 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocDjinn: Controllable Synthetic Document Generation with VLMs and Handwriting Diffusion
Feb 25, 2026Effective document intelligence models rely on large amounts of annotated training data. However, procuring sufficient and high-quality data poses significant challenges due to the labor-intensive and costly nature of data acquisition. Additionally, leveraging language models to annotate real documents raises concerns about data privacy. Synthetic document generation has emerged as a promising, privacy-preserving alternative. We propose DocDjinn, a novel framework for controllable synthetic document generation using Vision-Language Models (VLMs) that produces annotated documents from unlabeled seed samples. Our approach generates visually plausible and semantically consistent synthetic documents that follow the distribution of an existing source dataset through clustering-based seed selection with parametrized sampling. By enriching documents with realistic diffusion-based handwriting and contextual visual elements via semantic-visual decoupling, we generate diverse, high-quality annotated synthetic documents. We evaluate across eleven benchmarks spanning key information extraction, question answering, document classification, and document layout analysis. To our knowledge, this is the first work demonstrating that VLMs can generate faithful annotated document datasets at scale from unlabeled seeds that can effectively enrich or approximate real, manually annotated data for diverse document understanding tasks. We show that with only 100 real training samples, our framework achieves on average $87\%$ of the performance of the full real-world dataset. We publicly release our code and 140k+ synthetic document samples.
LAPDoc: Layout-Aware Prompting for Documents
Feb 15, 2024Recent advances in training large language models (LLMs) using massive amounts of solely textual data lead to strong generalization across many domains and tasks, including document-specific tasks. Opposed to that there is a trend to train multi-modal transformer architectures tailored for document understanding that are designed specifically to fuse textual inputs with the corresponding document layout. This involves a separate fine-tuning step for which additional training data is required. At present, no document transformers with comparable generalization to LLMs are available That raises the question which type of model is to be preferred for document understanding tasks. In this paper we investigate the possibility to use purely text-based LLMs for document-specific tasks by using layout enrichment. We explore drop-in modifications and rule-based methods to enrich purely textual LLM prompts with layout information. In our experiments we investigate the effects