 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Truncated Causal History Model for Video Restoration
Oct 15, 2024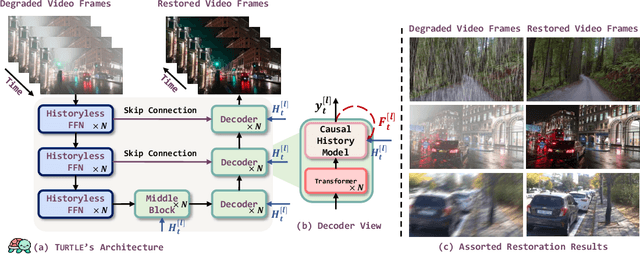
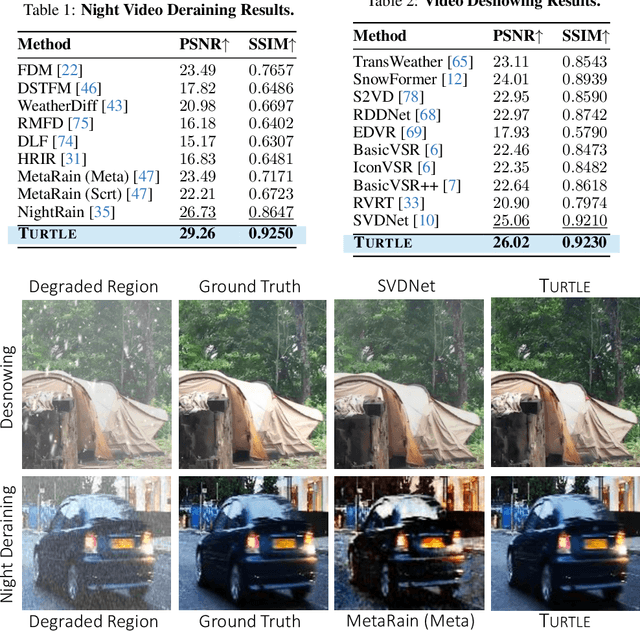
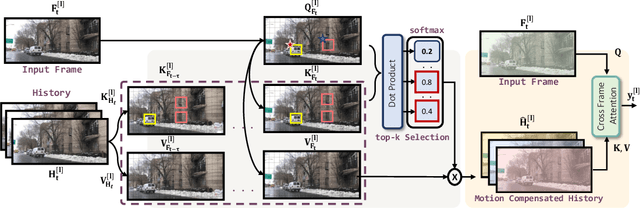

One key challenge to video restoration is to model the transition dynamics of video frames governed by motion. In this work, we propose TURTLE to learn the truncated causal history model for efficient and high-performing video restoration. Unlike traditional methods that process a range of contextual frames in parallel, TURTLE enhances efficiency by storing and summarizing a truncated history of the input frame latent representation into an evolving historical state. This is achieved through a sophisticated similarity-based retrieval mechanism that implicitly accounts for inter-frame motion and alignment. The causal design in TURTLE enables recurrence in inference through state-memorized historical features while allowing parallel training by sampling truncated video clips. We report new state-of-the-art results on a multitude of video restoration benchmark tasks, including video desnowing, nighttime video deraining, video raindrops and rain streak removal, video super-resolution, real-world and synthetic video deblurring, and blind video denoising while reducing the computational cost compared to existing best contextual methods on all these tasks.
