 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAFIS: Dataset + Framework to assess occupational Bias and Human Preference in modern Text-to-image Models
Jun 18, 2026Generative artificial intelligence has the potential to improve productivity and transform the production of creative content. However, existing research indicates that image generation models are significantly influenced by biases. This work investigates the inherent biases and language-induced biases present in text-to-image models within the context of occupation-related image generation, complementing established metrics with human preference feedback. We present a comprehensive evaluation of five current text-to-image models: Midjourney v6.1, Stable Diffusion 3 Medium, DALL-E 3, Playground v2.5, and FLUX.1-dev , focusing on gender and ethnicity bias, image quality, and prompt alignment. To facilitate this evaluation, we developed the "Battle-Arena for Fair Image Synthesis" (BAFIS), a platform designed to collect human feedback on bias in generated images. Furthermore, we created a dataset comprising 21,140 synthetic images generated using multilingual prompts, which serves as a basis for our analysis. We further place our results within a broader social context by comparing them to official statistics from the German Federal Employment Agency. Our findings reveal systematic biases in text-to-image models, with established evaluation metrics in partial correlation with subjective user ratings. Thus, our research emphasizes the need for including human preferences to develop fairer and more inclusive text-to-image models.
Agentic Insight Generation in VSM Simulations
Apr 14, 2026Extracting actionable insights from complex value stream map simulations can be challenging, time-consuming, and error-prone. Recent advances in large language models offer new avenues to support users with this task. While existing approaches excel at processing raw data to gain information, they are structurally unfit to pick up on subtle situational differences needed to distinguish similar data sources in this domain. To address this issue, we propose a decoupled, two-step agentic architecture. By separating orchestration from data analysis, the system leverages progressive data discovery infused with domain expert knowledge. This architecture allows the orchestration to intelligently select data sources and perform multi-hop reasoning across data structures while maintaining a slim internal context. Results from multiple state-of-the-art large language models demonstrate the framework's viability: with top-tier models achieving accuracies of up to 86% and demonstrating high robustness across evaluation runs.
DocDjinn: Controllable Synthetic Document Generation with VLMs and Handwriting Diffusion
Feb 25, 2026Effective document intelligence models rely on large amounts of annotated training data. However, procuring sufficient and high-quality data poses significant challenges due to the labor-intensive and costly nature of data acquisition. Additionally, leveraging language models to annotate real documents raises concerns about data privacy. Synthetic document generation has emerged as a promising, privacy-preserving alternative. We propose DocDjinn, a novel framework for controllable synthetic document generation using Vision-Language Models (VLMs) that produces annotated documents from unlabeled seed samples. Our approach generates visually plausible and semantically consistent synthetic documents that follow the distribution of an existing source dataset through clustering-based seed selection with parametrized sampling. By enriching documents with realistic diffusion-based handwriting and contextual visual elements via semantic-visual decoupling, we generate diverse, high-quality annotated synthetic documents. We evaluate across eleven benchmarks spanning key information extraction, question answering, document classification, and document layout analysis. To our knowledge, this is the first work demonstrating that VLMs can generate faithful annotated document datasets at scale from unlabeled seeds that can effectively enrich or approximate real, manually annotated data for diverse document understanding tasks. We show that with only 100 real training samples, our framework achieves on average $87\%$ of the performance of the full real-world dataset. We publicly release our code and 140k+ synthetic document samples.
Multicalibration for LLM-based Code Generation
Dec 09, 2025As AI-based code generation becomes widespread, researchers are investigating the calibration of code LLMs - ensuring their confidence scores faithfully represent the true likelihood of code correctness. To do so, we investigate multicalibration, which can capture additional factors about a coding problem, such as complexity, code length, or programming language used. We study four multicalibration approaches on three function synthesis benchmarks, using latest-generation code LLMs (Qwen3 Coder, GPT-OSS, DeepSeek-R1-Distill). Our results demonstrate that multicalibration can yield distinct improvements over both uncalibrated token likelihoods (+1.03 in skill score) and baseline calibrations (+0.37 in skill score). We study the influence of the aforementioned factors in ablations, and make our dataset (consisting of code generations, likelihoods, and correctness labels) available for future research on code LLM calibration.
Integrating Expert Labels into LLM-based Emission Goal Detection: Example Selection vs Automatic Prompt Design
Dec 09, 2024We address the detection of emission reduction goals in corporate reports, an important task for monitoring companies' progress in addressing climate change. Specifically, we focus on the issue of integrating expert feedback in the form of labeled example passages into LLM-based pipelines, and compare the two strategies of (1) a dynamic selection of few-shot examples and (2) the automatic optimization of the prompt by the LLM itself. Our findings on a public dataset of 769 climate-related passages from real-world business reports indicate that automatic prompt optimization is the superior approach, while combining both methods provides only limited benefit. Qualitative results indicate that optimized prompts do indeed capture many intricacies of the targeted emission goal extraction task.
