 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Latent Space Learning for Cross-modal Mapping of Audio and Visual Signals
Sep 18, 2019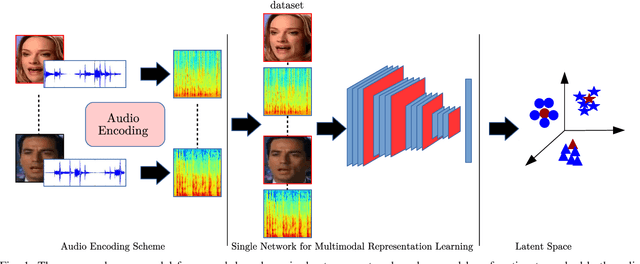


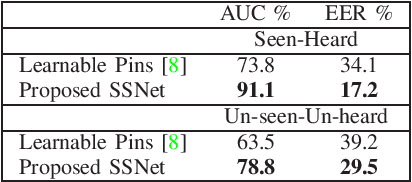
We propose a novel deep training algorithm for joint representation of audio and visual information which consists of a single stream network (SSNet) coupled with a novel loss function to learn a shared deep latent space representation of multimodal information. The proposed framework characterizes the shared latent space by leveraging the class centers which helps to eliminate the need for pairwise or triplet supervision. We quantitatively and qualitatively evaluate the proposed approach on VoxCeleb, a benchmarks audio-visual dataset on a multitude of tasks including cross-modal verification, cross-modal matching, and cross-modal retrieval. State-of-the-art performance is achieved on cross-modal verification and matching while comparable results are observed on the remaining applications. Our experiments demonstrate the effectiveness of the technique for cross-modal biometric applications.
A Classification Methodology based on Subspace Graphs Learning
Sep 09, 2019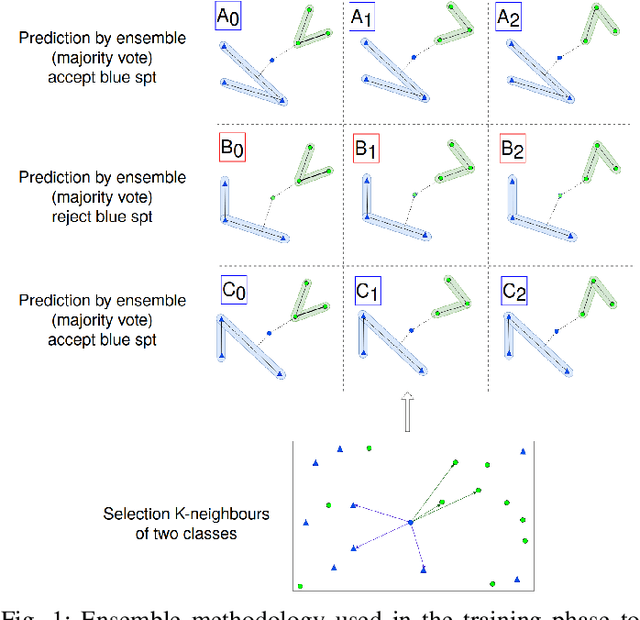
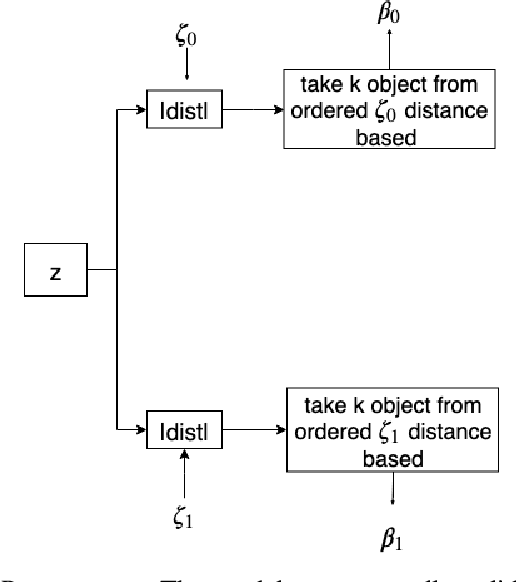

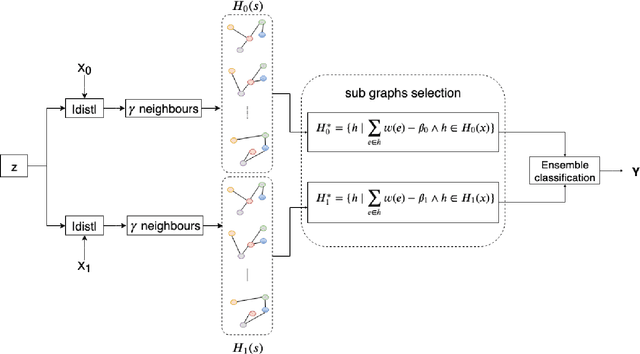
In this paper, we propose a design methodology for one-class classifiers using an ensemble-of-classifiers approach. The objective is to select the best structures created during the training phase using an ensemble of spanning trees. It takes the best classifier, partitioning the area near a pattern into $\gamma^{\gamma-2}$ sub-spaces and combining all possible spanning trees that can be created starting from $\gamma$ nodes. The proposed method leverages on a supervised classification methodology and the concept of minimum distance. We evaluate our approach on well-known benchmark datasets and results obtained demonstrate that it achieves comparable and, in many cases, state-of-the-art results. Moreover, it obtains good performance even with unbalanced datasets.