CascadedGaze: Efficiency in Global Context Extraction for Image Restoration
Jan 26, 2024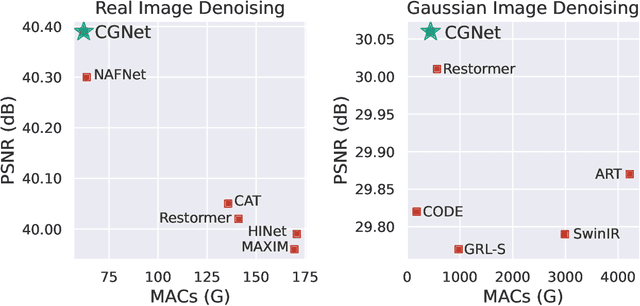
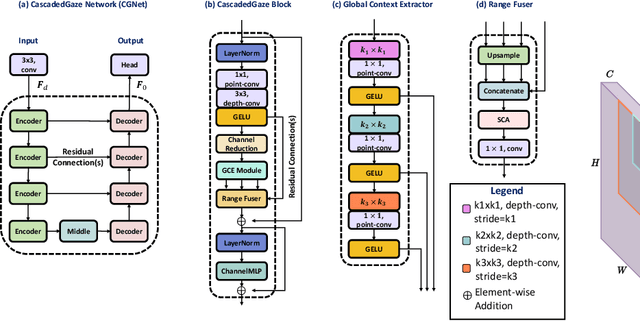
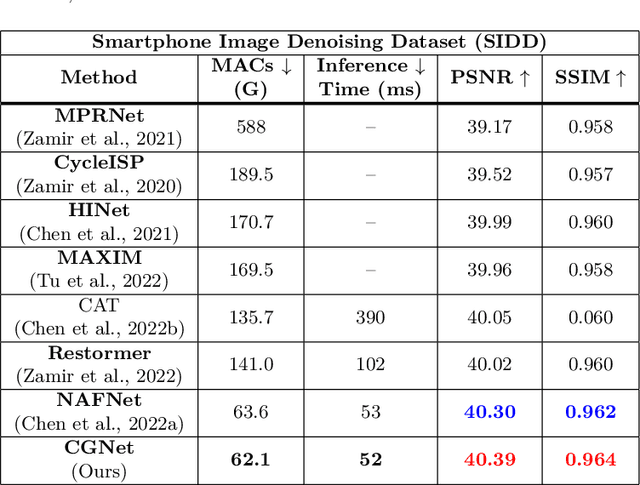
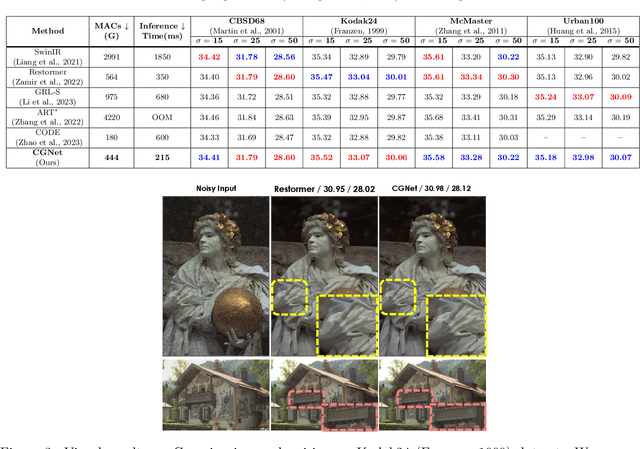
Image restoration tasks traditionally rely on convolutional neural networks. However, given the local nature of the convolutional operator, they struggle to capture global information. The promise of attention mechanisms in Transformers is to circumvent this problem, but it comes at the cost of intensive computational overhead. Many recent studies in image restoration have focused on solving the challenge of balancing performance and computational cost via Transformer variants. In this paper, we present CascadedGaze Network (CGNet), an encoder-decoder architecture that employs Global Context Extractor (GCE), a novel and efficient way to capture global information for image restoration. The GCE module leverages small kernels across convolutional layers to learn global dependencies, without requiring self-attention. Extensive experimental results show that our approach outperforms a range of state-of-the-art methods on denoising benchmark datasets including both real image denoising and synthetic image denoising, as well as on image deblurring task, while being more computationally efficient.
GVFs in the Real World: Making Predictions Online for Water Treatment
Dec 04, 2023In this paper we investigate the use of reinforcement-learning based prediction approaches for a real drinking-water treatment plant. Developing such a prediction system is a critical step on the path to optimizing and automating water treatment. Before that, there are many questions to answer about the predictability of the data, suitable neural network architectures, how to overcome partial observability and more. We first describe this dataset, and highlight challenges with seasonality, nonstationarity, partial observability, and heterogeneity across sensors and operation modes of the plant. We then describe General Value Function (GVF) predictions -- discounted cumulative sums of observations -- and highlight why they might be preferable to classical n-step predictions common in time series prediction. We discuss how to use offline data to appropriately pre-train our temporal difference learning (TD) agents that learn these GVF predictions, including how to select hyperparameters for online fine-tuning in deployment. We find that the TD-prediction agent obtains an overall lower normalized mean-squared error than the n-step prediction agent. Finally, we show the importance of learning in deployment, by comparing a TD agent trained purely offline with no online updating to a TD agent that learns online. This final result is one of the first to motivate the importance of adapting predictions in real-time, for non-stationary high-volume systems in the real world.