LAPDoc: Layout-Aware Prompting for Documents
Feb 15, 2024Recent advances in training large language models (LLMs) using massive amounts of solely textual data lead to strong generalization across many domains and tasks, including document-specific tasks. Opposed to that there is a trend to train multi-modal transformer architectures tailored for document understanding that are designed specifically to fuse textual inputs with the corresponding document layout. This involves a separate fine-tuning step for which additional training data is required. At present, no document transformers with comparable generalization to LLMs are available That raises the question which type of model is to be preferred for document understanding tasks. In this paper we investigate the possibility to use purely text-based LLMs for document-specific tasks by using layout enrichment. We explore drop-in modifications and rule-based methods to enrich purely textual LLM prompts with layout information. In our experiments we investigate the effects on the commercial ChatGPT model and the open-source LLM Solar. We demonstrate that using our approach both LLMs show improved performance on various standard document benchmarks. In addition, we study the impact of noisy OCR and layout errors, as well as the limitations of LLMs when it comes to utilizing document layout. Our results indicate that layout enrichment can improve the performance of purely text-based LLMs for document understanding by up to 15% compared to just using plain document text. In conclusion, this approach should be considered for the best model choice between text-based LLM or multi-modal document transformers.
IRT2: Inductive Linking and Ranking in Knowledge Graphs of Varying Scale
Jan 02, 2023We address the challenge of building domain-specific knowledge models for industrial use cases, where labelled data and taxonomic information is initially scarce. Our focus is on inductive link prediction models as a basis for practical tools that support knowledge engineers with exploring text collections and discovering and linking new (so-called open-world) entities to the knowledge graph. We argue that - though neural approaches to text mining have yielded impressive results in the past years - current benchmarks do not reflect the typical challenges encountered in the industrial wild properly. Therefore, our first contribution is an open benchmark coined IRT2 (inductive reasoning with text) that (1) covers knowledge graphs of varying sizes (including very small ones), (2) comes with incidental, low-quality text mentions, and (3) includes not only triple