 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeq-exponential family for policy optimization
Aug 14, 2024Policy optimization methods benefit from a simple and tractable policy functional, usually the Gaussian for continuous action spaces. In this paper, we consider a broader policy family that remains tractable: the $q$-exponential family. This family of policies is flexible, allowing the specification of both heavy-tailed policies ($q>1$) and light-tailed policies ($q<1$). This paper examines the interplay between $q$-exponential policies for several actor-critic algorithms conducted on both online and offline problems. We find that heavy-tailed policies are more effective in general and can consistently improve on Gaussian. In particular, we find the Student's t-distribution to be more stable than the Gaussian across settings and that a heavy-tailed $q$-Gaussian for Tsallis Advantage Weighted Actor-Critic consistently performs well in offline benchmark problems. Our code is available at \url{https://github.com/lingweizhu/qexp}.
GVFs in the Real World: Making Predictions Online for Water Treatment
Dec 04, 2023In this paper we investigate the use of reinforcement-learning based prediction approaches for a real drinking-water treatment plant. Developing such a prediction system is a critical step on the path to optimizing and automating water treatment. Before that, there are many questions to answer about the predictability of the data, suitable neural network architectures, how to overcome partial observability and more. We first describe this dataset, and highlight challenges with seasonality, nonstationarity, partial observability, and heterogeneity across sensors and operation modes of the plant. We then describe General Value Function (GVF) predictions -- discounted cumulative sums of observations -- and highlight why they might be preferable to classical n-step predictions common in time series prediction. We discuss how to use offline data to appropriately pre-train our temporal difference learning (TD) agents that learn these GVF predictions, including how to select hyperparameters for online fine-tuning in deployment. We find that the TD-prediction agent obtains an overall lower normalized mean-squared error than the n-step prediction agent. Finally, we show the importance of learning in deployment, by comparing a TD agent trained purely offline with no online updating to a TD agent that learns online. This final result is one of the first to motivate the importance of adapting predictions in real-time, for non-stationary high-volume systems in the real world.
* Published in Machine Learning (2023)
An Open-World Extension to Knowledge Graph Completion Models
Jun 19, 2019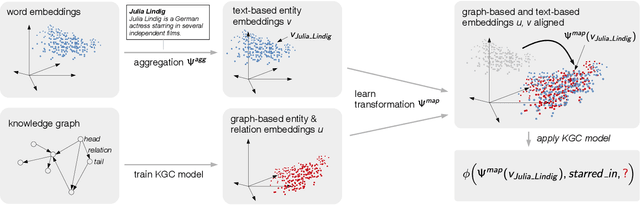
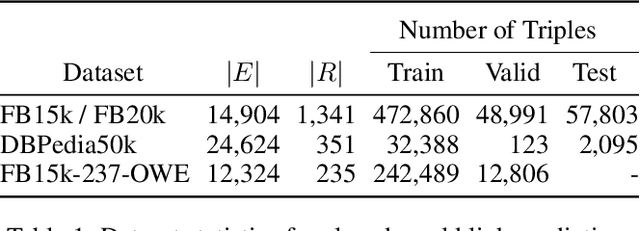
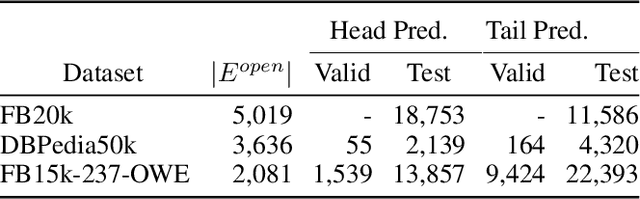
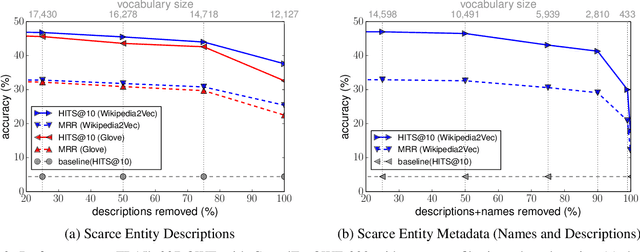
We present a novel extension to embedding-based knowledge graph completion models which enables them to perform open-world link prediction, i.e. to predict facts for entities unseen in training based on their textual description. Our model combines a regular link prediction model learned from a knowledge graph with word embeddings learned from a textual corpus. After training both independently, we learn a transformation to map the embeddings of an entity's name and description to the graph-based embedding space. In experiments on several datasets including FB20k, DBPedia50k and our new dataset FB15k-237-OWE, we demonstrate competitive results. Particularly, our approach exploits the full knowledge graph structure even when textual descriptions are scarce, does not require a joint training on graph and text, and can be applied to any embedding-based link prediction model, such as TransE, ComplEx and DistMult.