* Published in Machine Learning (2023)
Movement-induced Priors for Deep Stereo
Oct 18, 2020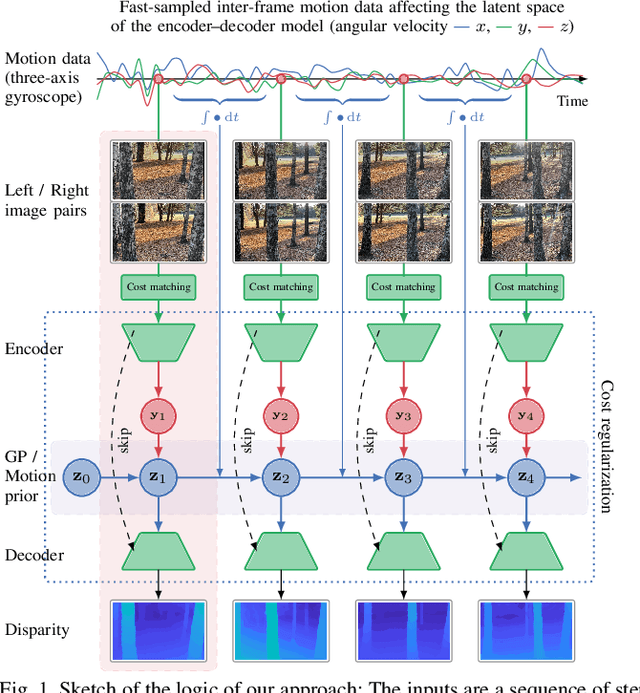
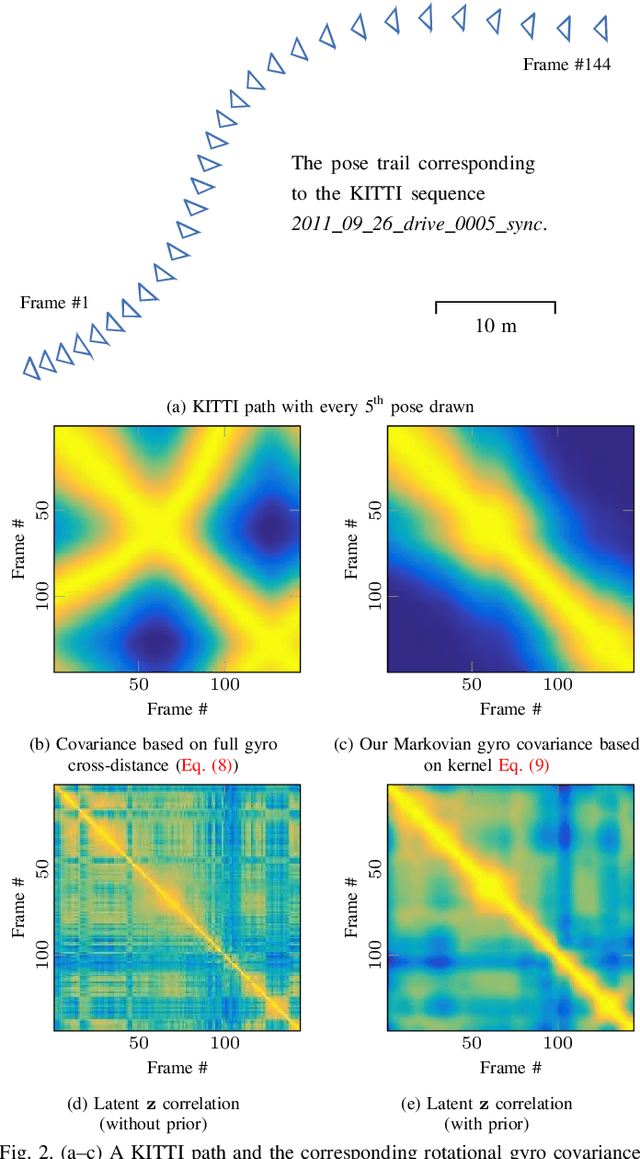
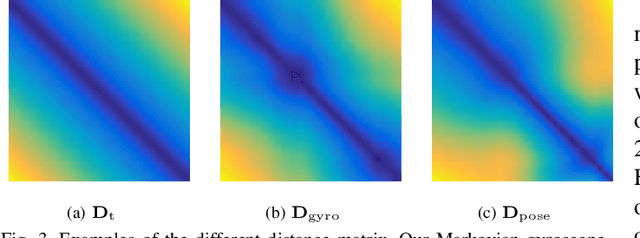

We propose a method for fusing stereo disparity estimation with movement-induced prior information. Instead of independent inference frame-by-frame, we formulate the problem as a non-parametric learning task in terms of a temporal Gaussian process prior with a movement-driven kernel for inter-frame reasoning. We present a hierarchy of three Gaussian process kernels depending on the availability of motion information, where our main focus is on a new gyroscope-driven kernel for handheld devices with low-quality MEMS sensors, thus also relaxing the requirement of having full 6D camera poses available. We show how our method can be combined with two state-of-the-art deep stereo methods. The method either work in a plug-and-play fashion with pre-trained deep stereo networks, or further improved by jointly training the kernels together with encoder-decoder architectures, leading to consistent improvement.
