 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$σ^2$R Loss: a Weighted Loss by Multiplicative Factors using Sigmoidal Functions
Paper and Code
Sep 18, 2020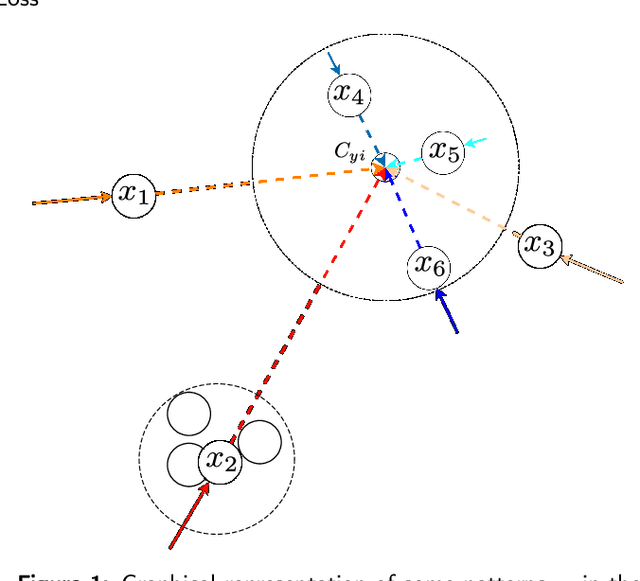
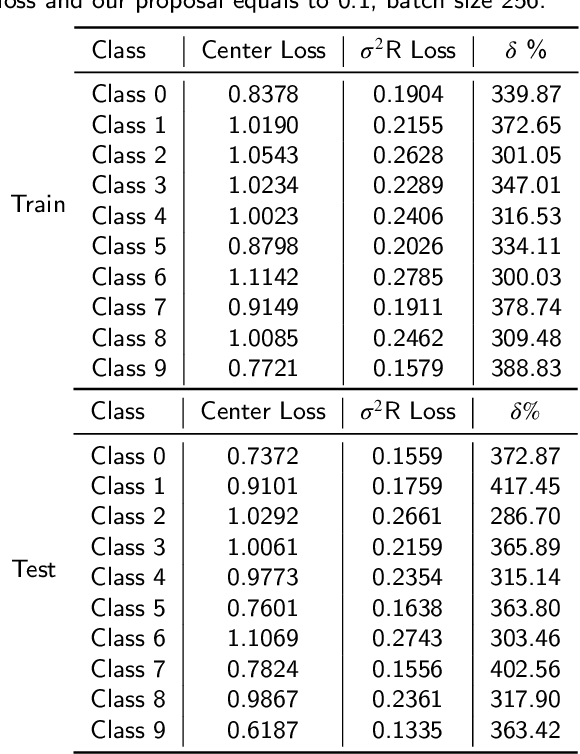
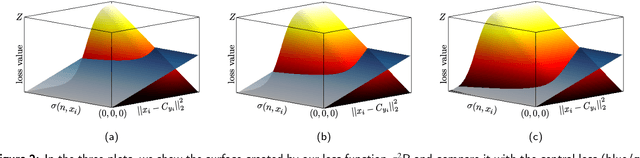
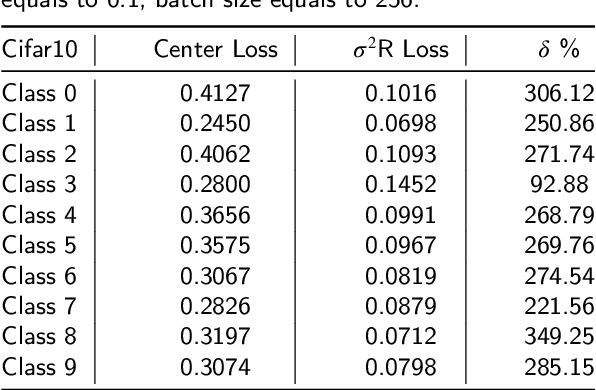
In neural networks, the loss function represents the core of the learning process that leads the optimizer to an approximation of the optimal convergence error. Convolutional neural networks (CNN) use the loss function as a supervisory signal to train a deep model and contribute significantly to achieving the state of the art in some fields of artificial vision. Cross-entropy and Center loss functions are commonly used to increase the discriminating power of learned functions and increase the generalization performance of the model. Center loss minimizes the class intra-class variance and at the same time penalizes the long distance between the deep features inside each class. However, the total error of the center loss will be heavily influenced by the majority of the instances and can lead to a freezing state in terms of intra-class variance. To address this, we introduce a new loss function called sigma squared reduction loss ($\sigma^2$R loss), which is regulated by a sigmoid function to inflate/deflate the error per instance and then continue to reduce the intra-class variance. Our loss has clear intuition and geometric interpretation, furthermore, we demonstrate by experiments the effectiveness of our proposal on several benchmark datasets showing the intra-class variance reduction and overcoming the results obtained with center loss and soft nearest neighbour functions.