 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocDjinn: Controllable Synthetic Document Generation with VLMs and Handwriting Diffusion
Feb 25, 2026Effective document intelligence models rely on large amounts of annotated training data. However, procuring sufficient and high-quality data poses significant challenges due to the labor-intensive and costly nature of data acquisition. Additionally, leveraging language models to annotate real documents raises concerns about data privacy. Synthetic document generation has emerged as a promising, privacy-preserving alternative. We propose DocDjinn, a novel framework for controllable synthetic document generation using Vision-Language Models (VLMs) that produces annotated documents from unlabeled seed samples. Our approach generates visually plausible and semantically consistent synthetic documents that follow the distribution of an existing source dataset through clustering-based seed selection with parametrized sampling. By enriching documents with realistic diffusion-based handwriting and contextual visual elements via semantic-visual decoupling, we generate diverse, high-quality annotated synthetic documents. We evaluate across eleven benchmarks spanning key information extraction, question answering, document classification, and document layout analysis. To our knowledge, this is the first work demonstrating that VLMs can generate faithful annotated document datasets at scale from unlabeled seeds that can effectively enrich or approximate real, manually annotated data for diverse document understanding tasks. We show that with only 100 real training samples, our framework achieves on average $87\%$ of the performance of the full real-world dataset. We publicly release our code and 140k+ synthetic document samples.
Vocalics in Human-Drone Interaction
Dec 29, 2023As the presence of flying robots continues to grow in both commercial and private sectors, it necessitates an understanding of appropriate methods for nonverbal interaction with humans. While visual cues, such as gestures incorporated into trajectories, are more apparent and thoroughly researched, acoustic cues have remained unexplored, despite their potential to enhance human-drone interaction. Given that additional audiovisual and sensory equipment is not always desired or practicable, and flight noise often masks potential acoustic communication in rotary-wing drones, such as through a loudspeaker, the rotors themselves offer potential for nonverbal communication. In this paper, quadrotor trajectories are augmented by acoustic information that does not visually