Deep Latent Space Learning for Cross-modal Mapping of Audio and Visual Signals
Sep 18, 2019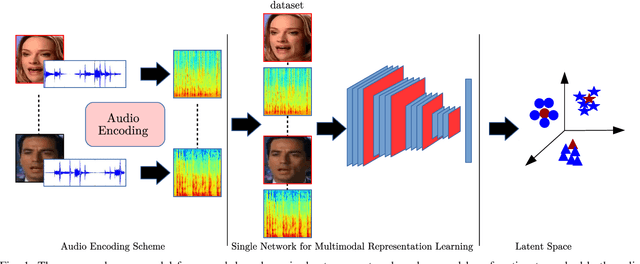


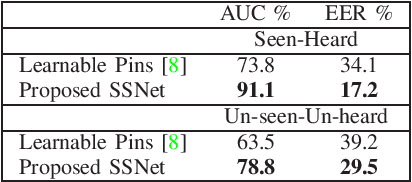
We propose a novel deep training algorithm for joint representation of audio and visual information which consists of a single stream network (SSNet) coupled with a novel loss function to learn a shared deep latent space representation of multimodal information. The proposed framework characterizes the shared latent space by leveraging the class centers which helps to eliminate the need for pairwise or triplet supervision. We quantitatively and qualitatively evaluate the proposed approach on VoxCeleb, a benchmarks audio-visual dataset on a multitude of tasks including cross-modal verification, cross-modal matching, and cross-modal retrieval. State-of-the-art performance is achieved on cross-modal verification and matching while comparable results are observed on the remaining applications. Our experiments demonstrate the effectiveness of the technique for cross-modal biometric applications.
Do Cross Modal Systems Leverage Semantic Relationships?
