 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Leakage in Self-Supervised Contextualized Code Retrieval
Apr 17, 2022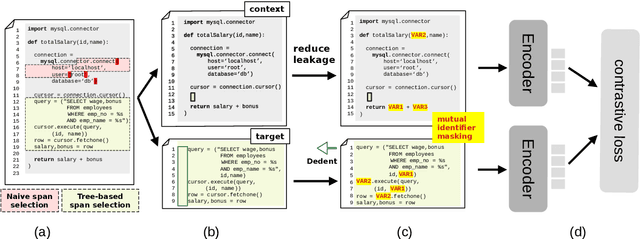
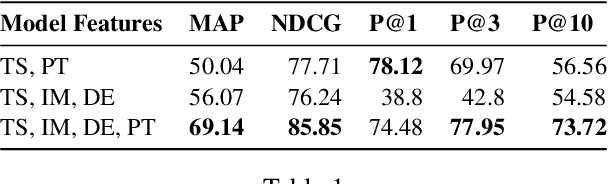
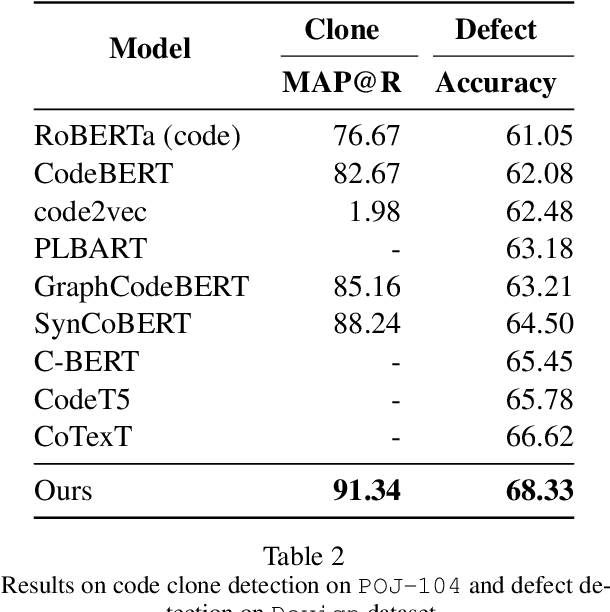
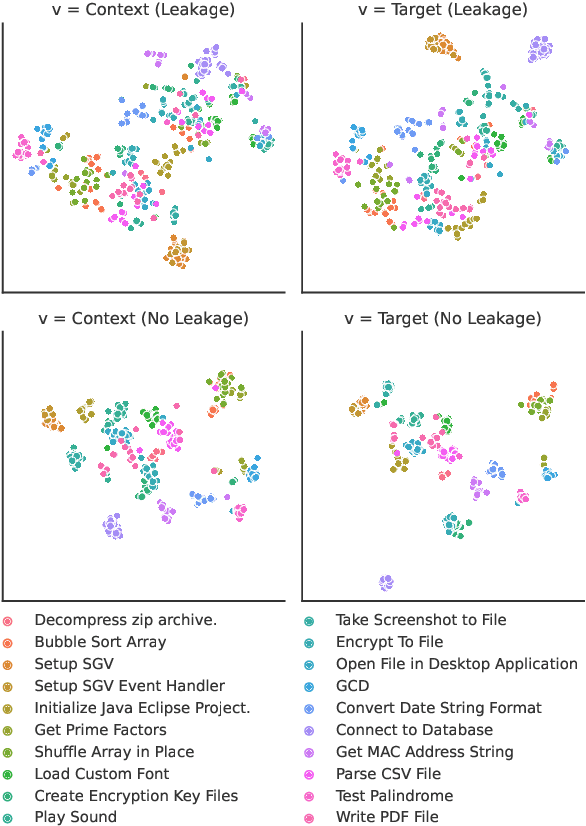
We address contextualized code retrieval, the search for code snippets helpful to fill gaps in a partial input program. Our approach facilitates a large-scale self-supervised contrastive training by splitting source code randomly into contexts and targets. To combat leakage between the two, we suggest a novel approach based on mutual identifier masking, dedentation, and the selection of syntax-aligned targets. Our second contribution is a new dataset for direct evaluation of contextualized code retrieval, based on a dataset of manually aligned subpassages of code clones. Our experiments demonstrate that our approach improves retrieval substantially, and yields new state-of-the-art results for code clone and defect detection.
An Open-World Extension to Knowledge Graph Completion Models
Jun 19, 2019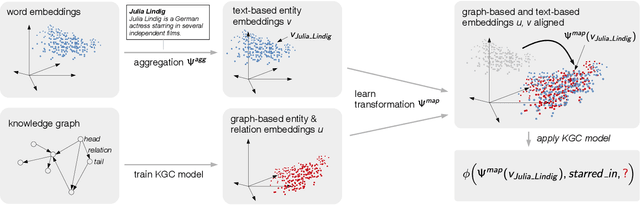
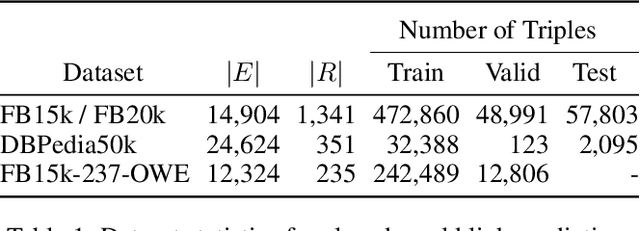
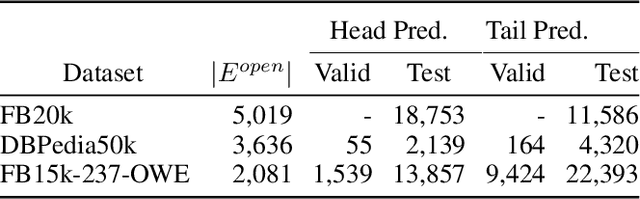
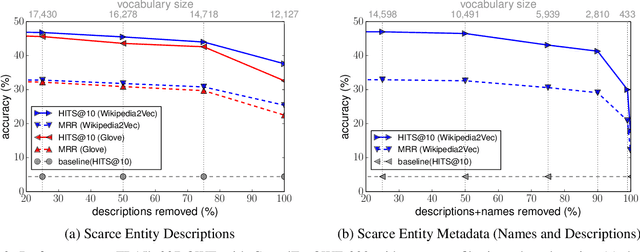
We present a novel extension to embedding-based knowledge graph completion models which enables them to perform open-world link prediction, i.e. to predict facts for entities unseen in training based on their textual description. Our model combines a regular link prediction model learned from a knowledge graph with word embeddings learned from a textual corpus. After training both independently, we learn a transformation to map the embeddings of an entity's name and description to the graph-based embedding space. In experiments on several datasets including FB20k, DBPedia50k and our new dataset FB15k-237-OWE, we demonstrate competitive results. Particularly, our approach exploits the full knowledge graph structure even when textual descriptions are scarce, does not require a joint training on graph and text, and can be applied to any embedding-based link prediction model, such as TransE, ComplEx and DistMult.