Picture What you Read
Sep 09, 2019
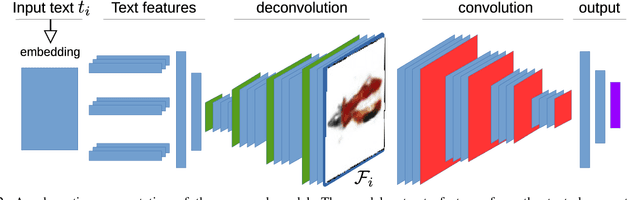

Visualization refers to our ability to create an image in our head based on the text we read or the words we hear. It is one of the many skills that makes reading comprehension possible. Convolutional Neural Networks (CNN) are an excellent tool for recognizing and classifying text documents. In addition, it can generate images conditioned on natural language. In this work, we utilize CNNs capabilities to generate realistic images representative of the text illustrating the semantic concept. We conducted various experiments to highlight the capacity of the proposed model to generate representative images of the text descriptions used as input to the proposed model.
Do Cross Modal Systems Leverage Semantic Relationships?
Sep 03, 2019
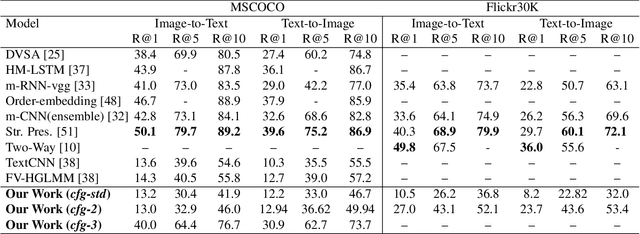


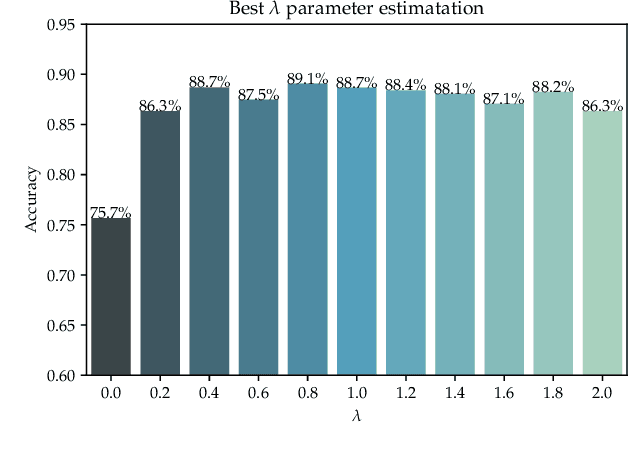
Current cross-modal retrieval systems are evaluated using R@K measure which does not leverage semantic relationships rather strictly follows the manually marked image text query pairs. Therefore, current systems do not generalize well for the unseen data in the wild. To handle this, we propose a new measure, SemanticMap, to evaluate the performance of cross-modal systems. Our proposed measure evaluates the semantic similarity between the image and text representations in the latent embedding space. We also propose a novel cross-modal retrieval system using a single stream network for bidirectional retrieval. The proposed system is based on a deep neural network trained using extended center loss, minimizing the distance of image and text descriptions in the latent space from the class centers. In our system, the text descriptions are also encoded as images which enabled us to use a single stream network for both text and images. To the best of our knowledge, our work is the first of its kind in terms of employing a single stream network for cross-modal retrieval systems. The proposed system is evaluated on two publicly available datasets including MSCOCO and Flickr30K and has shown comparable results to the current state-of-the-art methods.
