 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspAct: Enhancing LLM Situated Collaboration Skills through Perspective Taking and Active Vision
Nov 11, 2025Recent advances in Large Language Models (LLMs) and multimodal foundation models have significantly broadened their application in robotics and collaborative systems. However, effective multi-agent interaction necessitates robust perspective-taking capabilities, enabling models to interpret both physical and epistemic viewpoints. Current training paradigms often neglect these interactive contexts, resulting in challenges when models must reason about the subjectivity of individual perspectives or navigate environments with multiple observers. This study evaluates whether explicitly incorporating diverse points of view using the ReAct framework, an approach that integrates reasoning and acting, can enhance an LLM's ability to understand and ground the demands of other agents. We extend the classic Director task by introducing active visual exploration across a suite of seven scenarios of increasing perspective-taking complexity. These scenarios are designed to challenge the agent's capacity to resolve referential ambiguity based on visual access and interaction, under varying state representations and prompting strategies, including ReAct-style reasoning. Our results demonstrate that explicit perspective cues, combined with active exploration strategies, significantly improve the model's interpretative accuracy and collaborative effectiveness. These findings highlight the potential of integrating active perception with perspective-taking mechanisms in advancing LLMs' application in robotics and multi-agent systems, setting a foundation for future research into adaptive and context-aware AI systems.
Who Sees What? Structured Thought-Action Sequences for Epistemic Reasoning in LLMs
Aug 20, 2025Recent advances in large language models (LLMs) and reasoning frameworks have opened new possibilities for improving the perspective -taking capabilities of autonomous agents. However, tasks that involve active perception, collaborative reasoning, and perspective taking (understanding what another agent can see or knows) pose persistent challenges for current LLM-based systems. This study investigates the potential of structured examples derived from transformed solution graphs generated by the Fast Downward planner to improve the performance of LLM-based agents within a ReAct framework. We propose a structured solution-processing pipeline that generates three distinct categories of examples: optimal goal paths (G-type), informative node paths (E-type), and step-by-step optimal decision sequences contrasting alternative actions (L-type). These solutions are further converted into ``thought-action'' examples by prompting an LLM to explicitly articulate the reasoning behind each decision. While L-type examples slightly reduce clarification requests and overall action steps, they do not yield consistent improvements. Agents are successful in tasks requiring basic attentional filtering but struggle in scenarios that required mentalising about occluded spaces or weighing the costs of epistemic actions. These findings suggest that structured examples alone are insufficient for robust perspective-taking, underscoring the need for explicit belief tracking, cost modelling, and richer environments to enable socially grounded collaboration in LLM-based agents.
Combining Deep Architectures for Information Gain estimation and Reinforcement Learning for multiagent field exploration
May 29, 2025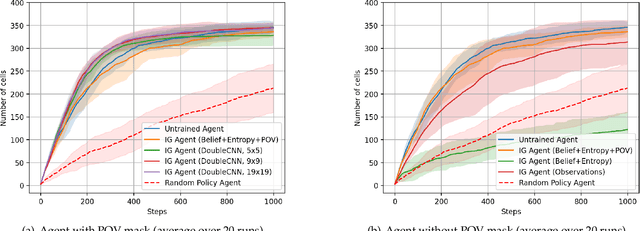
Precision agriculture requires efficient autonomous systems for crop monitoring, where agents must explore large-scale environments while minimizing resource consumption. This work addresses the problem as an active exploration task in a grid environment representing an agricultural field. Each cell may contain targets (e.g., damaged crops) observable from nine predefined points of view (POVs). Agents must infer the number of targets per cell using partial, sequential observations. We propose a two-stage deep learning framework. A pre-trained LSTM serves as a belief model, updating a probabilistic map of the environment and its associated entropy, which defines the expected information gain (IG). This allows agents to prioritize informative regions. A key contribution is the inclusion of a POV visibility mask in the input, preserving the Markov property under partial observability and avoiding revisits to already explored views. Three agent architectures were compared: an untrained IG-based agent selecting actions to maximize entropy reduction; a DQN agent using CNNs over local 3x3 inputs with belief, entropy, and POV mask; and a Double-CNN DQN agent with wider spatial context. Simulations on 20x20 maps showed that the untrained agent performs well despite its simplicity. The DQN agent matches this performance when the POV mask is included, while the Double-CNN agent consistently achieves superior exploration efficiency, especially in larger environments. Results show that uncertainty-aware policies leveraging entropy, belief states, and visibility tracking lead to robust and scalable exploration. Future work includes curriculum learning, multi-agent cooperation with shared rewards, transformer-based models, and intrinsic motivation mechanisms to further enhance learning efficiency and policy generalization.
