 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulticalibration for LLM-based Code Generation
Dec 09, 2025As AI-based code generation becomes widespread, researchers are investigating the calibration of code LLMs - ensuring their confidence scores faithfully represent the true likelihood of code correctness. To do so, we investigate multicalibration, which can capture additional factors about a coding problem, such as complexity, code length, or programming language used. We study four multicalibration approaches on three function synthesis benchmarks, using latest-generation code LLMs (Qwen3 Coder, GPT-OSS, DeepSeek-R1-Distill). Our results demonstrate that multicalibration can yield distinct improvements over both uncalibrated token likelihoods (+1.03 in skill score) and baseline calibrations (+0.37 in skill score). We study the influence of the aforementioned factors in ablations, and make our dataset (consisting of code generations, likelihoods, and correctness labels) available for future research on code LLM calibration.
Addressing Leakage in Self-Supervised Contextualized Code Retrieval
Apr 17, 2022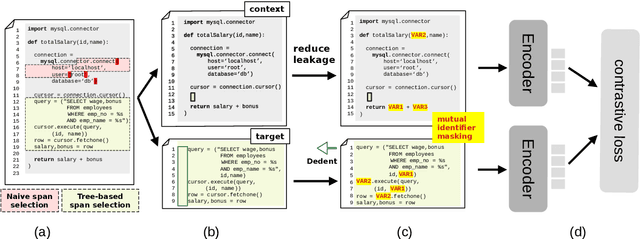
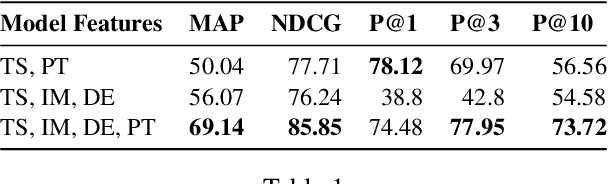
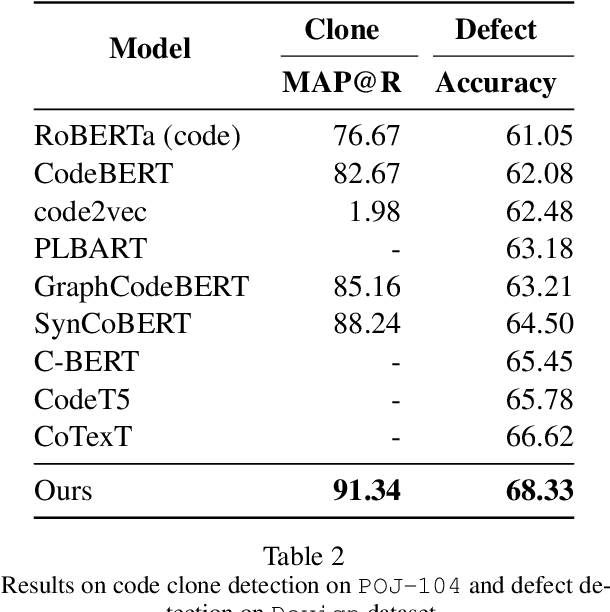
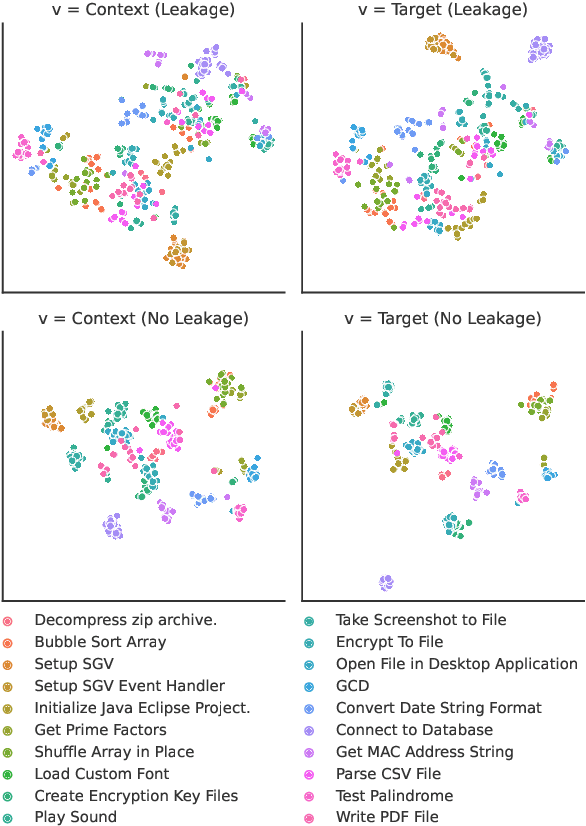
We address contextualized code retrieval, the search for code snippets helpful to fill gaps in a partial input program. Our approach facilitates a large-scale self-supervised contrastive training by splitting source code randomly into contexts and targets. To combat leakage between the two, we suggest a novel approach based on mutual identifier masking, dedentation, and the selection of syntax-aligned targets. Our second contribution is a new dataset for direct evaluation of contextualized code retrieval, based on a dataset of manually aligned subpassages of code clones. Our experiments demonstrate that our approach improves retrieval substantially, and yields new state-of-the-art results for code clone and defect detection.