Binary Classification using Pairs of Minimum Spanning Trees or N-ary Trees
Jun 25, 2019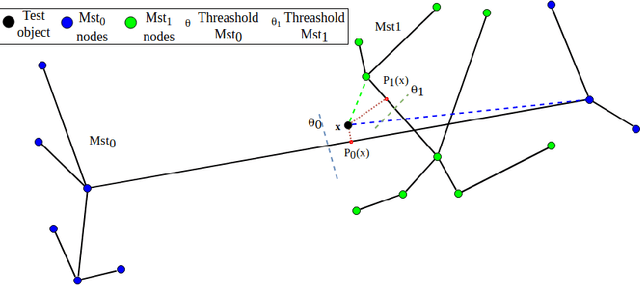


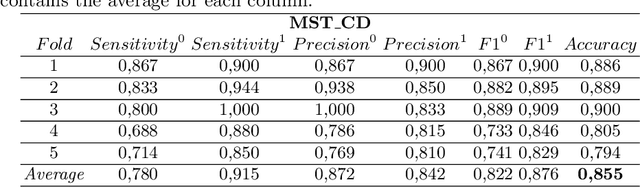
One-class classifiers are trained with target class only samples. Intuitively, their conservative modelling of the class description may benefit classical classification tasks where classes are difficult to separate due to overlapping and data imbalance. In this work, three methods are proposed which leverage on the combination of one-class classifiers based on non-parametric models, N-ary Trees and Minimum Spanning Trees class descriptors (MST-CD), to tackle binary classification problems. The methods deal with the inconsistencies arising from combining multiple classifiers and with spurious connections that MST-CD creates in multi-modal class distributions. As shown by our tests on several datasets, the proposed approach is feasible and comparable with state-of-the-art algorithms.
Aiding Intra-Text Representations with Visual Context for Multimodal Named Entity Recognition
Apr 02, 2019
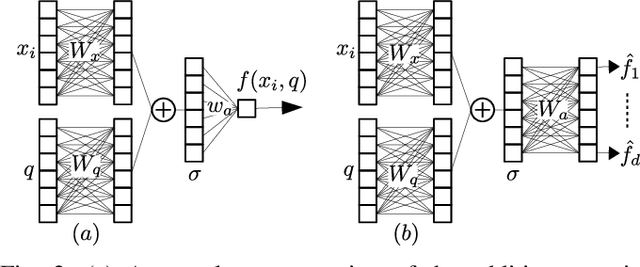
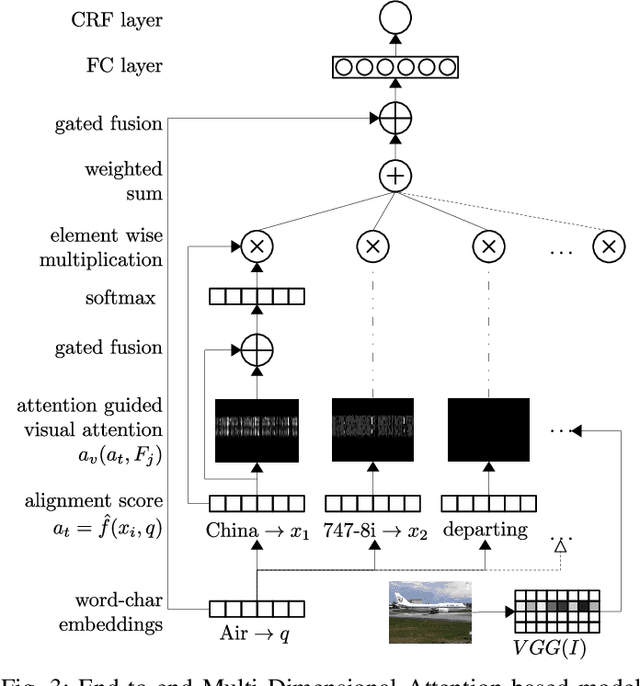
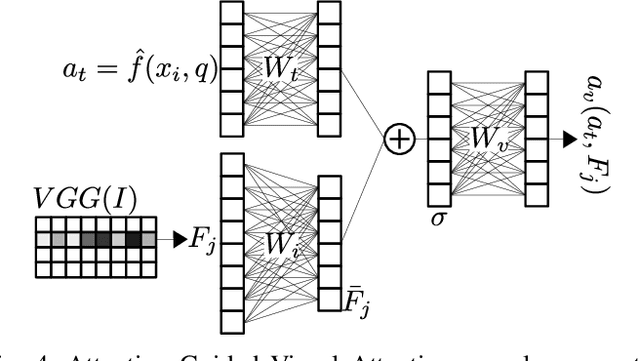
With massive explosion of social media such as Twitter and Instagram, people daily share billions of multimedia posts, containing images and text. Typically, text in these posts is short, informal and noisy, leading to ambiguities which can be resolved using images. In this paper we explore text-centric Named Entity Recognition task on these multimedia posts. We propose an end to end model which learns a joint representation of a text and an image. Our model extends multi-dimensional self attention technique, where now image helps to enhance relationship between words. Experiments show that our model is capable of capturing both textual and visual contexts with greater accuracy, achieving state-of-the-art results on Twitter multimodal Named Entity Recognition dataset.