Why am I seeing this? Towards recognizing social media recommender systems with missing recommendations
Apr 15, 2025Social media plays a crucial role in shaping society, often amplifying polarization and spreading misinformation. These effects stem from complex dynamics involving user interactions, individual traits, and recommender algorithms driving content selection. Recommender systems, which significantly shape the content users see and decisions they make, offer an opportunity for intervention and regulation. However, assessing their impact is challenging due to algorithmic opacity and limited data availability. To effectively model user decision-making, it is crucial to recognize the recommender system adopted by the platform. This work introduces a method for Automatic Recommender Recognition using Graph Neural Networks (GNNs), based solely on network structure and observed behavior. To infer the hidden recommender, we first train a Recommender Neutral User model (RNU) using a GNN and an adapted hindsight academic network recommender, aiming to reduce reliance on the actual recommender in the data. We then generate several Recommender Hypothesis-specific Synthetic Datasets (RHSD) by combining the RNU with different known recommenders, producing ground truths for testing. Finally, we train Recommender Hypothesis-specific User models (RHU) under various hypotheses and compare each candidate with the original used to generate the RHSD. Our approach enables accurate detection of hidden recommenders and their influence on user behavior. Unlike audit-based methods, it captures system behavior directly, without ad hoc experiments that often fail to reflect real platforms. This study provides insights into how recommenders shape behavior, aiding efforts to reduce polarization and misinformation.
Understanding Learner-LLM Chatbot Interactions and the Impact of Prompting Guidelines
Apr 10, 2025Large Language Models (LLMs) have transformed human-computer interaction by enabling natural language-based communication with AI-powered chatbots. These models are designed to be intuitive and user-friendly, allowing users to articulate requests with minimal effort. However, despite their accessibility, studies reveal that users often struggle with effective prompting, resulting in inefficient responses. Existing research has highlighted both the limitations of LLMs in interpreting vague or poorly structured prompts and the difficulties users face in crafting precise queries. This study investigates learner-AI interactions through an educational experiment in which participants receive structured guidance on effective prompting. We introduce and compare three types of prompting guidelines: a task-specific framework developed through a structured methodology and two baseline approaches. To assess user behavior and prompting efficacy, we analyze a dataset of 642 interactions from 107 users. Using Von NeuMidas, an extended pragmatic annotation schema for LLM interaction analysis, we categorize common prompting errors and identify recurring behavioral patterns. We then evaluate the impact of different guidelines by examining changes in user behavior, adherence to prompting strategies, and the overall quality of AI-generated responses. Our findings provide a deeper understanding of how users engage with LLMs and the role of structured prompting guidance in enhancing AI-assisted communication. By comparing different instructional frameworks, we offer insights into more effective approaches for improving user competency in AI interactions, with implications for AI literacy, chatbot usability, and the design of more responsive AI systems.