affect the flight, but adds audible information that significantly facilitates distinctiveness. A user study (N=192) demonstrates that sonically augmenting the trajectories of two aerial gestures makes them more easily distinguishable. This enhancement contributes to human-drone interaction through onboard means, particularly in situations where the human cannot see or look at the drone.
Real-time Light Estimation and Neural Soft Shadows for AR Indoor Scenarios
Aug 03, 2023We present a pipeline for realistic embedding of virtual objects into footage of indoor scenes with focus on real-time AR applications. Our pipeline consists of two main components: A light estimator and a neural soft shadow texture generator. Our light estimation is based on deep neural nets and determines the main light direction, light color, ambient color and an opacity parameter for the shadow texture. Our neural soft shadow method encodes object-based realistic soft shadows as light direction dependent textures in a small MLP. We show that our pipeline can be used to integrate objects into AR scenes in a new level of realism in real-time. Our models are small enough to run on current mobile devices. We achieve runtimes of 9ms for light estimation and 5ms for neural shadows on an iPhone 11 Pro.
Addressing Leakage in Self-Supervised Contextualized Code Retrieval
Apr 17, 2022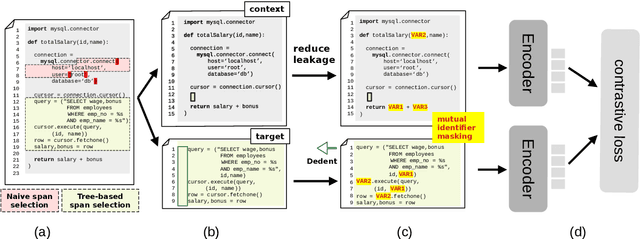
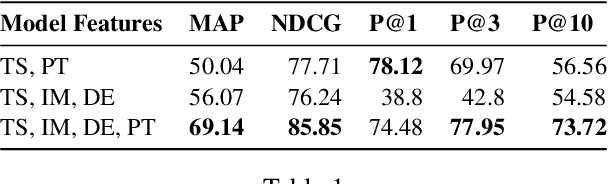
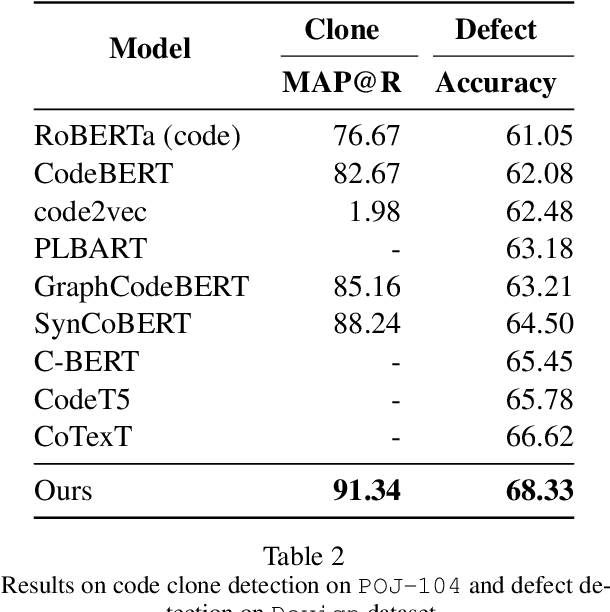
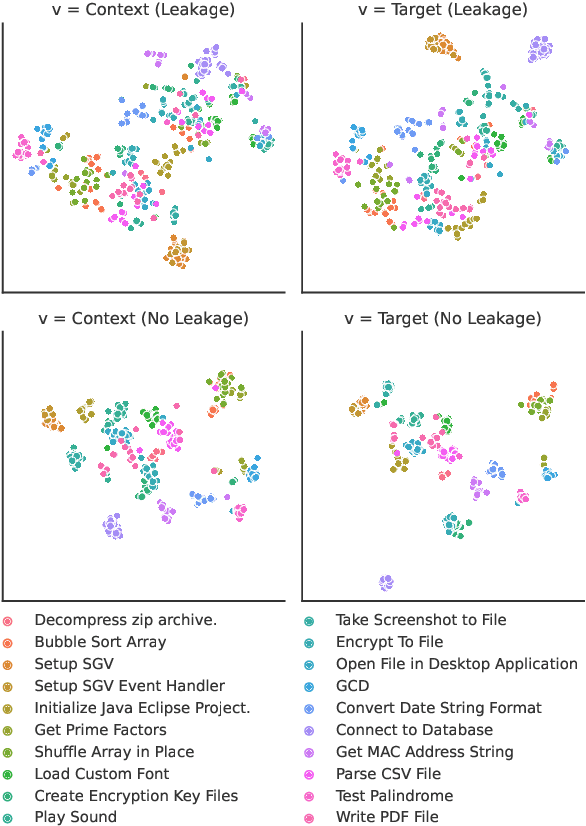
We address contextualized code retrieval, the search for code snippets helpful to fill gaps in a partial input program. Our approach facilitates a large-scale self-supervised contrastive training by splitting source code randomly into contexts and targets. To combat leakage between the two, we suggest a novel approach based on mutual identifier masking, dedentation, and the selection of syntax-aligned targets. Our second contribution is a new dataset for direct evaluation of contextualized code retrieval, based on a dataset of manually aligned subpassages of code clones. Our experiments demonstrate that our approach improves retrieval substantially, and yields new state-of-the-art results for code clone and defect detection.
NeuralQAAD: An Efficient Differentiable Framework for High Resolution Point Cloud Compression
Dec 15, 2020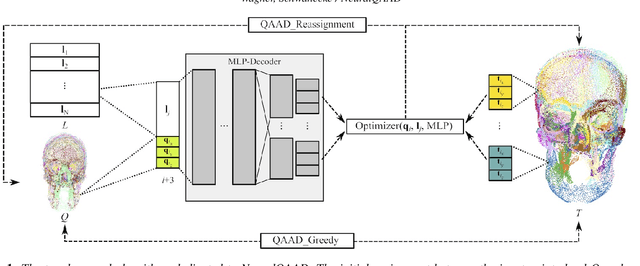
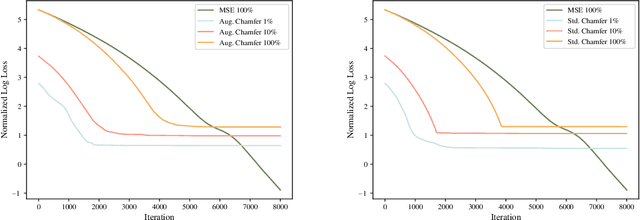
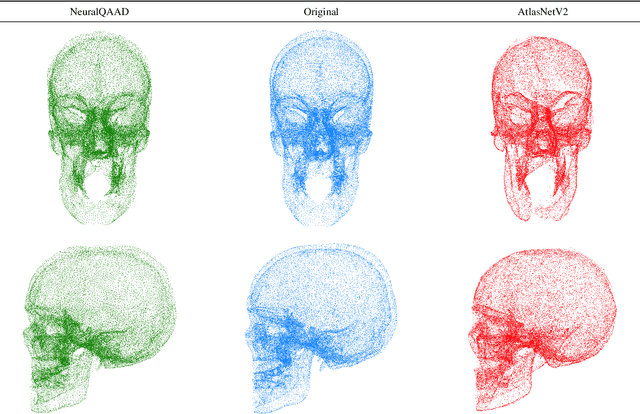