Learning Inward Scaled Hypersphere Embedding: Exploring Projections in Higher Dimensions
Oct 16, 2018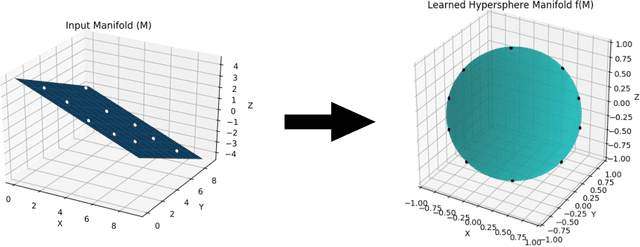
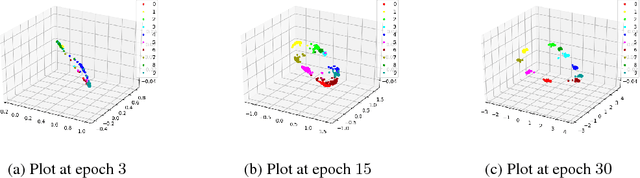
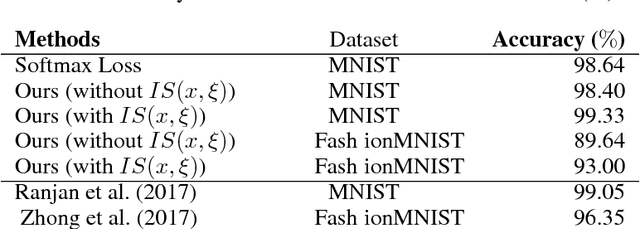

Majority of the current dimensionality reduction or retrieval techniques rely on embedding the learned feature representations onto a computable metric space. Once the learned features are mapped, a distance metric aids the bridging of gaps between similar instances. Since the scaled projection is not exploited in these methods, discriminative embedding onto a hyperspace becomes a challenge. In this paper, we propose to inwardly scale feature representations in proportional to projecting them onto a hypersphere manifold for discriminative analysis. We further propose a novel, yet simpler, convolutional neural network based architecture and extensively evaluate the proposed methodology in the context of classification and retrieval tasks obtaining results comparable to state-of-the-art techniques.
