 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne to rule them all: natural language to bind communication, perception and action
Nov 22, 2024In recent years, research in the area of human-robot interaction has focused on developing robots capable of understanding complex human instructions and performing tasks in dynamic and diverse environments. These systems have a wide range of applications, from personal assistance to industrial robotics, emphasizing the importance of robots interacting flexibly, naturally and safely with humans. This paper presents an advanced architecture for robotic action planning that integrates communication, perception, and planning with Large Language Models (LLMs). Our system is designed to translate commands expressed in natural language into executable robot actions, incorporating environmental information and dynamically updating plans based on real-time feedback. The Planner Module is the core of the system where LLMs embedded in a modified ReAct framework are employed to interpret and carry out user commands. By leveraging their extensive pre-trained knowledge, LLMs can effectively process user requests without the need to introduce new knowledge on the changing environment. The modified ReAct framework further enhances the execution space by providing real-time environmental perception and the outcomes of physical actions. By combining robust and dynamic semantic map representations as graphs with control components and failure explanations, this architecture enhances a robot adaptability, task execution, and seamless collaboration with human users in shared and dynamic environments. Through the integration of continuous feedback loops with the environment the system can dynamically adjusts the plan to accommodate unexpected changes, optimizing the robot ability to perform tasks. Using a dataset of previous experience is possible to provide detailed feedback about the failure. Updating the LLMs context of the next iteration with suggestion on how to overcame the issue.
Time is on my sight: scene graph filtering for dynamic environment perception in an LLM-driven robot
Nov 22, 2024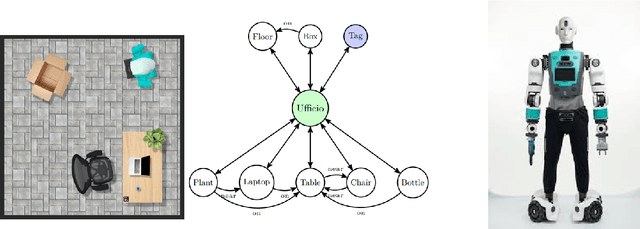

Robots are increasingly being used in dynamic environments like workplaces, hospitals, and homes. As a result, interactions with robots must be simple and intuitive, with robots perception adapting efficiently to human-induced changes. This paper presents a robot control architecture that addresses key challenges in human-robot interaction, with a particular focus on the dynamic creation and continuous update of the robot state representation. The architecture uses Large Language Models to integrate diverse information sources, including natural language commands, robotic skills representation, real-time dynamic semantic mapping of the perceived scene. This enables flexible and adaptive robotic behavior in complex, dynamic environments. Traditional robotic systems often rely on static, pre-programmed instructions and settings, limiting their adaptability to dynamic environments and real-time collaboration. In contrast, this architecture uses LLMs to interpret complex, high-level instructions and generate actionable plans that enhance human-robot collaboration. At its core, the system Perception Module generates and continuously updates a semantic scene graph using RGB-D sensor data, providing a detailed and structured representation of the environment. A particle filter is employed to ensure accurate object localization in dynamic, real-world settings. The Planner Module leverages this up-to-date semantic map to break down high-level tasks into sub-tasks and link them to robotic skills such as navigation, object manipulation (e.g., PICK and PLACE), and movement (e.g., GOTO). By combining real-time perception, state tracking, and LLM-driven communication and task planning, the architecture enhances adaptability, task efficiency, and human-robot collaboration in dynamic environments.
TPP-Gaze: Modelling Gaze Dynamics in Space and Time with Neural Temporal Point Processes
Oct 30, 2024

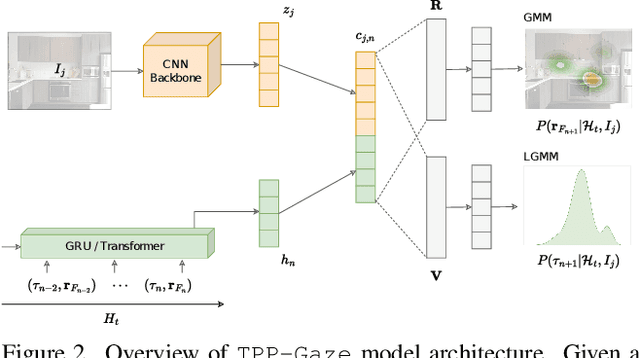

Attention guides our gaze to fixate the proper location of the scene and holds it in that location for the deserved amount of time given current processing demands, before shifting to the next one. As such, gaze deployment crucially is a temporal process. Existing computational models have made significant strides in predicting spatial aspects of observer's visual scanpaths (where to look), while often putting on the background the temporal facet of attention dynamics (when). In this paper we present TPP-Gaze, a novel and principled approach to model scanpath dynamics based on Neural Temporal Point Process (TPP), that jointly learns the temporal dynamics of fixations position and duration, integrating deep learning methodologies with point process theory. We conduct extensive experiments across five publicly available datasets. Our results show the overall superior performance of the proposed model compared to state-of-the-art approaches. Source code and trained models are publicly available at: https://github.com/phuselab/tppgaze.
Trends, Applications, and Challenges in Human Attention Modelling
Feb 28, 2024