on the commercial ChatGPT model and the open-source LLM Solar. We demonstrate that using our approach both LLMs show improved performance on various standard document benchmarks. In addition, we study the impact of noisy OCR and layout errors, as well as the limitations of LLMs when it comes to utilizing document layout. Our results indicate that layout enrichment can improve the performance of purely text-based LLMs for document understanding by up to 15% compared to just using plain document text. In conclusion, this approach should be considered for the best model choice between text-based LLM or multi-modal document transformers.
TabAug: Data Driven Augmentation for Enhanced Table Structure Recognition
May 15, 2021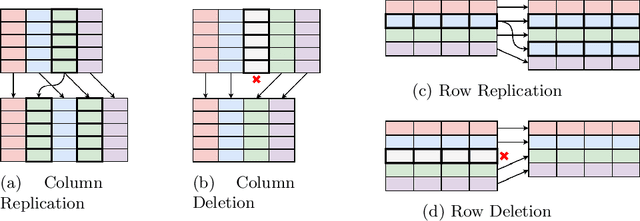
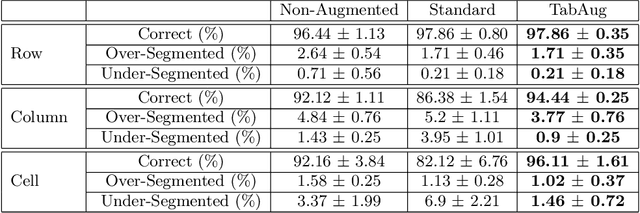
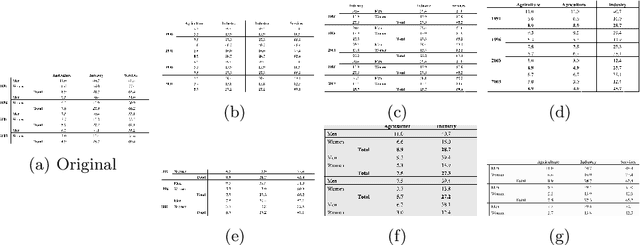
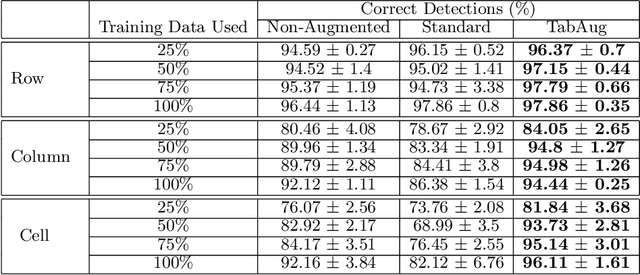
Table Structure Recognition is an essential part of end-to-end tabular data extraction in document images. The recent success of deep learning model architectures in computer vision remains to be non-reflective in table structure recognition, largely because extensive datasets for this domain are still unavailable while labeling new data is expensive and time-consuming. Traditionally, in computer vision, these challenges are addressed by standard augmentation techniques that are based on image transformations like color jittering and random cropping. As demonstrated by our experiments, these techniques are not effective for the task of table structure recognition. In this paper, we propose TabAug, a re-imagined Data Augmentation technique that produces structural changes in table images through replication and deletion of rows and columns. It also consists of a data-driven probabilistic model that allows control over the augmentation process. To demonstrate the efficacy of our approach, we perform experimentation on ICDAR 2013 dataset where our approach shows consistent improvements in all aspects of the evaluation metrics, with cell-level correct detections improving from 92.16% to 96.11% over the baseline.
Short-Term Load Forecasting using Bi-directional Sequential Models and Feature Engineering for Small Datasets
Nov 28, 2020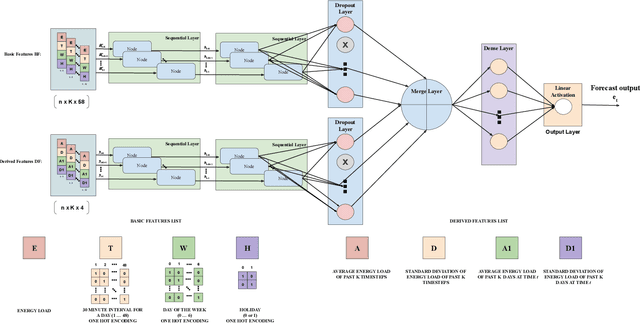

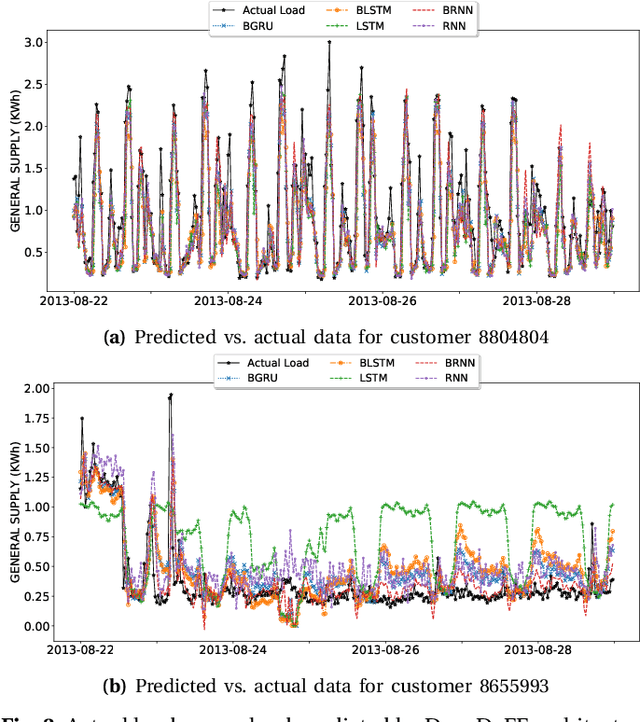
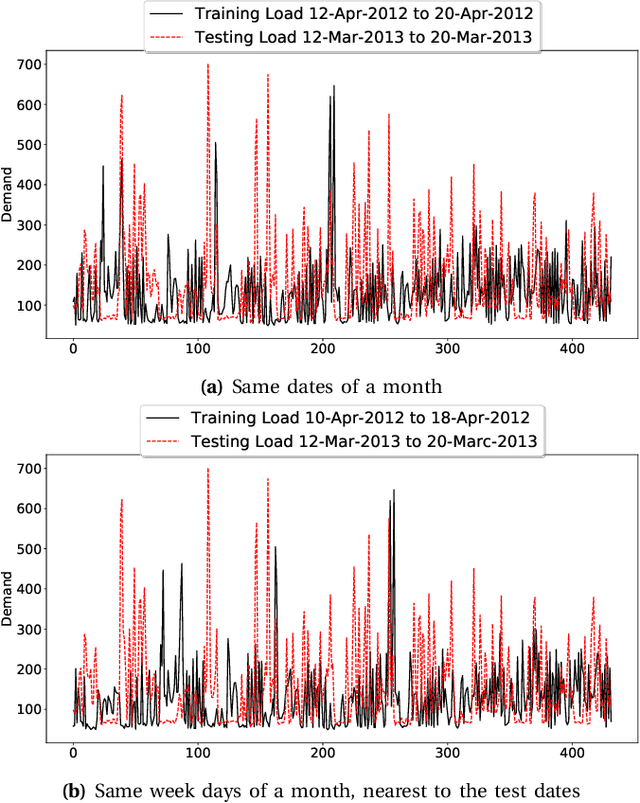
Electricity load forecasting enables the grid operators to optimally implement the smart grid's most essential features such as demand response and energy efficiency. Electricity demand profiles can vary drastically from one region to another on diurnal, seasonal and yearly scale. Hence to devise a load forecasting technique that can yield the best estimates on diverse datasets, specially when the training data is limited, is a big challenge. This paper presents