completion but also ranking, which is relevant for supporting experts with discovery tasks. We investigate two neural models for inductive link prediction, one based on end-to-end learning and one that learns from the knowledge graph and text data in separate steps. These models compete with a strong bag-of-words baseline. The results show a significant advance in performance for the neural approaches as soon as the available graph data decreases for linking. For ranking, the results are promising, and the neural approaches outperform the sparse retriever by a wide margin.
Addressing Leakage in Self-Supervised Contextualized Code Retrieval
Apr 17, 2022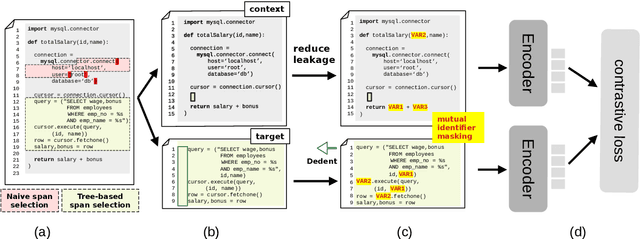
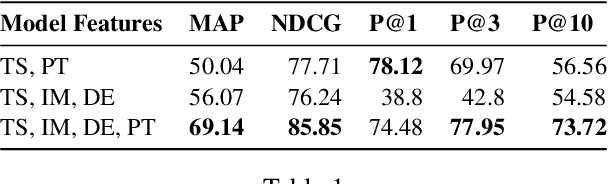
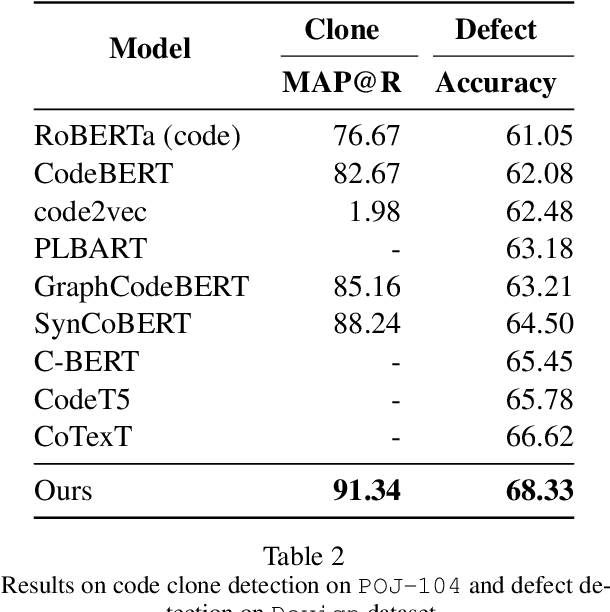
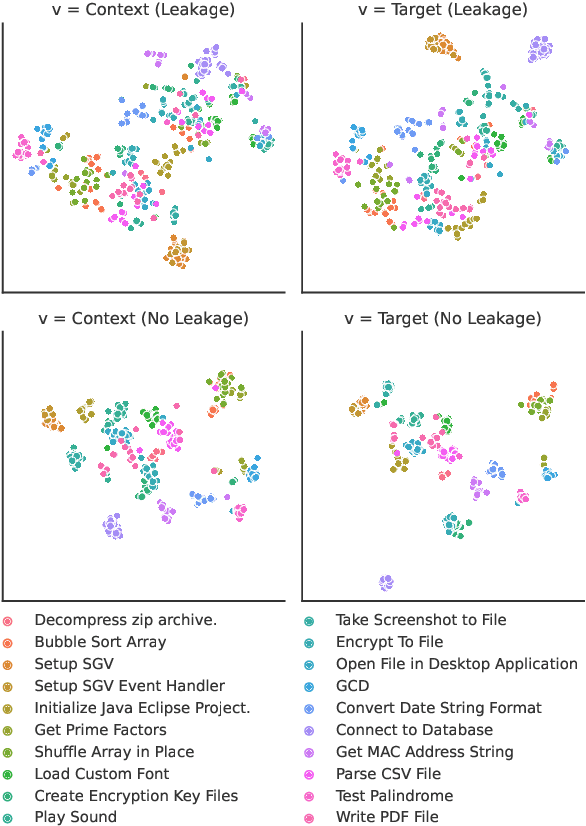
We address contextualized code retrieval, the search for code snippets helpful to fill gaps in a partial input program. Our approach facilitates a large-scale self-supervised contrastive training by splitting source code randomly into contexts and targets. To combat leakage between the two, we suggest a novel approach based on mutual identifier masking, dedentation, and the selection of syntax-aligned targets. Our second contribution is a new dataset for direct evaluation of contextualized code retrieval, based on a dataset of manually aligned subpassages of code clones. Our experiments demonstrate that our approach improves retrieval substantially, and yields new state-of-the-art results for code clone and defect detection.
An End-to-end Model for Entity-level Relation Extraction using Multi-instance Learning
Feb 11, 2021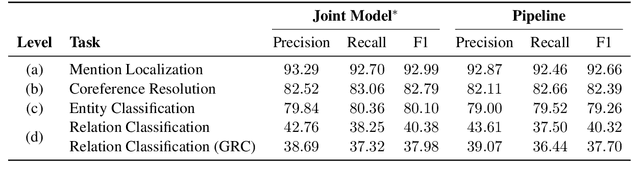
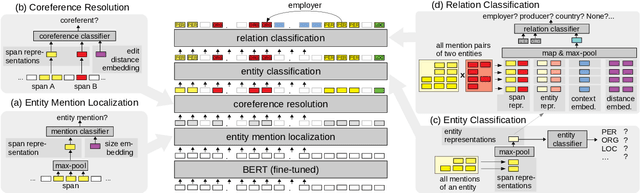
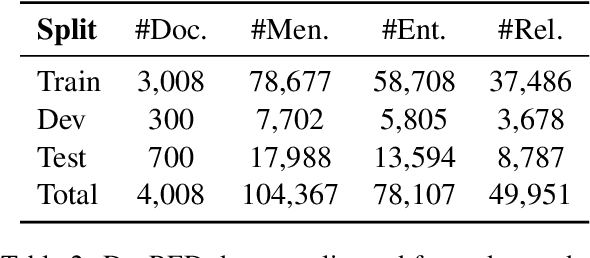
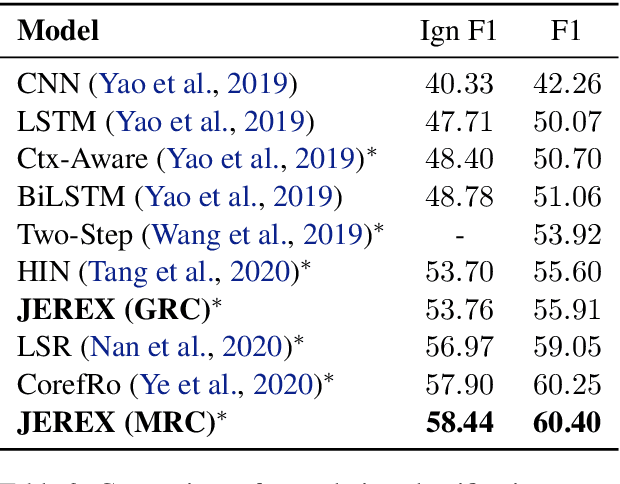
We present a joint model for entity-level relation extraction from documents. In contrast to other approaches - which focus on local intra-sentence mention pairs and thus require annotations on mention level - our model operates on entity level. To do so, a multi-task approach is followed that builds upon coreference resolution and gathers relevant signals via multi-instance learning with multi-level representations combining global entity and local mention information. We achieve state-of-the-art relation extraction results on the DocRED dataset and report the first entity-level end-to-end relation extraction results for future reference. Finally, our experimental results suggest that a joint approach is on par with task-specific learning, though more efficient due to shared parameters and training steps.