In this paper, we propose NeuralQAAD, a differentiable point cloud compression framework that is fast, robust to sampling, and applicable to high resolutions. Previous work that is able to handle complex and non-smooth topologies is hardly scaleable to more than just a few thousand points. We tackle the task with a novel neural network architecture characterized by weight sharing and autodecoding. Our architecture uses parameters much more efficiently than previous work, allowing us to be deeper and scalable. Futhermore, we show that the currently only tractable training criterion for point cloud compression, the Chamfer distance, performances poorly for high resolutions. To overcome this issue, we pair our architecture with a new training procedure based upon a quadratic assignment problem (QAP) for which we state two approximation algorithms. We solve the QAP in parallel to gradient descent. This procedure acts as a surrogate loss and allows to implicitly minimize the more expressive Earth Movers Distance (EMD) even for point clouds with way more than $10^6$ points. As evaluating the EMD on high resolution point clouds is intractable, we propose a divide-and-conquer approach based on k-d trees, the EM-kD, as a scaleable and fast but still reliable upper bound for the EMD. NeuralQAAD is demonstrated on COMA, D-FAUST, and Skulls to significantly outperform the current state-of-the-art visually and in terms of the EM-kD. Skulls is a novel dataset of skull CT-scans which we will make publicly available together with our implementation of NeuralQAAD.
An Open-World Extension to Knowledge Graph Completion Models
Jun 19, 2019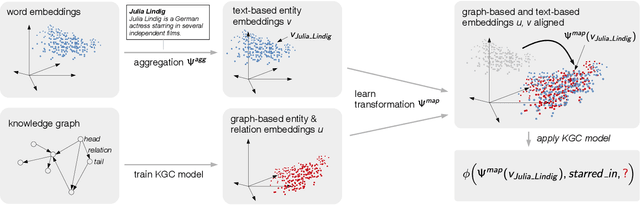
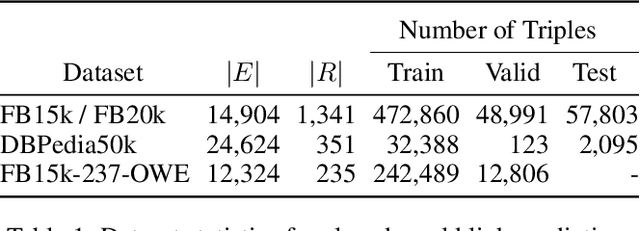
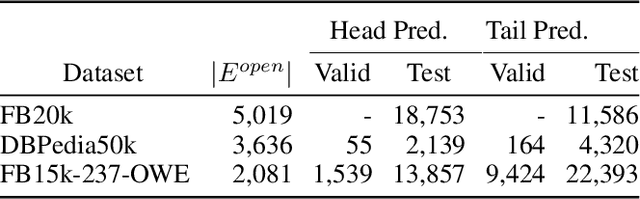
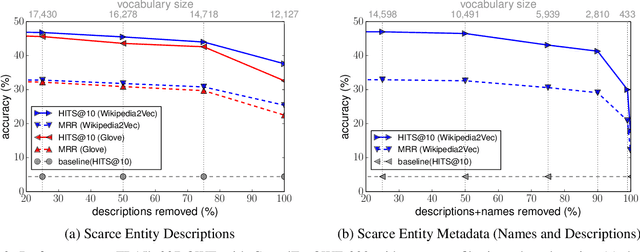
We present a novel extension to embedding-based knowledge graph completion models which enables them to perform open-world link prediction, i.e. to predict facts for entities unseen in training based on their textual description. Our model combines a regular link prediction model learned from a knowledge graph with word embeddings learned from a textual corpus. After training both independently, we learn a transformation to map the embeddings of an entity's name and description to the graph-based embedding space. In experiments on several datasets including FB20k, DBPedia50k and our new dataset FB15k-237-OWE, we demonstrate competitive results. Particularly, our approach exploits the full knowledge graph structure even when textual descriptions are scarce, does not require a joint training on graph and text, and can be applied to any embedding-based link prediction model, such as TransE, ComplEx and DistMult.
