 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAiVAR-T: Multimodal Audio-image and Video Action Recognizer using Transformers
Aug 01, 2023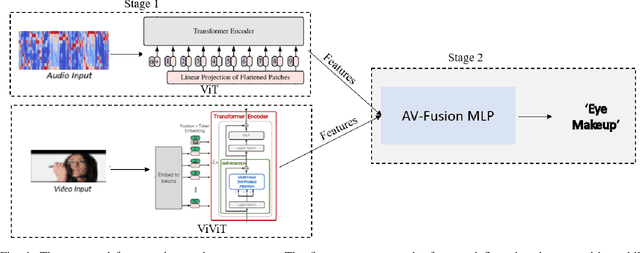



In line with the human capacity to perceive the world by simultaneously processing and integrating high-dimensional inputs from multiple modalities like vision and audio, we propose a novel model, MAiVAR-T (Multimodal Audio-Image to Video Action Recognition Transformer). This model employs an intuitive approach for the combination of audio-image and video modalities, with a primary aim to escalate the effectiveness of multimodal human action recognition (MHAR). At the core of MAiVAR-T lies the significance of distilling substantial representations from the audio modality and transmuting these into the image domain. Subsequently, this audio-image depiction is fused with the video modality to formulate a unified representation. This concerted approach strives to exploit the contextual richness inherent in both audio and video modalities, thereby promoting action recognition. In contrast to existing state-of-the-art strategies that focus solely on audio or video modalities, MAiVAR-T demonstrates superior performance. Our extensive empirical evaluations conducted on a benchmark action recognition dataset corroborate the model's remarkable performance. This underscores the potential enhancements derived from integrating audio and video modalities for action recognition purposes.
MAiVAR: Multimodal Audio-Image and Video Action Recognizer
Sep 11, 2022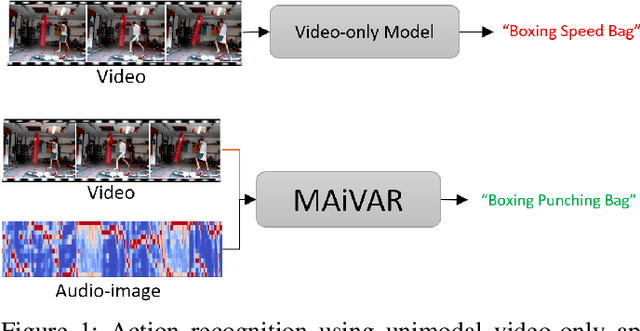
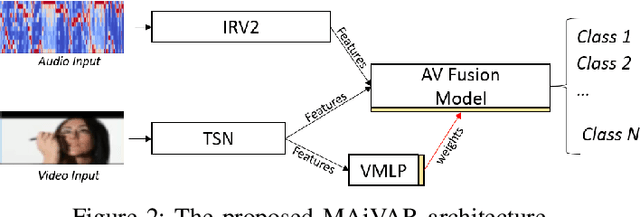
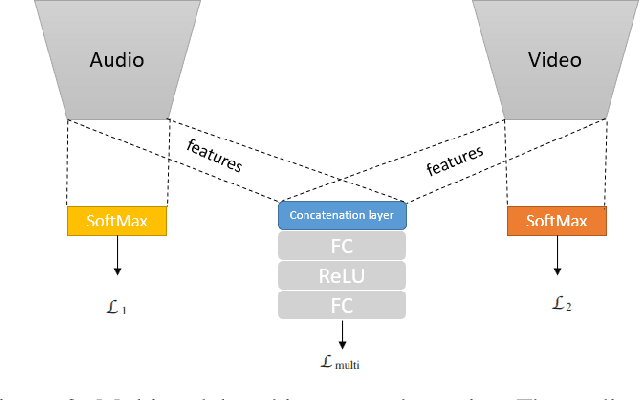