Distillation Techniques for Pseudo-rehearsal Based Incremental Learning
Jul 11, 2018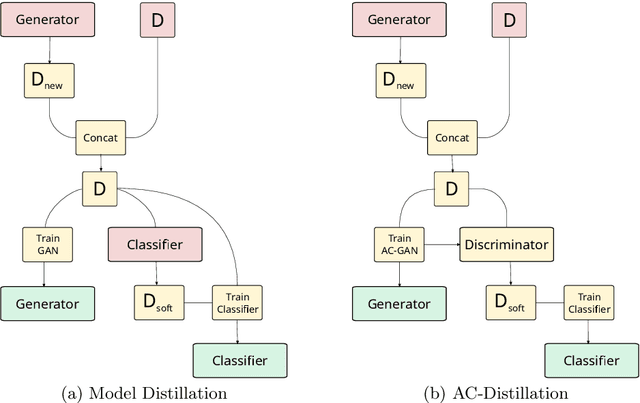
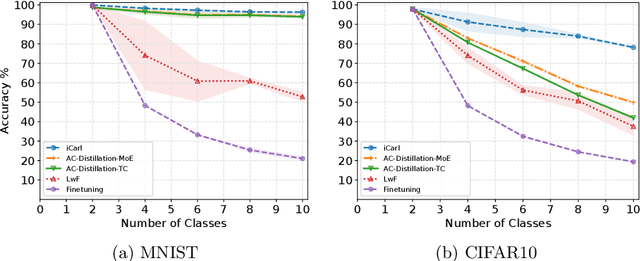
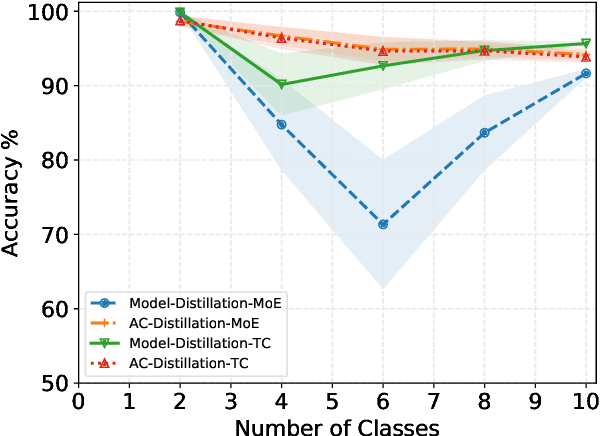
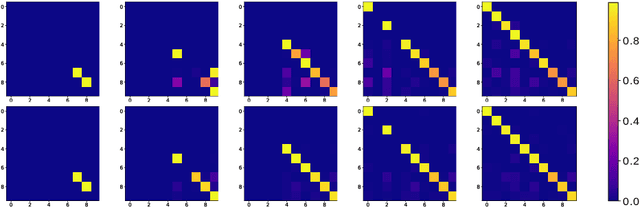
The ability to learn from incrementally arriving data is essential for any life-long learning system. However, standard deep neural networks forget the knowledge about the old tasks, a phenomenon called catastrophic forgetting, when trained on incrementally arriving data. We discuss the biases in current Generative Adversarial Networks (GAN) based approaches that learn the classifier by knowledge distillation from previously trained classifiers. These biases cause the trained classifier to perform poorly. We propose an approach to remove these biases by distilling knowledge from the classifier of AC-GAN. Experiments on MNIST and CIFAR10 show that this method is comparable to current state of the art rehearsal based approaches. The code for this paper is available at https://bit.ly/incremental-learning