Sep 03, 2019
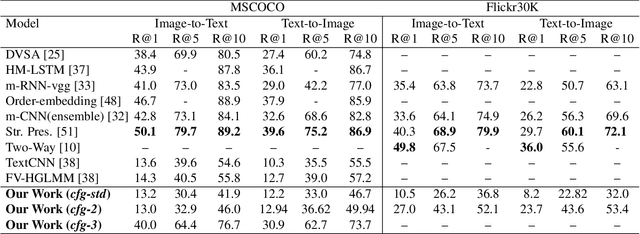


Current cross-modal retrieval systems are evaluated using R@K measure which does not leverage semantic relationships rather strictly follows the manually marked image text query pairs. Therefore, current systems do not generalize well for the unseen data in the wild. To handle this, we propose a new measure, SemanticMap, to evaluate the performance of cross-modal systems. Our proposed measure evaluates the semantic similarity between the image and text representations in the latent embedding space. We also propose a novel cross-modal retrieval system using a single stream network for bidirectional retrieval. The proposed system is based on a deep neural network trained using extended center loss, minimizing the distance of image and text descriptions in the latent space from the class centers. In our system, the text descriptions are also encoded as images which enabled us to use a single stream network for both text and images. To the best of our knowledge, our work is the first of its kind in terms of employing a single stream network for cross-modal retrieval systems. The proposed system is evaluated on two publicly available datasets including MSCOCO and Flickr30K and has shown comparable results to the current state-of-the-art methods.
Learning Inward Scaled Hypersphere Embedding: Exploring Projections in Higher Dimensions
Oct 16, 2018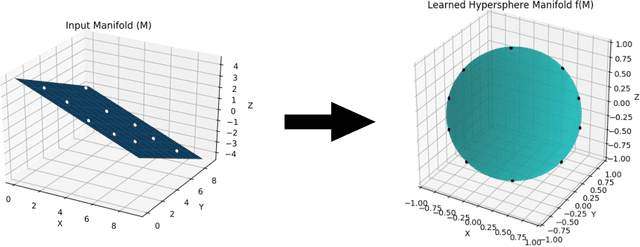
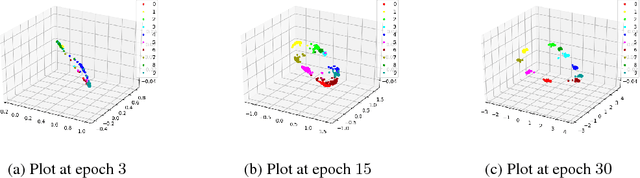
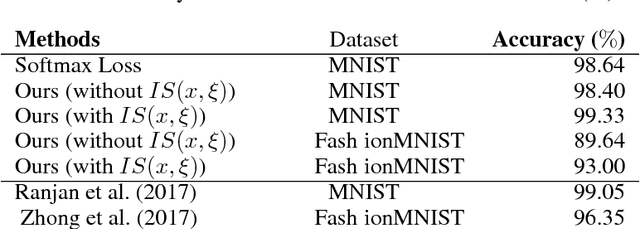

Majority of the current dimensionality reduction or retrieval techniques rely on embedding the learned feature representations onto a computable metric space. Once the learned features are mapped, a distance metric aids the bridging of gaps between similar instances. Since the scaled projection is not exploited in these methods, discriminative embedding onto a hyperspace becomes a challenge. In this paper, we propose to inwardly scale feature representations in proportional to projecting them onto a hypersphere manifold for discriminative analysis. We further propose a novel, yet simpler, convolutional neural network based architecture and extensively evaluate the proposed methodology in the context of classification and retrieval tasks obtaining results comparable to state-of-the-art techniques.