SCOOP: A Framework for Proactive Collaboration and Social Continual Learning through Natural Language Interaction andCausal Reasoning
Mar 13, 2025Multimodal information-gathering settings, where users collaborate with AI in dynamic environments, are increasingly common. These involve complex processes with textual and multimodal interactions, often requiring additional structural information via cost-incurring requests. AI helpers lack access to users' true goals, beliefs, and preferences and struggle to integrate diverse information effectively. We propose a social continual learning framework for causal knowledge acquisition and collaborative decision-making. It focuses on autonomous agents learning through dialogues, question-asking, and interaction in open, partially observable environments. A key component is a natural language oracle that answers the agent's queries about environmental mechanisms and states, refining causal understanding while balancing exploration or learning, and exploitation or knowledge use. Evaluation tasks inspired by developmental psychology emphasize causal reasoning and question-asking skills. They complement benchmarks by assessing the agent's ability to identify knowledge gaps, generate meaningful queries, and incrementally update reasoning. The framework also evaluates how knowledge acquisition costs are amortized across tasks within the same environment. We propose two architectures: 1) a system combining Large Language Models (LLMs) with the ReAct framework and question-generation, and 2) an advanced system with a causal world model, symbolic, graph-based, or subsymbolic, for reasoning and decision-making. The latter builds a causal knowledge graph for efficient inference and adaptability under constraints. Challenges include integrating causal reasoning into ReAct and optimizing exploration and question-asking in error-prone scenarios. Beyond applications, this framework models developmental processes combining causal reasoning, question generation, and social learning.
Use Me Wisely: AI-Driven Assessment for LLM Prompting Skills Development
Mar 04, 2025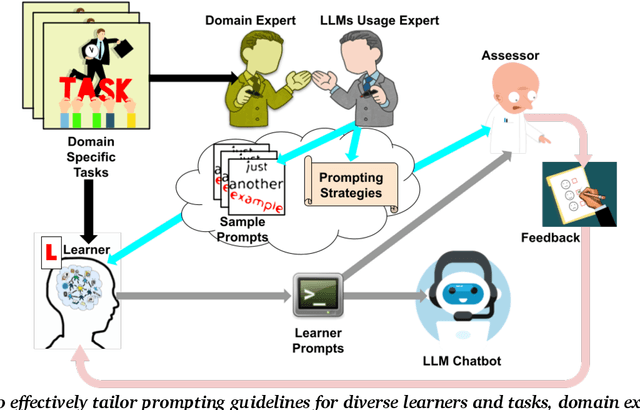
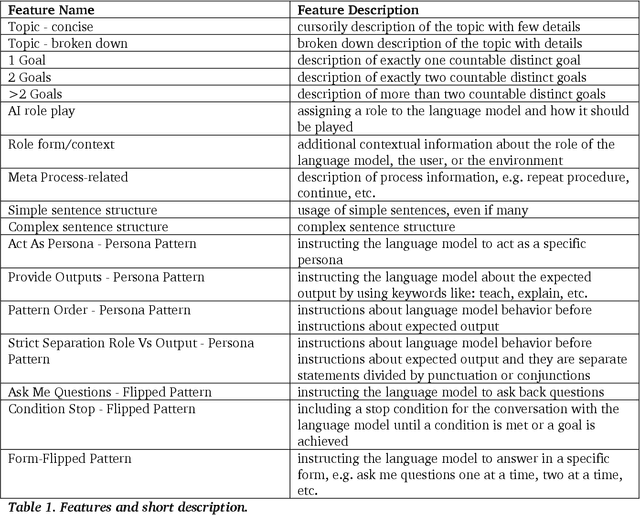
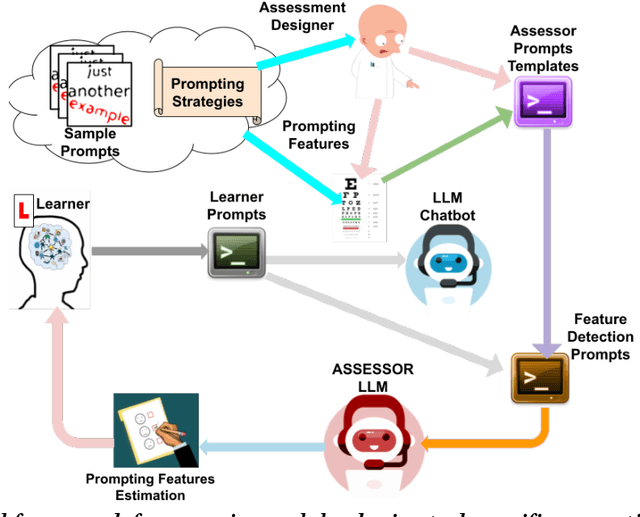
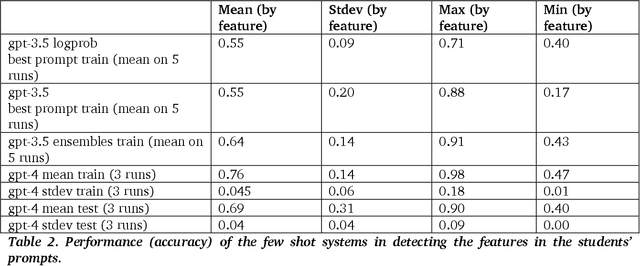
The use of large language model (LLM)-powered chatbots, such as ChatGPT, has become popular across various domains, supporting a range of tasks and processes. However, due to the intrinsic complexity of LLMs, effective prompting is more challenging than it may seem. This highlights the need for innovative educational and support strategies that are both widely accessible and seamlessly integrated into task workflows. Yet, LLM prompting is highly task- and domain-dependent, limiting the effectiveness of generic approaches. In this study, we explore whether LLM-based methods can facilitate learning assessments by