Neural Entity Linking on Technical Service Tickets
May 19, 2020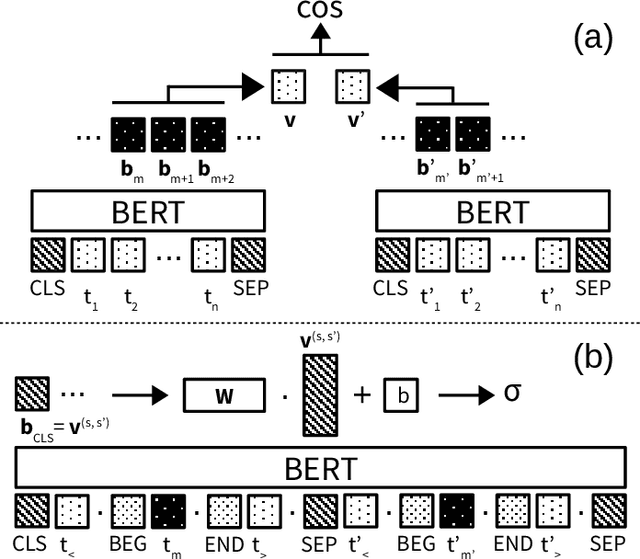
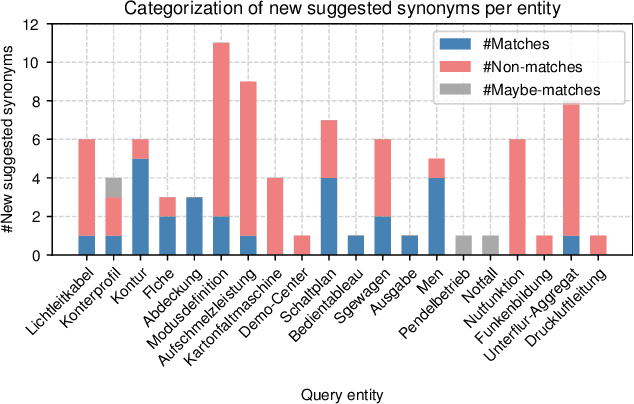
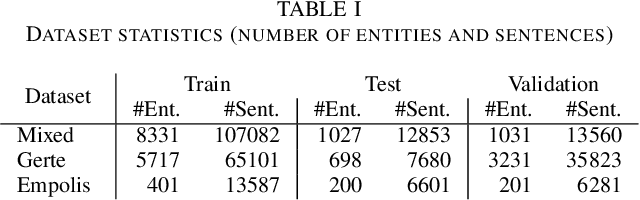
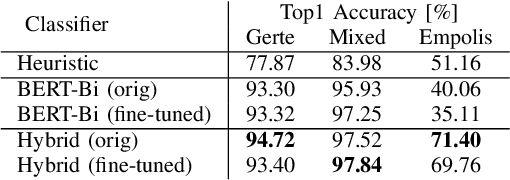
Entity linking, the task of mapping textual mentions to known entities, has recently been tackled using contextualized neural networks. We address the question whether these results -- reported for large, high-quality datasets such as Wikipedia -- transfer to practical business use cases, where labels are scarce, text is low-quality, and terminology is highly domain-specific. Using an entity linking model based on BERT, a popular transformer network in natural language processing, we show that a neural approach outperforms and complements hand-coded heuristics, with improvements of about 20% top-1 accuracy. Also, the benefits of transfer learning on a large corpus are demonstrated, while fine-tuning proves difficult. Finally, we compare different BERT-based architectures and show that a simple sentence-wise encoding (Bi-Encoder) offers a fast yet efficient search in practice.