Image and Encoded Text Fusion for Multi-Modal Classification
Oct 03, 2018
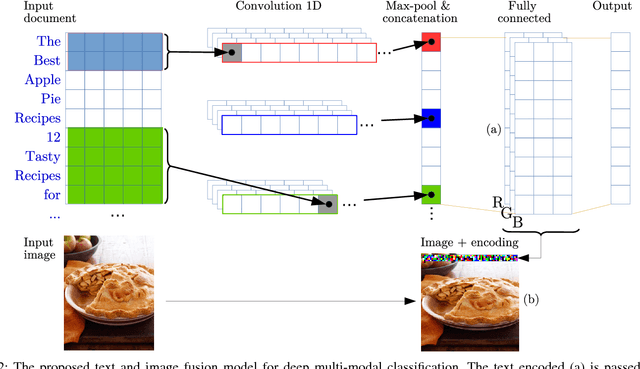

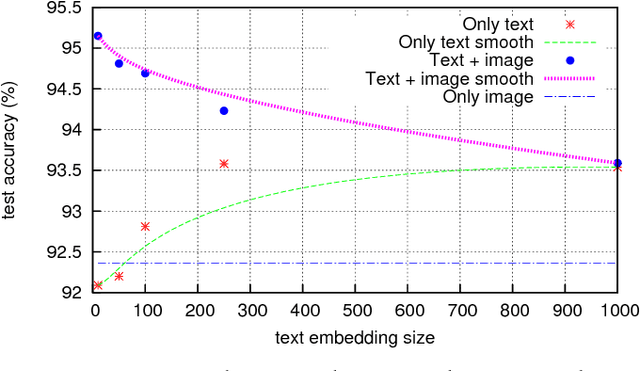
Multi-modal approaches employ data from multiple input streams such as textual and visual domains. Deep neural networks have been successfully employed for these approaches. In this paper, we present a novel multi-modal approach that fuses images and text descriptions to improve multi-modal classification performance in real-world scenarios. The proposed approach embeds an encoded text onto an image to obtain an information-enriched image. To learn feature representations of resulting images, standard Convolutional Neural Networks (CNNs) are employed for the classification task. We demonstrate how a CNN based pipeline can be used to learn representations of the novel fusion approach. We compare our approach with individual sources on two large-scale multi-modal classification datasets while obtaining encouraging results. Furthermore, we evaluate our approach against two famous multi-modal strategies namely early fusion and late fusion.
Seeing Colors: Learning Semantic Text Encoding for Classification
Aug 31, 2018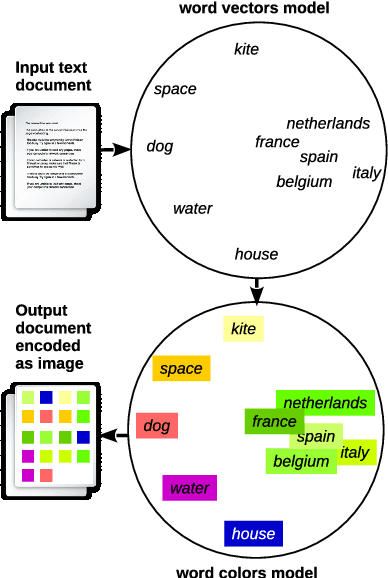
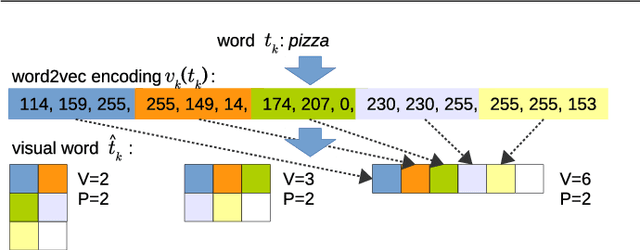
The question we answer with this work is: can we convert a text document into an image to exploit best image classification models to classify documents? To answer this question we present a novel text classification method which converts a text document into an encoded image, using word embedding and capabilities of Convolutional Neural Networks (CNNs), successfully employed in image classification. We evaluate our approach by obtaining promising results on some well-known benchmark datasets for text classification. This work allows the application of many of the advanced CNN architectures developed for Computer Vision to Natural Language Processing. We test the proposed approach on a multi-modal dataset, proving that it is possible to use a single deep model to represent text and image in the same feature space.
