 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime is on my sight: scene graph filtering for dynamic environment perception in an LLM-driven robot
Paper and Code
Nov 22, 2024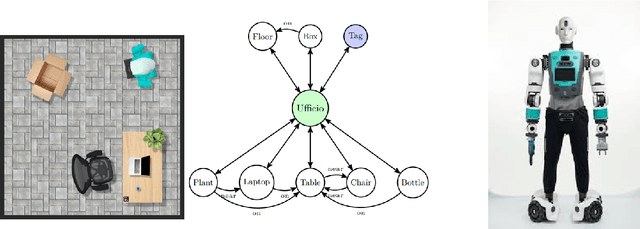

Robots are increasingly being used in dynamic environments like workplaces, hospitals, and homes. As a result, interactions with robots must be simple and intuitive, with robots perception adapting efficiently to human-induced changes. This paper presents a robot control architecture that addresses key challenges in human-robot interaction, with a particular focus on the dynamic creation and continuous update of the robot state representation. The architecture uses Large Language Models to integrate diverse information sources, including natural language commands, robotic skills representation, real-time dynamic semantic mapping of the perceived scene. This enables flexible and adaptive robotic behavior in complex, dynamic environments. Traditional robotic systems often rely on static, pre-programmed instructions and settings, limiting their adaptability to dynamic environments and real-time collaboration. In contrast, this architecture uses LLMs to interpret complex, high-level instructions and generate actionable plans that enhance human-robot collaboration. At its core, the system Perception Module generates and continuously updates a semantic scene graph using RGB-D sensor data, providing a detailed and structured representation of the environment. A particle filter is employed to ensure accurate object localization in dynamic, real-world settings. The Planner Module leverages this up-to-date semantic map to break down high-level tasks into sub-tasks and link them to robotic skills such as navigation, object manipulation (e.g., PICK and PLACE), and movement (e.g., GOTO). By combining real-time perception, state tracking, and LLM-driven communication and task planning, the architecture enhances adaptability, task efficiency, and human-robot collaboration in dynamic environments.