 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Entity Linking on Technical Service Tickets
May 19, 2020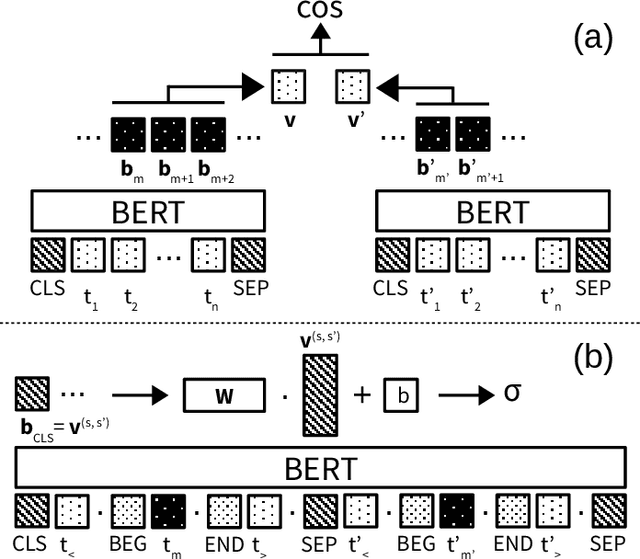
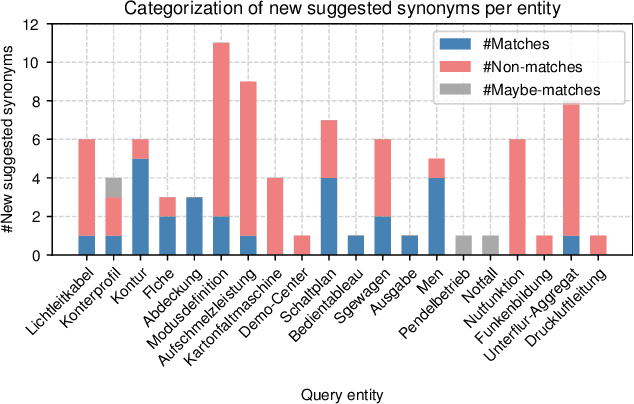
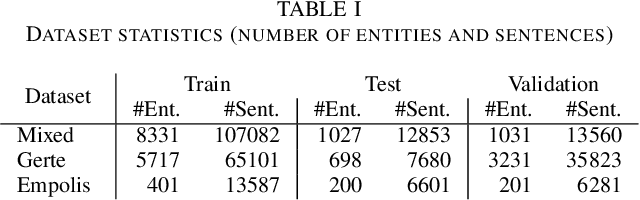
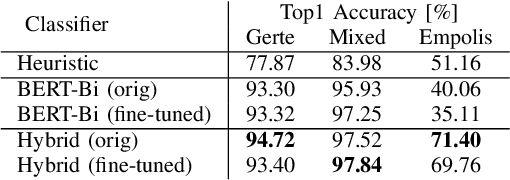
Entity linking, the task of mapping textual mentions to known entities, has recently been tackled using contextualized neural networks. We address the question whether these results -- reported for large, high-quality datasets such as Wikipedia -- transfer to practical business use cases, where labels are scarce, text is low-quality, and terminology is highly domain-specific. Using an entity linking model based on BERT, a popular transformer network in natural language processing, we show that a neural approach outperforms and complements hand-coded heuristics, with improvements of about 20% top-1 accuracy. Also, the benefits of transfer learning on a large corpus are demonstrated, while fine-tuning proves difficult. Finally, we compare different BERT-based architectures and show that a simple sentence-wise encoding (Bi-Encoder) offers a fast yet efficient search in practice.
Hamming Sentence Embeddings for Information Retrieval
Aug 15, 2019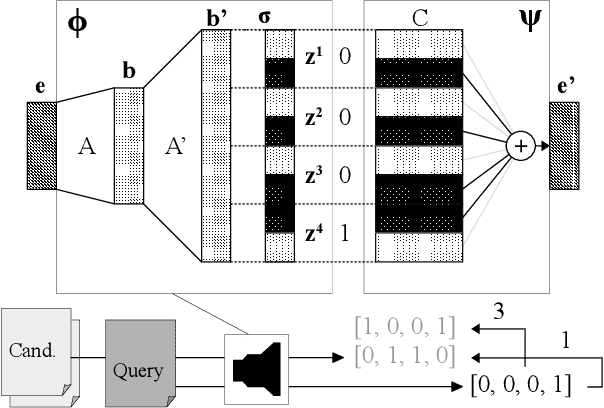
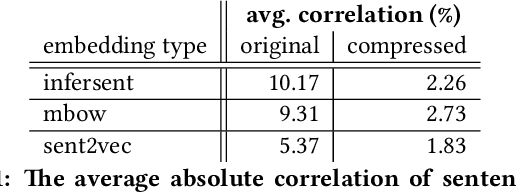
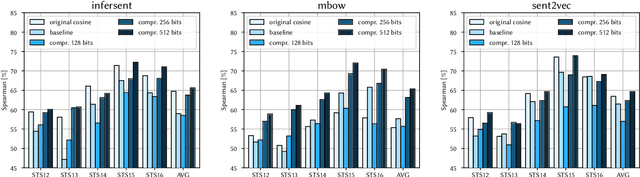
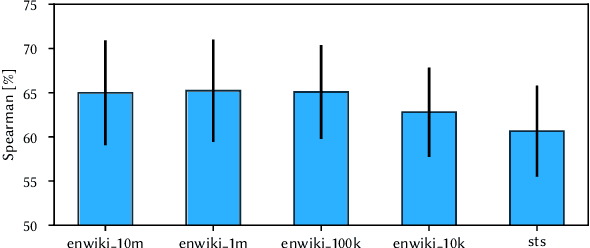
In retrieval applications, binary hashes are known to offer significant improvements in terms of both memory and speed. We investigate the compression of sentence embeddings using a neural encoder-decoder architecture, which is trained by minimizing reconstruction error. Instead of employing the original real-valued embeddings, we use latent representations in Hamming space produced by the encoder for similarity calculations. In quantitative experiments on several benchmarks for semantic similarity tasks, we show that our compressed hamming embeddings yield a comparable performance to uncompressed embeddings (Sent2Vec, InferSent, Glove-BoW), at compression ratios of up to 256:1. We further demonstrate that our model strongly decorrelates input features, and that the compressor generalizes well when pre-trained on Wikipedia sentences. We publish the source code on Github and all experimental results.