a deep learning architecture for short-term load forecasting based on bidirectional sequential models in conjunction with feature engineering that extracts the hand-crafted derived features in order to aid the model for better learning and predictions. In the proposed architecture, named as Deep Derived Feature Fusion (DeepDeFF), the raw input and hand-crafted features are trained at separate levels and then their respective outputs are combined to make the final prediction. The efficacy of the proposed methodology is evaluated on datasets from five countries with completely different patterns. The results demonstrate that the proposed technique is superior to the existing state of the art.
Two-stage framework for optic disc localization and glaucoma classification in retinal fundus images using deep learning
May 28, 2020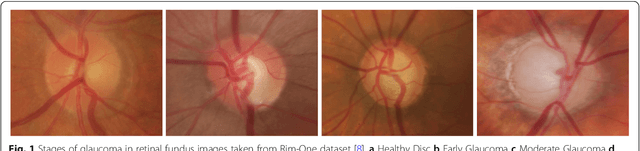
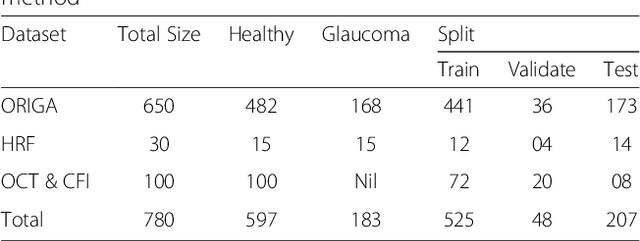

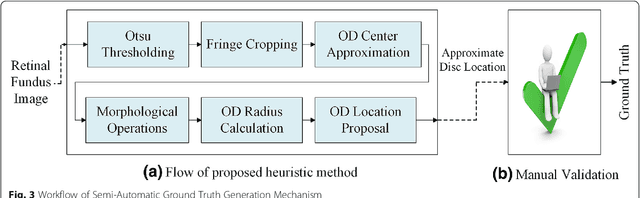
With the advancement of powerful image processing and machine learning techniques, CAD has become ever more prevalent in all fields of medicine including ophthalmology. Since optic disc is the most important part of retinal fundus image for glaucoma detection, this paper proposes a two-stage framework that first detects and localizes optic disc and then classifies it into healthy or glaucomatous. The first stage is based on RCNN and is responsible for localizing and extracting optic disc from a retinal fundus image while the second stage uses Deep CNN to classify the extracted disc into healthy or glaucomatous. In addition to the proposed solution, we also developed a rule-based semi-automatic ground truth generation method that provides necessary annotations for training RCNN based model for automated disc localization. The proposed method is evaluated on seven publicly available datasets for disc localization and on ORIGA dataset, which is the largest publicly available dataset for glaucoma classification. The results of automatic localization mark new state-of-the-art on six datasets with accuracy reaching 100% on four of them. For glaucoma classification we achieved AUC equal to 0.874 which is 2.7% relative improvement over the state-of-the-art results previously obtained for classification on ORIGA. Once trained on carefully annotated data, Deep Learning based methods for optic disc detection and localization are not only robust, accurate and fully automated but also eliminates the need for dataset-dependent heuristic algorithms. Our empirical evaluation of glaucoma classification on ORIGA reveals that reporting only AUC, for datasets with class imbalance and without pre-defined train and test splits, does not portray true picture of the classifier's performance and calls for additional performance metrics to substantiate the results.