Git Loss for Deep Face Recognition
Jul 28, 2018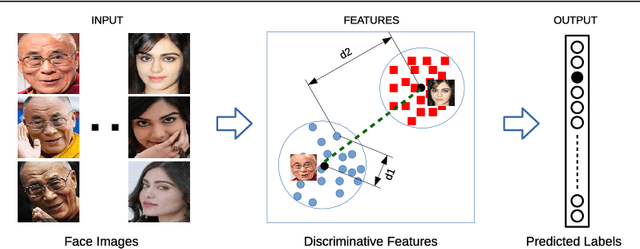
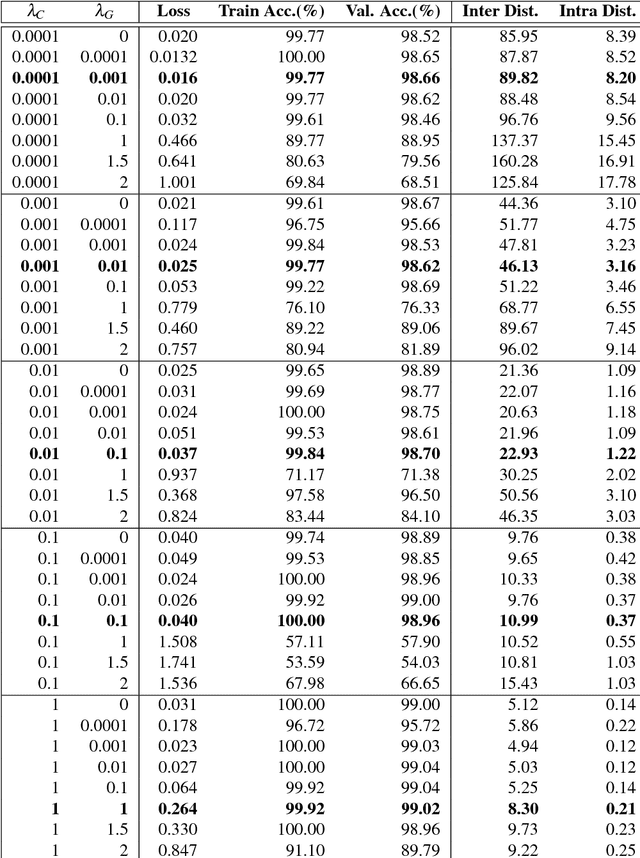
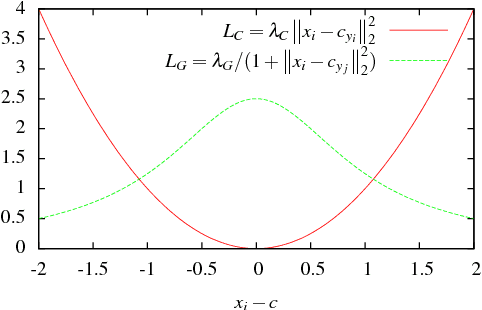
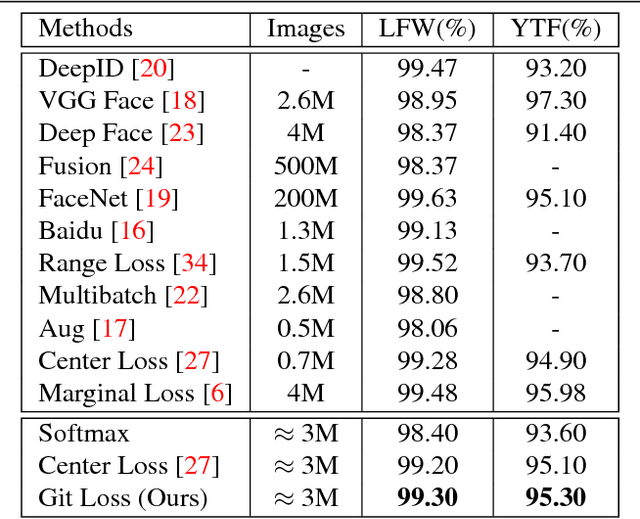
Convolutional Neural Networks (CNNs) have been widely used in computer vision tasks, such as face recognition and verification, and have achieved state-of-the-art results due to their ability to capture discriminative deep features. Conventionally, CNNs have been trained with softmax as supervision signal to penalize the classification loss. In order to further enhance the discriminative capability of deep features, we introduce a joint supervision signal, Git loss, which leverages on softmax and center loss functions. The aim of our loss function is to minimize the intra-class variations as well as maximize the inter-class distances. Such minimization and maximization of deep features are considered ideal for face recognition task. We perform experiments on two popular face recognition benchmarks datasets and show that our proposed loss function achieves maximum separability between deep face features of different identities and achieves state-of-the-art accuracy on two major face recognition benchmark datasets: Labeled Faces in the Wild (LFW) and YouTube Faces (YTF). However, it should be noted that the major objective of Git loss is to achieve maximum separability between deep features of divergent identities.