 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Crop Segmentation in Satellite Image Time Series with Transformer Networks
Dec 02, 2024Recent studies have shown that Convolutional Neural Networks (CNNs) achieve impressive results in crop segmentation of Satellite Image Time Series (SITS). However, the emergence of transformer networks in various vision tasks raises the question of whether they can outperform CNNs in this task as well. This paper presents a revised version of the Transformer-based Swin UNETR model, specifically adapted for crop segmentation of SITS. The proposed model demonstrates significant advancements, achieving a validation accuracy of 96.14% and a test accuracy of 95.26% on the Munich dataset, surpassing the previous best results of 93.55% for validation and 92.94% for the test. Additionally, the model's performance on the Lombardia dataset is comparable to UNet3D and superior to FPN and DeepLabV3. Experiments of this study indicate that the model will likely achieve comparable or superior accuracy to CNNs while requiring significantly less training time. These findings highlight the potential of transformer-based architectures for crop segmentation in SITS, opening new avenues for remote sensing applications.
Mixing ADAM and SGD: a Combined Optimization Method
Nov 16, 2020
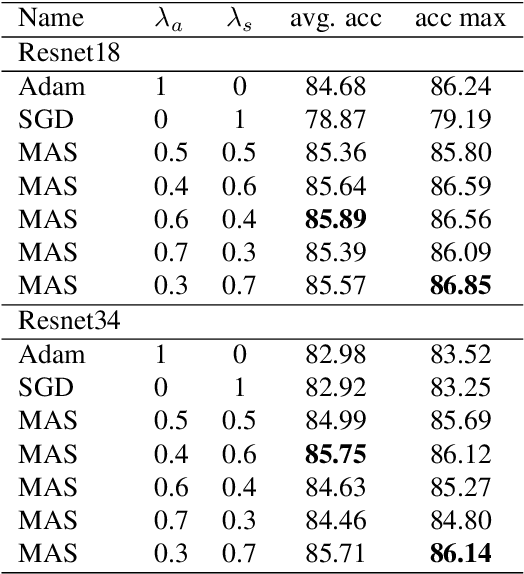
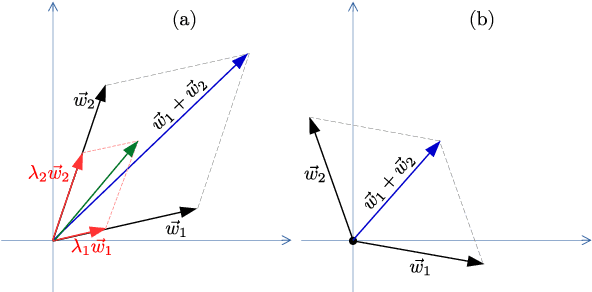
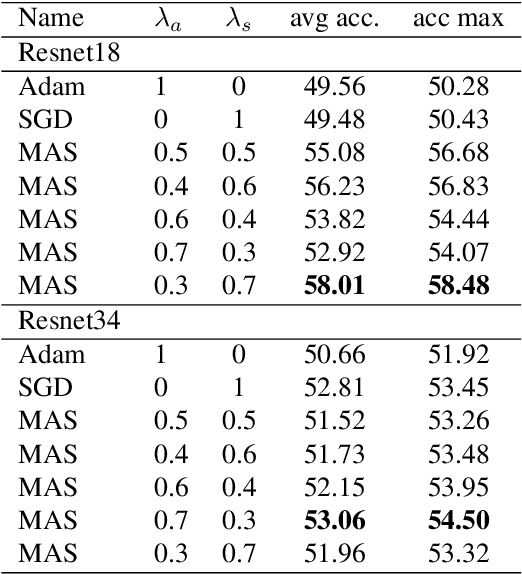
Optimization methods (optimizers) get special attention for the efficient training of neural networks in the field of deep learning. In literature there are many papers that compare neural models trained with the use of different optimizers. Each paper demonstrates that for a particular problem an optimizer is better than the others but as the problem changes this type of result is no longer valid and we have to start from scratch. In our paper we propose to use the combination of two very different optimizers but when used simultaneously they can overcome the performances of the single optimizers in very different problems. We propose a new optimizer called MAS (Mixing ADAM and SGD) that integrates SGD and ADAM simultaneously by weighing the