using ad-hoc guidelines and a minimal number of annotated prompt samples. Our framework transforms these guidelines into features that can be identified within learners' prompts. Using these feature descriptions and annotated examples, we create few-shot learning detectors. We then evaluate different configurations of these detectors, testing three state-of-the-art LLMs and ensembles. We run experiments with cross-validation on a sample of original prompts, as well as tests on prompts collected from task-naive learners. Our results show how LLMs perform on feature detection. Notably, GPT- 4 demonstrates strong performance on most features, while closely related models, such as GPT-3 and GPT-3.5 Turbo (Instruct), show inconsistent behaviors in feature classification. These differences highlight the need for further research into how design choices impact feature selection and prompt detection. Our findings contribute to the fields of generative AI literacy and computer-supported learning assessment, offering valuable insights for both researchers and practitioners.
Unimib Assistant: designing a student-friendly RAG-based chatbot for all their needs
Nov 29, 2024



Natural language processing skills of Large Language Models (LLMs) are unprecedented, having wide diffusion and application in different tasks. This pilot study focuses on specializing ChatGPT behavior through a Retrieval-Augmented Generation (RAG) system using the OpenAI custom GPTs feature. The purpose of our chatbot, called Unimib Assistant, is to provide information and solutions to the specific needs of University of Milano-Bicocca (Unimib) students through a question-answering approach. We provided the system with a prompt highlighting its specific purpose and behavior, as well as university-related documents and links obtained from an initial need-finding phase, interviewing six students. After a preliminary customization phase, a qualitative usability test was conducted with six other students to identify the strengths and weaknesses of the chatbot, with the goal of improving it in a subsequent redesign phase. While the chatbot was appreciated for its user-friendly experience, perceived general reliability, well-structured responses, and conversational tone, several significant technical and functional limitations emerged. In particular, the satisfaction and overall experience of the users was impaired by the system's inability to always provide fully accurate information. Moreover, it would often neglect to report relevant information even if present in the materials uploaded and prompt given. Furthermore, it sometimes generated unclickable links, undermining its trustworthiness, since providing the source of information was an important aspect for our users. Further in-depth studies and feedback from other users as well as implementation iterations are planned to refine our Unimib Assistant.
