 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage and Encoded Text Fusion for Multi-Modal Classification
Paper and Code
Oct 03, 2018
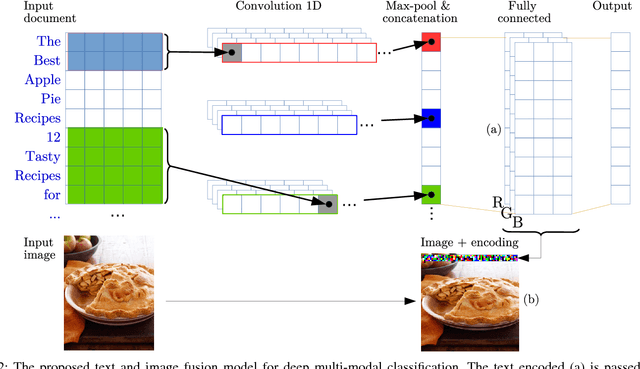

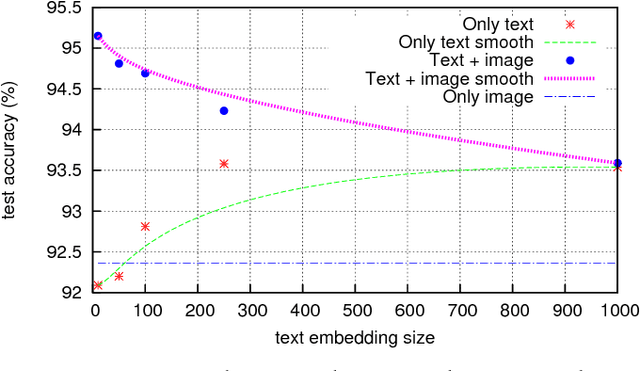
Multi-modal approaches employ data from multiple input streams such as textual and visual domains. Deep neural networks have been successfully employed for these approaches. In this paper, we present a novel multi-modal approach that fuses images and text descriptions to improve multi-modal classification performance in real-world scenarios. The proposed approach embeds an encoded text onto an image to obtain an information-enriched image. To learn feature representations of resulting images, standard Convolutional Neural Networks (CNNs) are employed for the classification task. We demonstrate how a CNN based pipeline can be used to learn representations of the novel fusion approach. We compare our approach with individual sources on two large-scale multi-modal classification datasets while obtaining encouraging results. Furthermore, we evaluate our approach against two famous multi-modal strategies namely early fusion and late fusion.