contributions of both through the assignment of constant weights. Rather than trying to improve SGD or ADAM we exploit both at the same time by taking the best of both. We have conducted several experiments on images and text document classification, using various CNNs, and we demonstrated by experiments that the proposed MAS optimizer produces better performance than the single SGD or ADAM optimizers. The source code and all the results of the experiments are available online at the following link https://gitlab.com/nicolalandro/multi\_optimizer
$σ^2$R Loss: a Weighted Loss by Multiplicative Factors using Sigmoidal Functions
Sep 18, 2020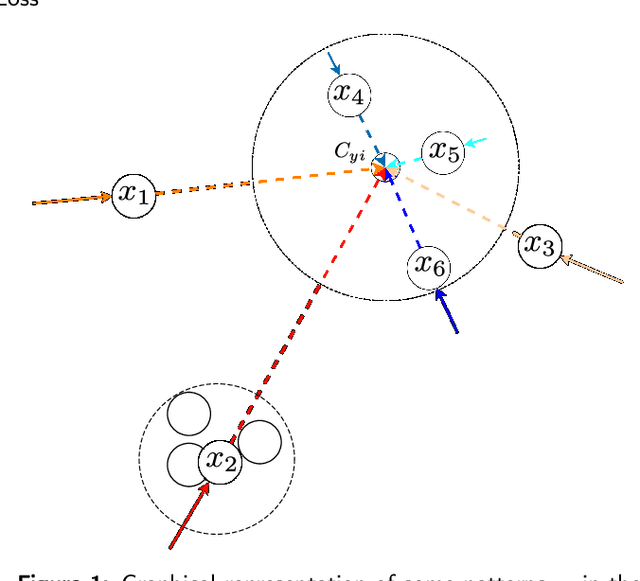
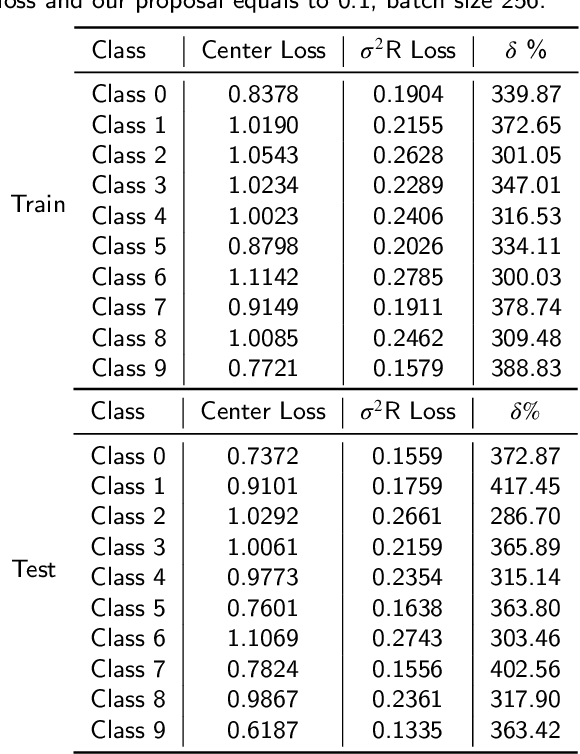
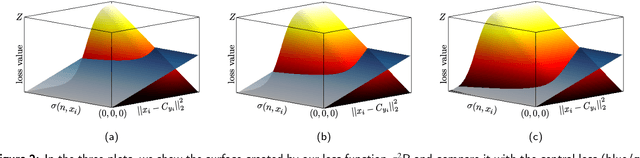
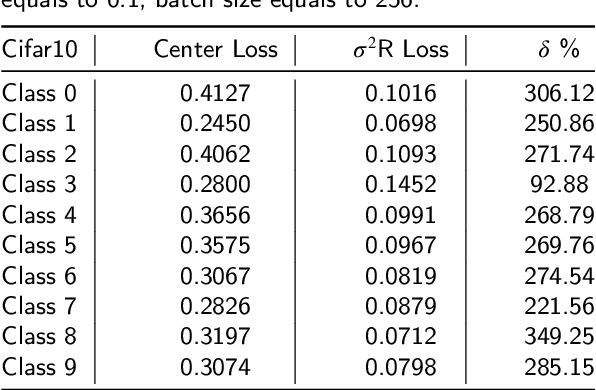
In neural networks, the loss function represents the core of the learning process that leads the optimizer to an approximation of the optimal convergence error. Convolutional neural networks (CNN) use the loss function as a supervisory signal to train a deep model and contribute significantly to achieving the state of the art in some fields of artificial vision. Cross-entropy and Center loss functions are commonly used to increase the discriminating power of learned functions and increase the generalization performance of the model. Center loss minimizes the class intra-class variance and at the same time penalizes the long distance between the deep features inside each class. However, the total error of the center loss will be heavily influenced by the majority of the instances and can lead to a freezing state in terms of intra-class variance. To address this, we introduce a new loss function called sigma squared reduction loss ($\sigma^2$R loss), which is regulated by a sigmoid function to inflate/deflate the error per instance and then continue to reduce the intra-class variance. Our loss has clear intuition and geometric interpretation, furthermore, we demonstrate by experiments the effectiveness of our proposal on several benchmark datasets showing the intra-class variance reduction and overcoming the results obtained with center loss and soft nearest neighbour functions.
