similar structures. To overcome this limitation, we incorporate a structural similarity-based loss function in a deep neural network and test its performance on the validation split separated before training as well as on a completely unseen new dataset. We report that the deep learning models trained with structure similarity-based loss seems to perform better for both datasets. This investigation highlights a possible performance limiting factor in deep learning-based registration models and suggests a potential solution to incorporate the intensity distribution variation in the input image pairs. Our code and models are available at https://github.com/hassaanmahmood/DeepIntense.
Rethinking Table Parsing using Graph Neural Networks
May 31, 2019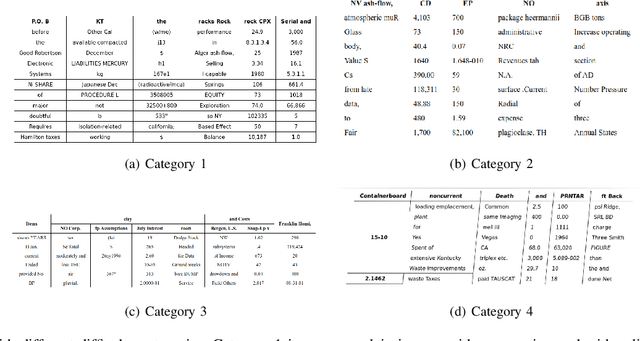
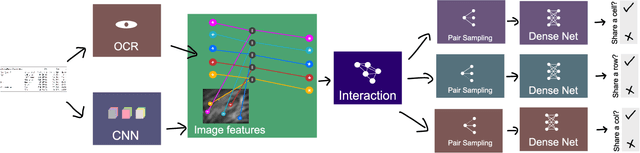
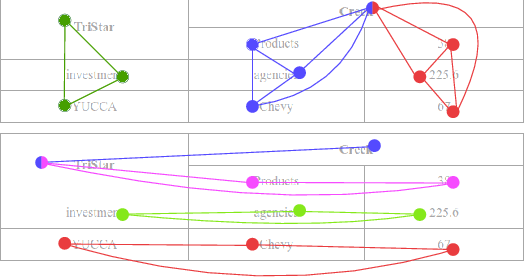
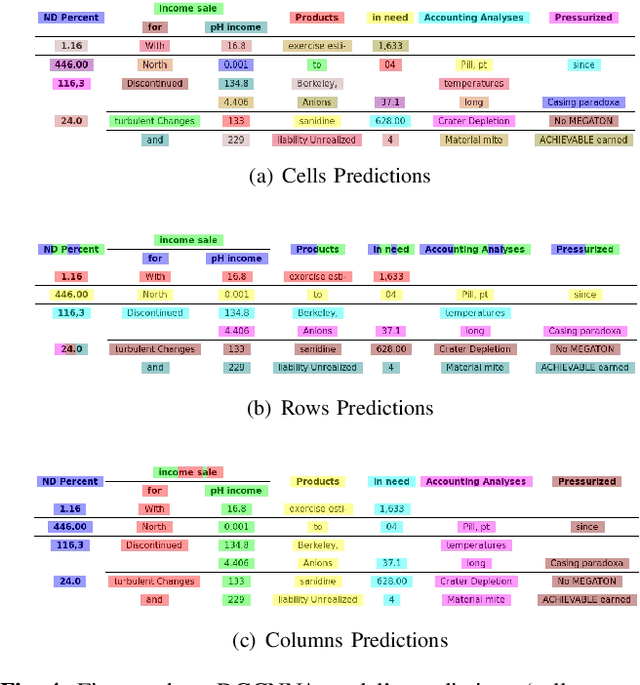
Document structure analysis, such as zone segmentation and table parsing, is a complex problem in document processing and is an active area of research. The recent success of deep learning in solving various computer vision and machine learning problems has not been reflected in document structure analysis since conventional neural networks are not well suited to the input structure of the problem. In this paper, we propose an architecture based on graph networks as a better alternative to standard neural networks for table parsing. We argue that graph networks are a more natural choice for these problems, and explore two gradient-based graph neural networks. Our proposed architecture combines the benefits of convolutional neural networks for visual feature extraction and graph networks for dealing with the problem structure. We empirically demonstrate that our method outperforms the baseline by a significant margin. In addition, we identify the lack of large scale datasets as a major hindrance for deep learning research for structure analysis, and present a new large scale synthetic dataset for the problem of table parsing. Finally, we open-source our implementation of dataset generation and the training framework of our graph networks to promote reproducible research in this direction.