Currently, action recognition is predominately performed on video data as processed by CNNs. We investigate if the representation process of CNNs can also be leveraged for multimodal action recognition by incorporating image-based audio representations of actions in a task. To this end, we propose Multimodal Audio-Image and Video Action Recognizer (MAiVAR), a CNN-based audio-image to video fusion model that accounts for video and audio modalities to achieve superior action recognition performance. MAiVAR extracts meaningful image representations of audio and fuses it with video representation to achieve better performance as compared to both modalities individually on a large-scale action recognition dataset.
Exploring Intensity Invariance in Deep Neural Networks for Brain Image Registration
Sep 21, 2020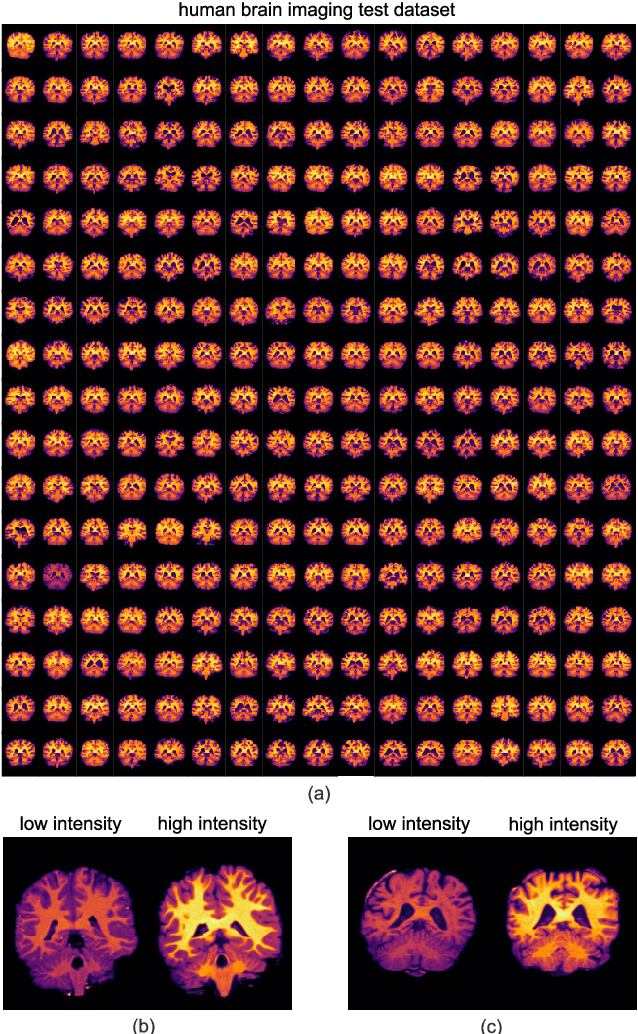
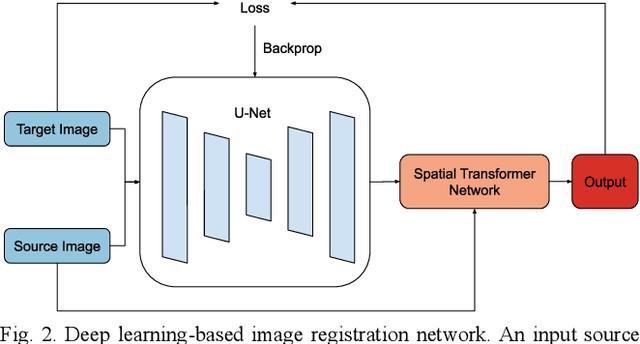

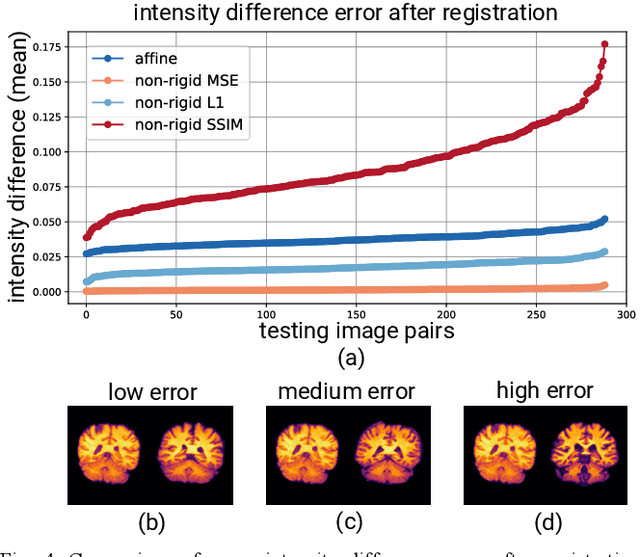
Image registration is a widely-used technique in analysing large scale datasets that are captured through various imaging modalities and techniques in biomedical imaging such as MRI, X-Rays, etc. These datasets are typically collected from various sites and under different imaging protocols using a variety of scanners. Such heterogeneity in the data collection process causes inhomogeneity or variation in intensity (brightness) and noise distribution. These variations play a detrimental role in the performance of image registration, segmentation and detection algorithms. Classical image registration methods are computationally expensive but are able to handle these artifacts relatively better. However, deep learning-based techniques are shown to be computationally efficient for automated brain registration but are sensitive to the intensity variations. In this study, we investigate the effect of variation in intensity distribution among input image pairs for deep learning-based image registration methods. We find a performance degradation of these models when brain image pairs with different intensity distribution are presented even with similar structures. To overcome this limitation, we incorporate a structural similarity-based loss function in a deep neural network and test its performance on the validation split separated before training as well as on a completely unseen new dataset. We report that the deep learning models trained with structure similarity-based loss seems to perform better for both datasets. This investigation highlights a possible performance limiting factor in deep learning-based registration models and suggests a potential solution to incorporate the intensity distribution variation in the input image pairs. Our code and models are available at https://github.com/hassaanmahmood/DeepIntense.