 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Light Estimation and Neural Soft Shadows for AR Indoor Scenarios
Aug 03, 2023We present a pipeline for realistic embedding of virtual objects into footage of indoor scenes with focus on real-time AR applications. Our pipeline consists of two main components: A light estimator and a neural soft shadow texture generator. Our light estimation is based on deep neural nets and determines the main light direction, light color, ambient color and an opacity parameter for the shadow texture. Our neural soft shadow method encodes object-based realistic soft shadows as light direction dependent textures in a small MLP. We show that our pipeline can be used to integrate objects into AR scenes in a new level of realism in real-time. Our models are small enough to run on current mobile devices. We achieve runtimes of 9ms for light estimation and 5ms for neural shadows on an iPhone 11 Pro.
Local-Area-Learning Network: Meaningful Local Areas for Efficient Point Cloud Analysis
Jun 12, 2020

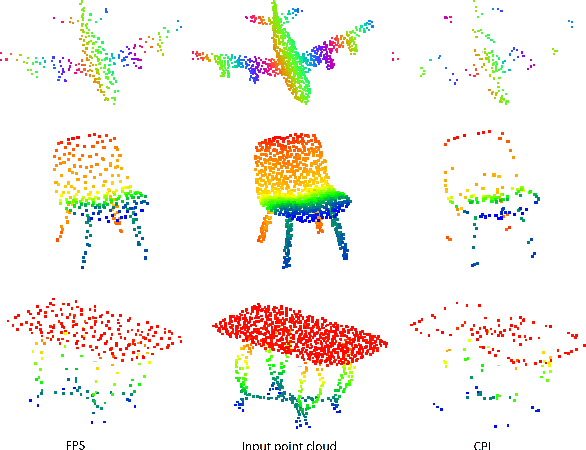

Research in point cloud analysis with deep neural networks has made rapid progress in recent years. The pioneering work PointNet offered a direct analysis of point clouds. However, due to its architecture PointNet is not able to capture local structures. To overcome this drawback, the same authors have developed PointNet++ by applying PointNet to local areas. The local areas are defined by center points and their neighbors. In PointNet++ and its further developments the center points are determined with a Farthest Point Sampling (FPS) algorithm. This has the disadvantage that the center points in general do not have meaningful local areas. In this paper, we introduce the neural Local-Area-Learning Network (LocAL-Net) which places emphasis on the selection and characterization of the local areas. Our approach learns critical points that we use as center points. In order to strengthen the recognition of local structures, the points are given additional metric properties depending on the local areas. Finally, we derive and combine two global feature vectors, one from the whole point cloud and one from all local areas. Experiments on the datasets ModelNet10/40 and ShapeNet show that LocAL-Net is competitive for part segmentation. For classification LocAL-Net outperforms the state-of-the-arts.
A method for automatic forensic facial reconstruction based on dense statistics of soft tissue thickness
Aug 22, 2018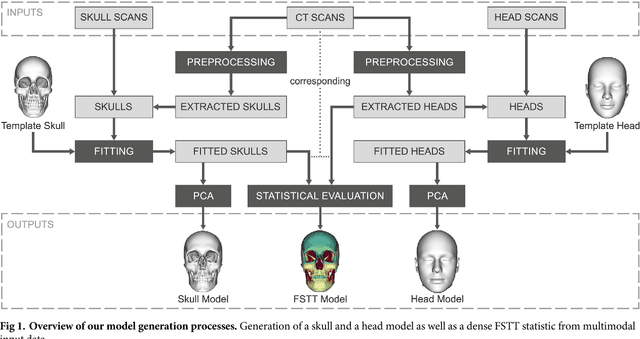
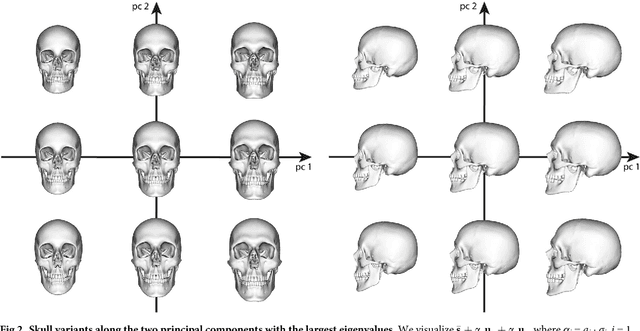
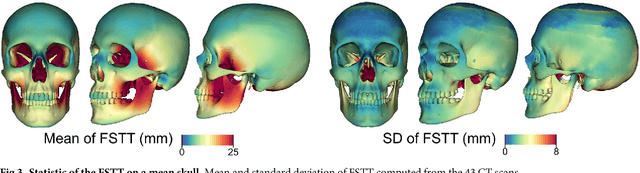
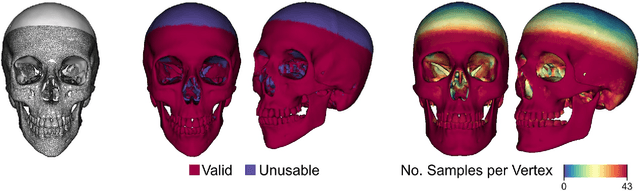