* 16 Pages, 10 Figures
Table Structure Extraction with Bi-directional Gated Recurrent Unit Networks
Jan 08, 2020

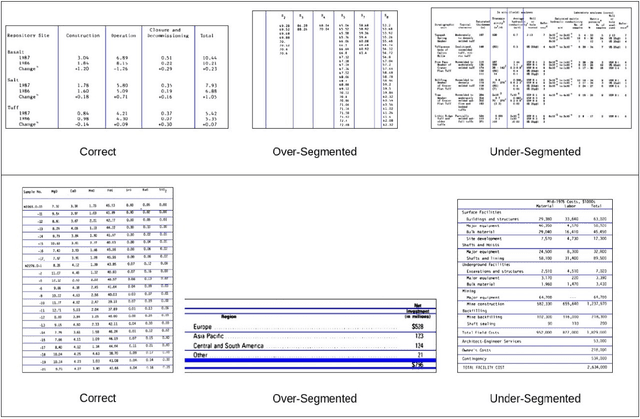
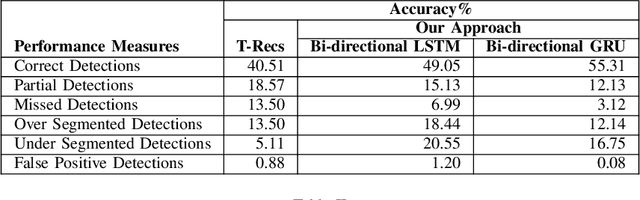
Tables present summarized and structured information to the reader, which makes table structure extraction an important part of document understanding applications. However, table structure identification is a hard problem not only because of the large variation in the table layouts and styles, but also owing to the variations in the page layouts and the noise contamination levels. A lot of research has been done to identify table structure, most of which is based on applying heuristics with the aid of optical character recognition (OCR) to hand pick layout features of the tables. These methods fail to generalize well because of the variations in the table layouts and the errors generated by OCR. In this paper, we have proposed a robust deep learning based approach to extract rows and columns from a detected table in document images with a high precision. In the proposed solution, the table images are first pre-processed and then fed to a bi-directional Recurrent Neural Network with Gated Recurrent Units (GRU) followed by a fully-connected layer with soft max activation. The network scans the images from top-to-bottom as well as left-to-right and classifies each input as either a row-separator or a column-separator. We have benchmarked our system on publicly available UNLV as well as ICDAR 2013 datasets on which it outperformed the state-of-the-art table structure extraction systems by a significant margin.
Do Cross Modal Systems Leverage Semantic Relationships?
Sep 03, 2019
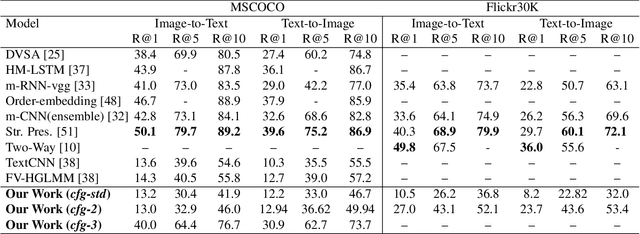


Current cross-modal retrieval systems are evaluated using R@K measure which does not leverage semantic relationships rather strictly follows the manually marked image text query pairs. Therefore, current systems do not generalize well for the unseen data in the wild. To handle this, we propose a new measure, SemanticMap, to evaluate the performance of cross-modal systems. Our proposed measure evaluates the semantic similarity between the image and text representations in the latent embedding space. We also propose a novel cross-modal retrieval system using a single stream network for bidirectional retrieval. The proposed system is based on a deep neural network trained using extended center loss, minimizing the distance of image and text descriptions in the latent space from the class centers. In our system, the text descriptions are also encoded as images which enabled us to use a single stream network for both text and images. To the best of our knowledge, our work is the first of its kind in terms of employing a single stream network for cross-modal retrieval systems. The proposed system is evaluated on two publicly available datasets including MSCOCO and Flickr30K and has shown comparable results to the current state-of-the-art methods.