Learn Class Hierarchy using Convolutional Neural Networks
May 18, 2020


A large amount of research on Convolutional Neural Networks has focused on flat Classification in the multi-class domain. In the real world, many problems are naturally expressed as problems of hierarchical classification, in which the classes to be predicted are organized in a hierarchy of classes. In this paper, we propose a new architecture for hierarchical classification of images, introducing a stack of deep linear layers with cross-entropy loss functions and center loss combined. The proposed architecture can extend any neural network model and simultaneously optimizes loss functions to discover local hierarchical class relationships and a loss function to discover global information from the whole class hierarchy while penalizing class hierarchy violations. We experimentally show that our hierarchical classifier presents advantages to the traditional classification approaches finding application in computer vision tasks.
Can a powerful neural network be a teacher for a weaker neural network?
May 07, 2020

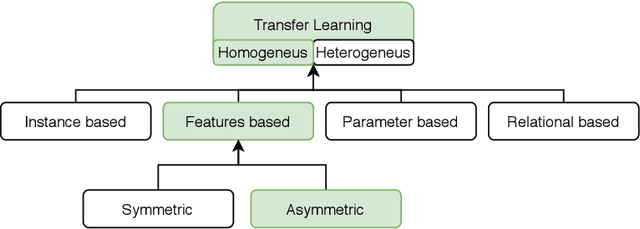
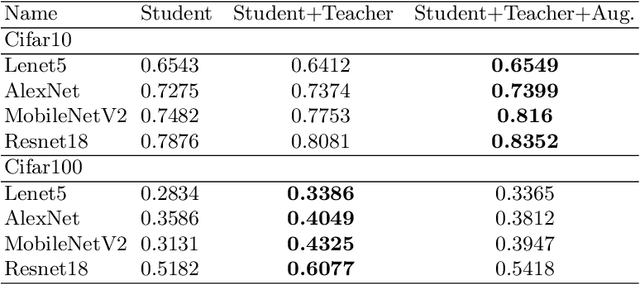
The transfer learning technique is widely used to learning in one context and applying it to another, i.e. the capacity to apply acquired knowledge and skills to new situations. But is it possible to transfer the learning from a deep neural network to a weaker neural network? Is it possible to improve the performance of a weak neural network using the knowledge acquired by a more powerful neural network? In this work, during the training process of a weak network, we add a loss function that minimizes the distance between the features previously learned from a strong neural network with the features that the weak network must try to learn. To demonstrate the effectiveness and robustness of our approach, we conducted a large number of experiments using three known datasets and demonstrated that a weak neural network can increase its performance if its learning process is driven by a more powerful neural network.
Dynamic Decision Boundary for One-class Classifiers applied to non-uniformly Sampled Data
Apr 05, 2020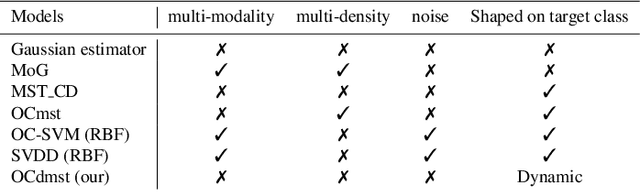
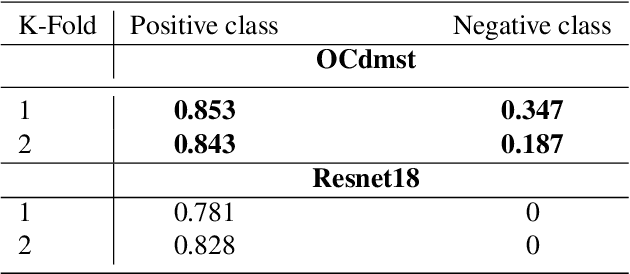
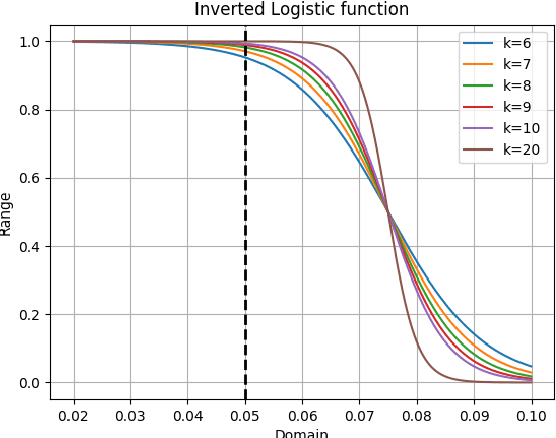
A typical issue in Pattern Recognition is the non-uniformly sampled data, which modifies the general performance and capability of machine learning algorithms to make accurate predictions. Generally, the data is considered non-uniformly sampled when in a specific area of data space, they are not enough, leading us to misclassification problems. This issue cut down the goal of the one-class classifiers decreasing their performance. In this paper, we propose a one-class classifier based on the minimum spanning tree with a dynamic decision boundary (OCdmst) to make good prediction also in the case we have non-uniformly sampled data. To prove the effectiveness and robustness of our approach we compare with the most recent one-class classifier reaching the state-of-the-art in most of them.