Image and Encoded Text Fusion for Multi-Modal Classification
Oct 03, 2018
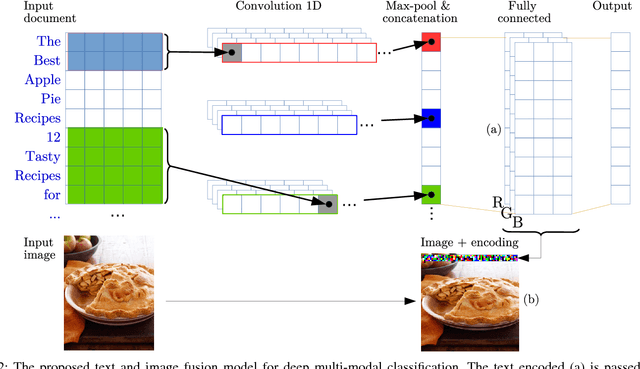

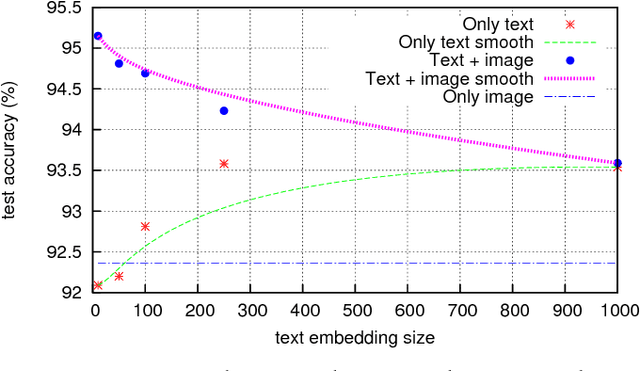
Multi-modal approaches employ data from multiple input streams such as textual and visual domains. Deep neural networks have been successfully employed for these approaches. In this paper, we present a novel multi-modal approach that fuses images and text descriptions to improve multi-modal classification performance in real-world scenarios. The proposed approach embeds an encoded text onto an image to obtain an information-enriched image. To learn feature representations of resulting images, standard Convolutional Neural Networks (CNNs) are employed for the classification task. We demonstrate how a CNN based pipeline can be used to learn representations of the novel fusion approach. We compare our approach with individual sources on two large-scale multi-modal classification datasets while obtaining encouraging results. Furthermore, we evaluate our approach against two famous multi-modal strategies namely early fusion and late fusion.
Seeing Colors: Learning Semantic Text Encoding for Classification
Aug 31, 2018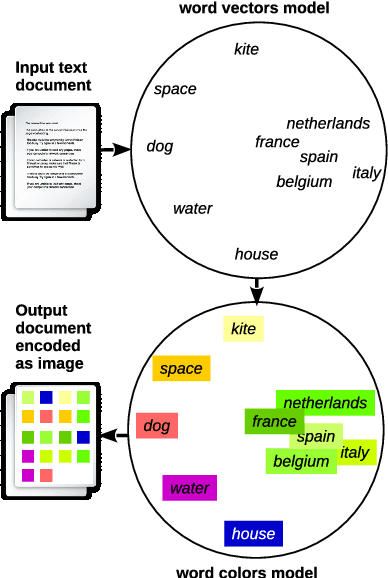
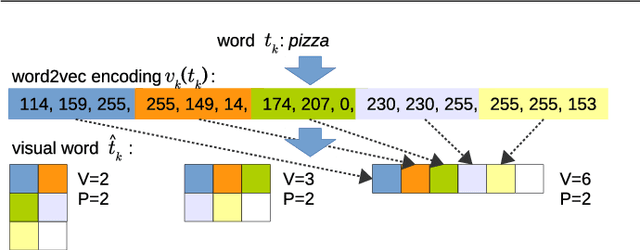
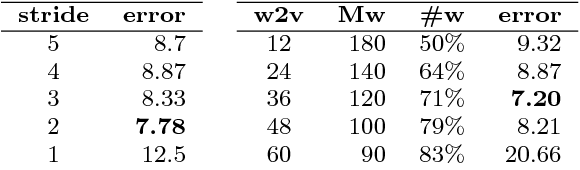
The question we answer with this work is: can we convert a text document into an image to exploit best image classification models to classify documents? To answer this question we present a novel text classification method which converts a text document into an encoded image, using word embedding and capabilities of Convolutional Neural Networks (CNNs), successfully employed in image classification. We evaluate our approach by obtaining promising results on some well-known benchmark datasets for text classification. This work allows the application of many of the advanced CNN architectures developed for Computer Vision to Natural Language Processing. We test the proposed approach on a multi-modal dataset, proving that it is possible to use a single deep model to represent text and image in the same feature space.