Habit Coach: Customising RAG-based chatbots to support behavior change
Nov 28, 2024
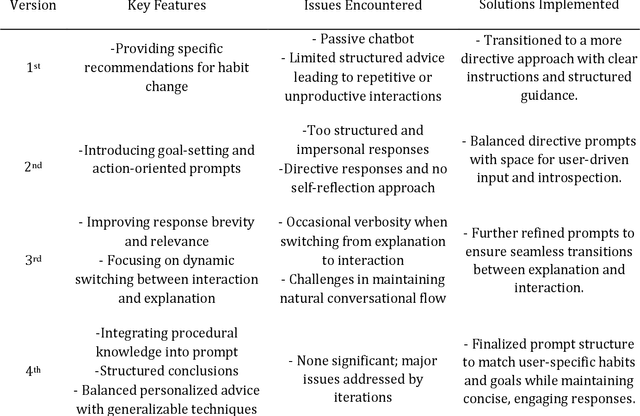
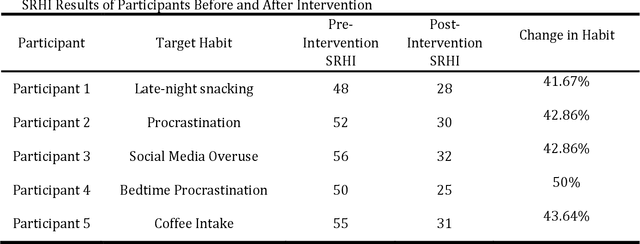
This paper presents the iterative development of Habit Coach, a GPT-based chatbot designed to support users in habit change through personalized interaction. Employing a user-centered design approach, we developed the chatbot using a Retrieval-Augmented Generation (RAG) system, which enables behavior personalization without retraining the underlying language model (GPT-4). The system leverages document retrieval and specialized prompts to tailor interactions, drawing from Cognitive Behavioral Therapy (CBT) and narrative therapy techniques. A key challenge in the development process was the difficulty of translating declarative knowledge into effective interaction behaviors. In the initial phase, the chatbot was provided with declarative knowledge about CBT via reference textbooks and high-level conversational goals. However, this approach resulted in imprecise and inefficient behavior, as the GPT model struggled to convert static information into dynamic and contextually appropriate interactions. This highlighted the limitations of relying solely on declarative knowledge to guide chatbot behavior, particularly in nuanced, therapeutic conversations. Over four iterations, we addressed this issue by gradually transitioning towards procedural knowledge, refining the chatbot's interaction strategies, and improving its overall effectiveness. In the final evaluation, 5 participants engaged with the chatbot over five consecutive days, receiving individualized CBT interventions. The Self-Report Habit Index (SRHI) was used to measure habit strength before and after the intervention, revealing a reduction in habit strength post-intervention. These results underscore the importance of procedural knowledge in driving effective, personalized behavior change support in RAG-based systems.
One to rule them all: natural language to bind communication, perception and action
Nov 22, 2024In recent years, research in the area of human-robot interaction has focused on developing robots capable of understanding complex human instructions and performing tasks in dynamic and diverse environments. These systems have a wide range of applications, from personal assistance to industrial robotics, emphasizing the importance of robots interacting flexibly, naturally and safely with humans. This paper presents an advanced architecture for robotic action planning that integrates communication, perception, and planning with Large Language Models (LLMs). Our system is designed to translate commands expressed in natural language into executable robot actions, incorporating environmental information and dynamically updating plans based on real-time feedback. The Planner Module is the core of the system where LLMs embedded in a modified ReAct framework are employed to interpret and carry out user commands. By leveraging their extensive pre-trained knowledge, LLMs can effectively process user requests without the need to introduce new knowledge on the changing environment. The modified ReAct framework further enhances the execution space by providing real-time environmental perception and the outcomes of physical actions. By combining robust and dynamic semantic map representations as graphs with control components and failure explanations, this architecture enhances a robot adaptability, task execution, and seamless collaboration with human users in shared and dynamic environments. Through the integration of continuous feedback loops with the environment the system can dynamically adjusts the plan to accommodate unexpected changes, optimizing the robot ability to perform tasks. Using a dataset of previous experience is possible to provide detailed feedback about the failure. Updating the LLMs context of the next iteration with suggestion on how to overcame the issue.