OCmst: One-class Novelty Detection using Convolutional Neural Network and Minimum Spanning Trees
Mar 30, 2020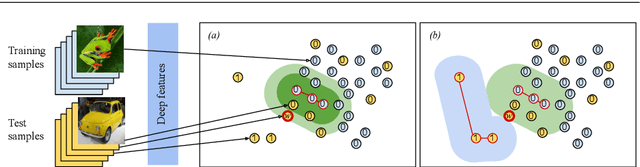
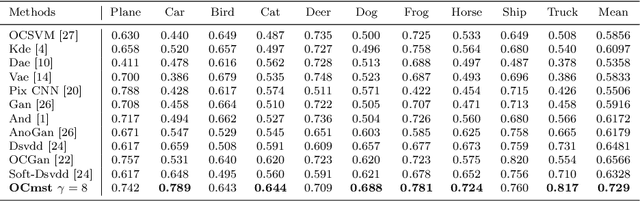


We present a novel model called One Class Minimum Spanning Tree (OCmst) for novelty detection problem that uses a Convolutional Neural Network (CNN) as deep feature extractor and graph-based model based on Minimum Spanning Tree (MST). In a novelty detection scenario, the training data is no polluted by outliers (abnormal class) and the goal is to recognize if a test instance belongs to the normal class or to the abnormal class. Our approach uses the deep features from CNN to feed a pair of MSTs built starting from each test instance. To cut down the computational time we use a parameter $\gamma$ to specify the size of the MST's starting to the neighbours from the test instance. To prove the effectiveness of the proposed approach we conducted experiments on two publicly available datasets, well-known in literature and we achieved the state-of-the-art results on CIFAR10 dataset.
Picture What you Read
Sep 09, 2019
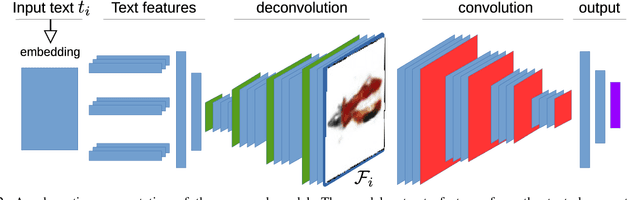

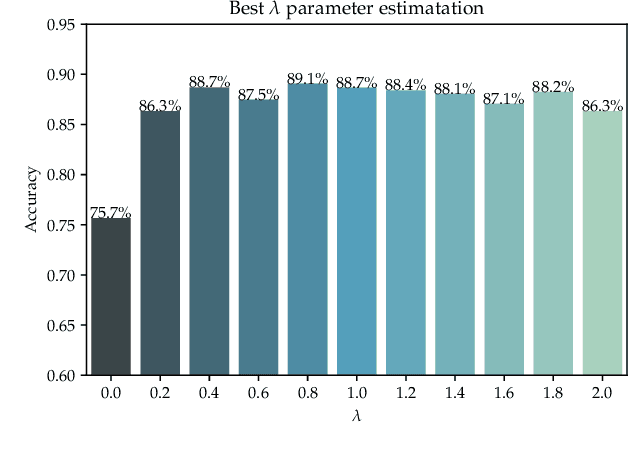
Visualization refers to our ability to create an image in our head based on the text we read or the words we hear. It is one of the many skills that makes reading comprehension possible. Convolutional Neural Networks (CNN) are an excellent tool for recognizing and classifying text documents. In addition, it can generate images conditioned on natural language. In this work, we utilize CNNs capabilities to generate realistic images representative of the text illustrating the semantic concept. We conducted various experiments to highlight the capacity of the proposed model to generate representative images of the text descriptions used as input to the proposed model.