 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Cross Modal Systems Leverage Semantic Relationships?
Paper and Code
Sep 03, 2019
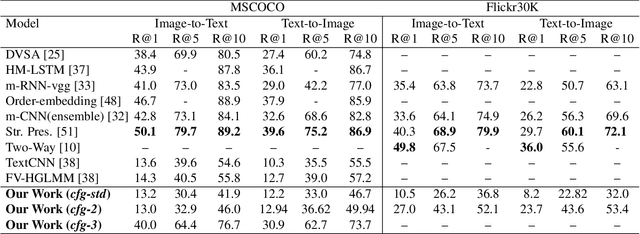


Current cross-modal retrieval systems are evaluated using R@K measure which does not leverage semantic relationships rather strictly follows the manually marked image text query pairs. Therefore, current systems do not generalize well for the unseen data in the wild. To handle this, we propose a new measure, SemanticMap, to evaluate the performance of cross-modal systems. Our proposed measure evaluates the semantic similarity between the image and text representations in the latent embedding space. We also propose a novel cross-modal retrieval system using a single stream network for bidirectional retrieval. The proposed system is based on a deep neural network trained using extended center loss, minimizing the distance of image and text descriptions in the latent space from the class centers. In our system, the text descriptions are also encoded as images which enabled us to use a single stream network for both text and images. To the best of our knowledge, our work is the first of its kind in terms of employing a single stream network for cross-modal retrieval systems. The proposed system is evaluated on two publicly available datasets including MSCOCO and Flickr30K and has shown comparable results to the current state-of-the-art methods.