An Open-World Extension to Knowledge Graph Completion Models
Jun 19, 2019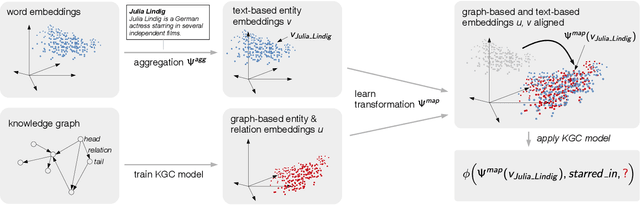
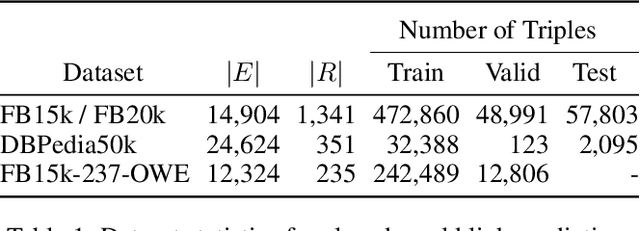
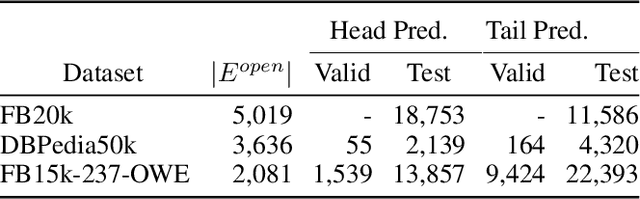
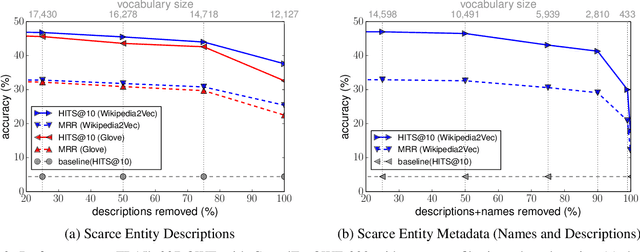
We present a novel extension to embedding-based knowledge graph completion models which enables them to perform open-world link prediction, i.e. to predict facts for entities unseen in training based on their textual description. Our model combines a regular link prediction model learned from a knowledge graph with word embeddings learned from a textual corpus. After training both independently, we learn a transformation to map the embeddings of an entity's name and description to the graph-based embedding space. In experiments on several datasets including FB20k, DBPedia50k and our new dataset FB15k-237-OWE, we demonstrate competitive results. Particularly, our approach exploits the full knowledge graph structure even when textual descriptions are scarce, does not require a joint training on graph and text, and can be applied to any embedding-based link prediction model, such as TransE, ComplEx and DistMult.