A method for automatic forensic facial reconstruction based on dense statistics of soft tissue thickness
Aug 22, 2018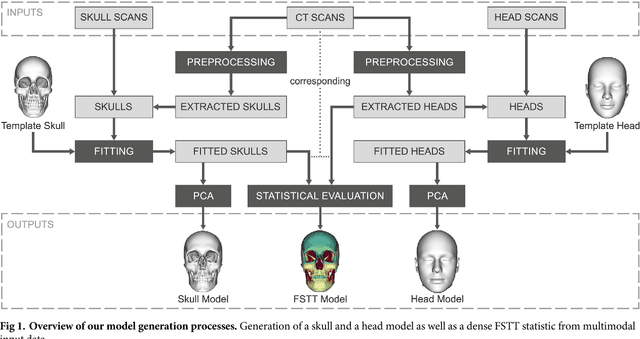
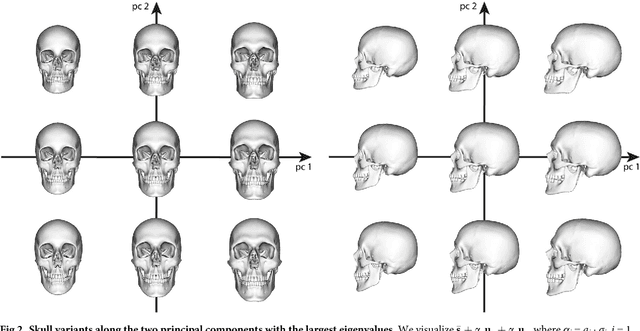
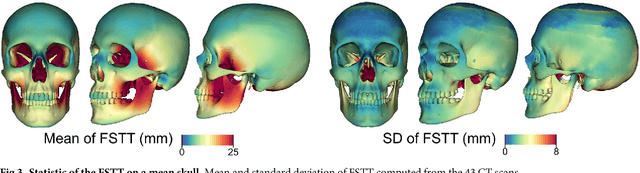
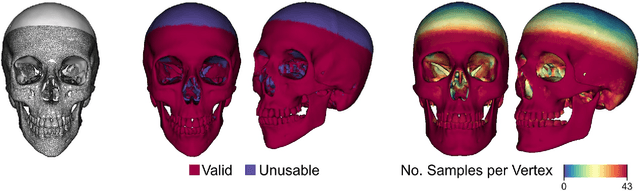
In this paper, we present a method for automated estimation of a human face given a skull remain. The proposed method is based on three statistical models. A volumetric (tetrahedral) skull model encoding the variations of different skulls, a surface head model encoding the head variations, and a dense statistic of facial soft tissue thickness (FSTT). All data are automatically derived from computed tomography (CT) head scans and optical face scans. In order to obtain a proper dense FSTT statistic, we register a skull model to each skull extracted from a CT scan and determine the FSTT value for each vertex of the skull model towards the associated extracted skin surface. The FSTT values at predefined landmarks from our statistic are well in agreement with data from the literature. To recover a face from a skull remain, we first fit our skull model to the given skull. Next, we generate spheres with radius of the respective FSTT value obtained from our statistic at each vertex of the registered skull. Finally, we fit a head model to the union of all spheres. The proposed automated method enables a probabilistic face-estimation that facilitates forensic recovery even from incomplete skull remains. The FSTT statistic allows the generation of plausible head variants, which can be adjusted intuitively using principal component analysis. We validate our face recovery process using an anonymized head CT scan. The estimation generated from the given skull visually compares well with the skin surface extracted from the CT scan itself.
A Gauss-Newton Approach to Real-Time Monocular Multiple Object Tracking
Jul 05, 2018


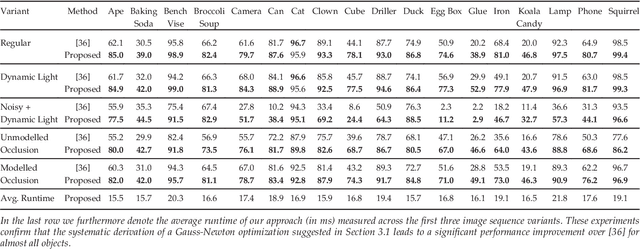
We propose an algorithm for real-time 6DOF pose tracking of rigid 3D objects using a monocular RGB camera. The key idea is to derive a region-based cost function using temporally consistent local color histograms. While such region-based cost functions are commonly optimized using first-order gradient descent techniques, we systematically derive a Gauss-Newton optimization scheme which gives rise to drastically faster convergence and highly accurate and robust tracking performance. We furthermore propose a novel complex dataset dedicated for the task of monocular object pose tracking and make it publicly available to the community. To our knowledge, It is the first to address the common and important scenario in which both the camera as well as the objects are moving simultaneously in cluttered scenes. In numerous experiments - including our own proposed data set - we demonstrate that the proposed Gauss-Newton approach outperforms existing approaches, in particular in the presence of cluttered backgrounds, heterogeneous objects and partial occlusions.