In this paper, we present a method for automated estimation of a human face given a skull remain. The proposed method is based on three statistical models. A volumetric (tetrahedral) skull model encoding the variations of different skulls, a surface head model encoding the head variations, and a dense statistic of facial soft tissue thickness (FSTT). All data are automatically derived from computed tomography (CT) head scans and optical face scans. In order to obtain a proper dense FSTT statistic, we register a skull model to each skull extracted from a CT scan and determine the FSTT value for each vertex of the skull model towards the associated extracted skin surface. The FSTT values at predefined landmarks from our statistic are well in agreement with data from the literature. To recover a face from a skull remain, we first fit our skull model to the given skull. Next, we generate spheres with radius of the respective FSTT value obtained from our statistic at each vertex of the registered skull. Finally, we fit a head model to the union of all spheres. The proposed automated method enables a probabilistic face-estimation that facilitates forensic recovery even from incomplete skull remains. The FSTT statistic allows the generation of plausible head variants, which can be adjusted intuitively using principal component analysis. We validate our face recovery process using an anonymized head CT scan. The estimation generated from the given skull visually compares well with the skin surface extracted from the CT scan itself.
A Gauss-Newton Approach to Real-Time Monocular Multiple Object Tracking
Jul 05, 2018


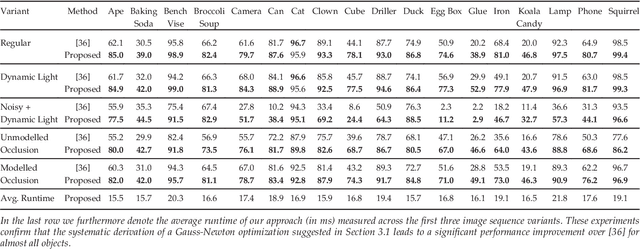
We propose an algorithm for real-time 6DOF pose tracking of rigid 3D objects using a monocular RGB camera. The key idea is to derive a region-based cost function using temporally consistent local color histograms. While such region-based cost functions are commonly optimized using first-order gradient descent techniques, we systematically derive a Gauss-Newton optimization scheme which gives rise to drastically faster convergence and highly accurate and robust tracking performance. We furthermore propose a novel complex dataset dedicated for the task of monocular object pose tracking and make it publicly available to the community. To our knowledge, It is the first to address the common and important scenario in which both the camera as well as the objects are moving simultaneously in cluttered scenes. In numerous experiments - including our own proposed data set - we demonstrate that the proposed Gauss-Newton approach outperforms existing approaches, in particular in the presence of cluttered backgrounds, heterogeneous objects and partial occlusions.