Rethinking Table Parsing using Graph Neural Networks
May 31, 2019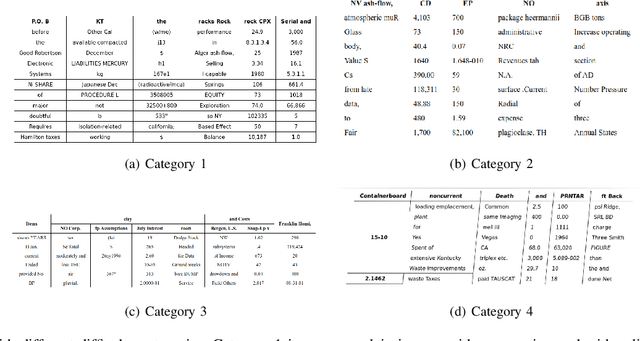
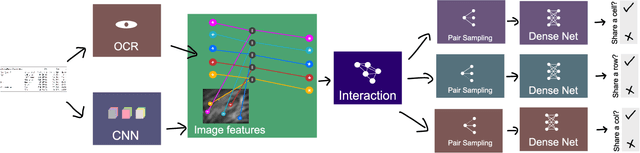
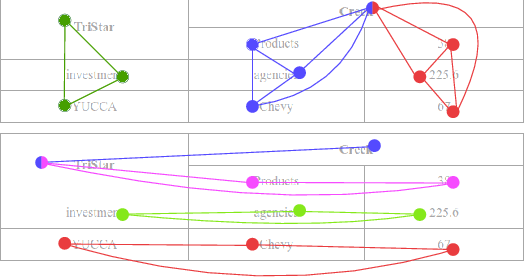
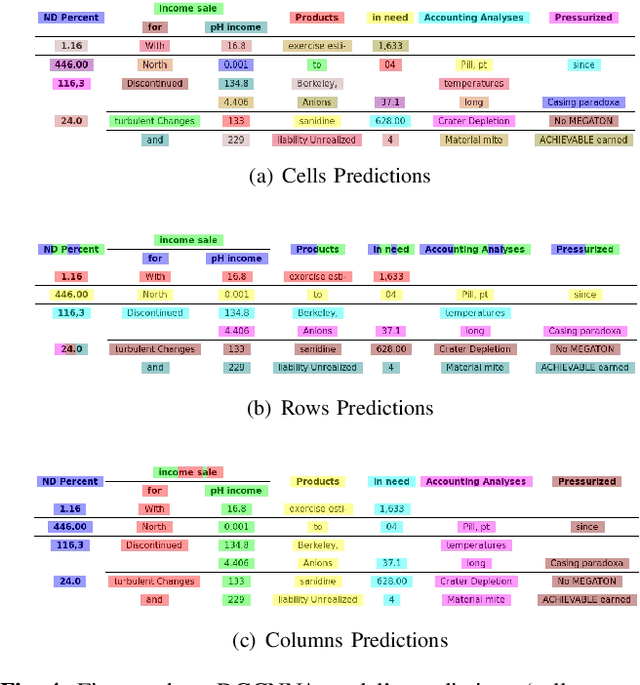
Document structure analysis, such as zone segmentation and table parsing, is a complex problem in document processing and is an active area of research. The recent success of deep learning in solving various computer vision and machine learning problems has not been reflected in document structure analysis since conventional neural networks are not well suited to the input structure of the problem. In this paper, we propose an architecture based on graph networks as a better alternative to standard neural networks for table parsing. We argue that graph networks are a more natural choice for these problems, and explore two gradient-based graph neural networks. Our proposed architecture combines the benefits of convolutional neural networks for visual feature extraction and graph networks for dealing with the problem structure. We empirically demonstrate that our method outperforms the baseline by a significant margin. In addition, we identify the lack of large scale datasets as a major hindrance for deep learning research for structure analysis, and present a new large scale synthetic dataset for the problem of table parsing. Finally, we open-source our implementation of dataset generation and the training framework of our graph networks to promote reproducible research in this direction.
Converting a Common Document Scanner to a Multispectral Scanner
Apr 17, 2019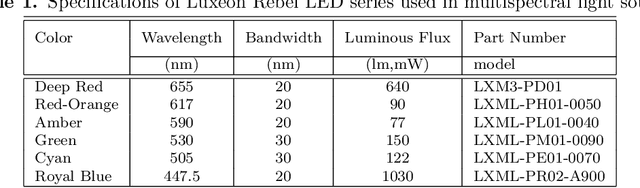



We propose the construction of a prototype scanner designed to capture multispectral images of documents. A standard sheet-feed scanner is modified by disconnecting its internal light source and connecting an external multispectral light source comprising of narrow band light emitting diodes (LED). A document is scanned by illuminating the scanner light guide successively with different LEDs and capturing a scan of the document. The system is portable and can be used for potential applications in verification of questioned documents, cheques, receipts and bank notes.