Git Loss for Deep Face Recognition
Jul 28, 2018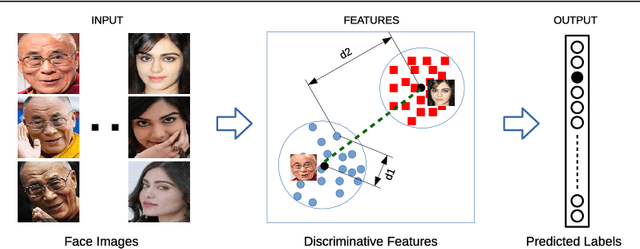
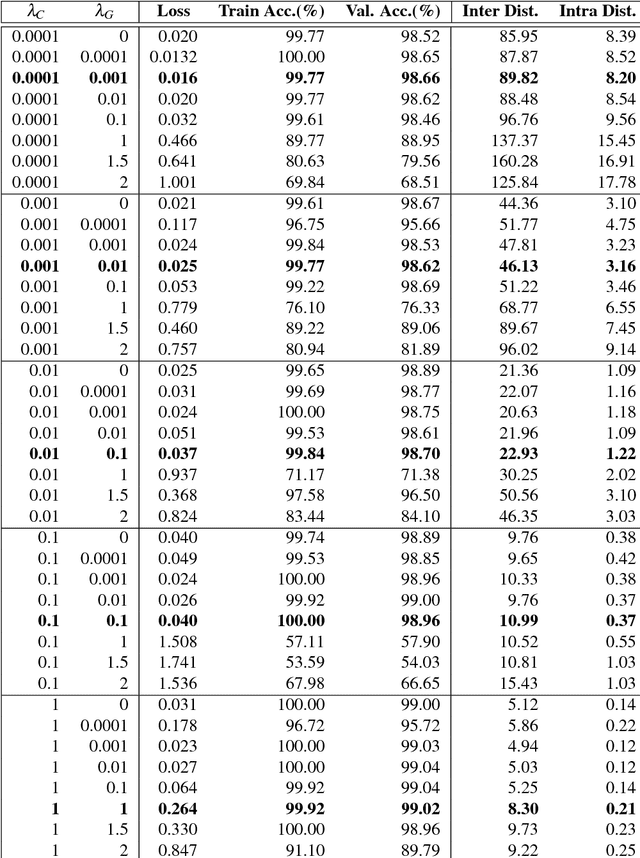
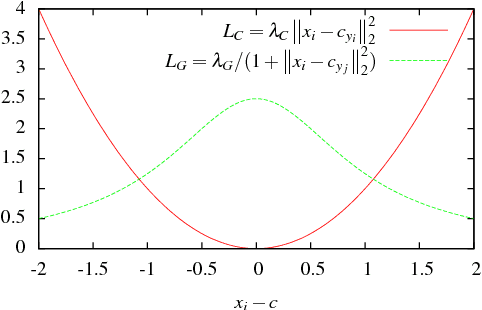
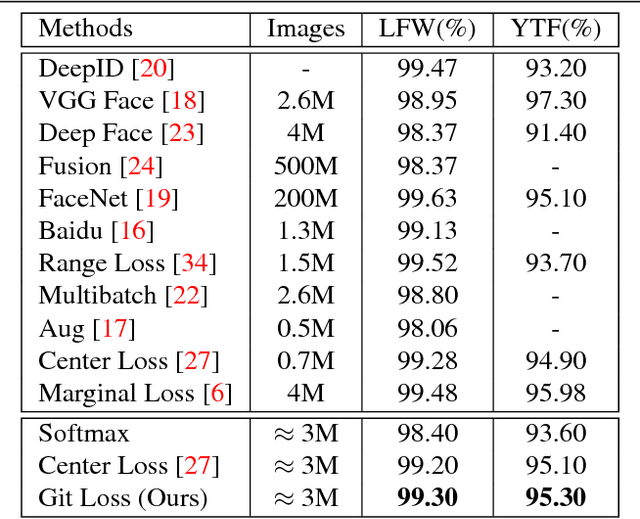
Convolutional Neural Networks (CNNs) have been widely used in computer vision tasks, such as face recognition and verification, and have achieved state-of-the-art results due to their ability to capture discriminative deep features. Conventionally, CNNs have been trained with softmax as supervision signal to penalize the classification loss. In order to further enhance the discriminative capability of deep features, we introduce a joint supervision signal, Git loss, which leverages on softmax and center loss functions. The aim of our loss function is to minimize the intra-class variations as well as maximize the inter-class distances. Such minimization and maximization of deep features are considered ideal for face recognition task. We perform experiments on two popular face recognition benchmarks datasets and show that our proposed loss function achieves maximum separability between deep face features of different identities and achieves state-of-the-art accuracy on two major face recognition benchmark datasets: Labeled Faces in the Wild (LFW) and YouTube Faces (YTF). However, it should be noted that the major objective of Git loss is to achieve maximum separability between deep features of divergent identities.