Human attention modelling has proven, in recent years, to be particularly useful not only for understanding the cognitive processes underlying visual exploration, but also for providing support to artificial intelligence models that aim to solve problems in various domains, including image and video processing, vision-and-language applications, and language modelling. This survey offers a reasoned overview of recent efforts to integrate human attention mechanisms into contemporary deep learning models and discusses future research directions and challenges. For a comprehensive overview on the ongoing research refer to our dedicated repository available at https://github.com/aimagelab/awesome-human-visual-attention.
Advanced statistical methods for eye movement analysis and modeling: a gentle introduction
Aug 25, 2017

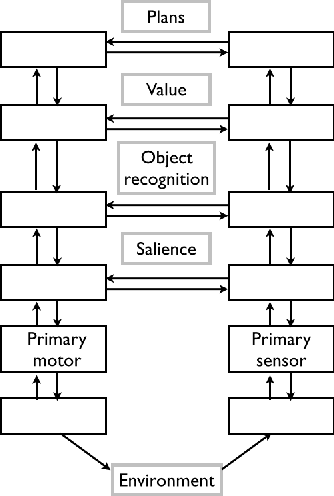

In this Chapter we show that by considering eye movements, and in particular, the resulting sequence of gaze shifts, a stochastic process, a wide variety of tools become available for analyses and modelling beyond conventional statistical methods. Such tools encompass random walk analyses and more complex techniques borrowed from the pattern recognition and machine learning fields. After a brief, though critical, probabilistic tour of current computational models of eye movements and visual attention, we lay down the basis for gaze shift pattern analysis. To this end, the concepts of Markov Processes, the Wiener process and related random walks within the Gaussian framework of the Central Limit Theorem will be introduced. Then, we will deliberately violate fundamental assumptions of the Central Limit Theorem to elicit a larger perspective, rooted in statistical physics, for analysing and modelling eye movements in terms of anomalous, non-Gaussian, random walks and modern foraging theory. Eventually, by resorting to machine learning techniques, we discuss how the analyses of movement patterns can develop into the inference of hidden patterns of the mind: inferring the observer's task, assessing cognitive impairments, classifying expertise.
A probabilistic tour of visual attention and gaze shift computational models
Jul 05, 2016


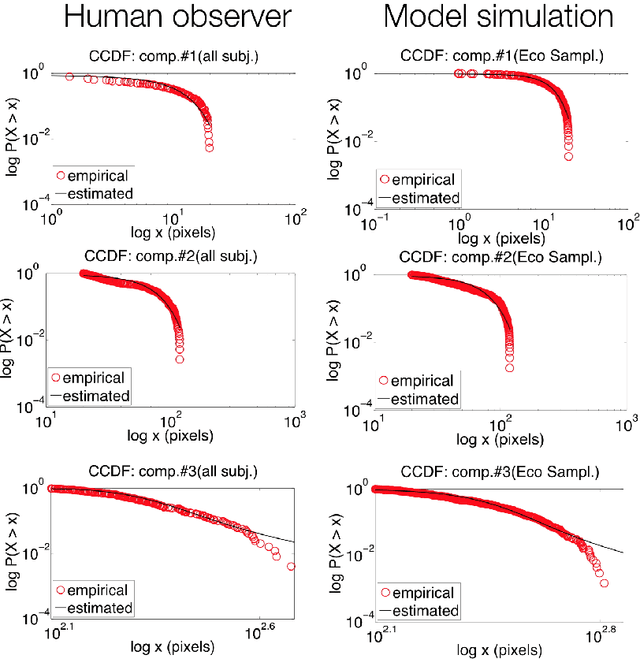
In this paper a number of problems are considered which are related to the modelling of eye guidance under visual attention in a natural setting. From a crude discussion of a variety of available models spelled in probabilistic terms, it appears that current approaches in computational vision are hitherto far from achieving the goal of an active observer relying upon eye guidance to accomplish real-world tasks. We argue that this challenging goal not only requires to embody, in a principled way, the problem of eye guidance within the action/perception loop, but to face the inextricable link tying up visual attention, emotion and executive control, in so far as recent neurobiological findings are weighed up.
The color of smiling: computational synaesthesia of facial expressions
May 16, 2015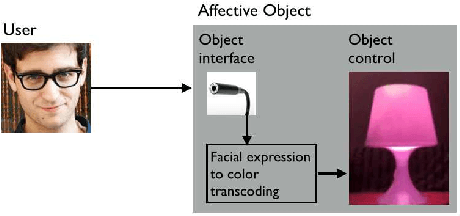

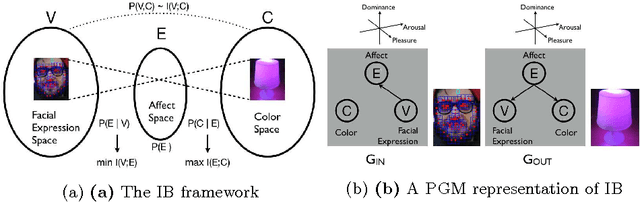
This note gives a preliminary account of the transcoding or rechanneling problem between different stimuli as it is of interest for the natural interaction or affective computing fields. By the consideration of a simple example, namely the color response of an affective lamp to a sensed facial expression, we frame the problem within an information- theoretic perspective. A full justification in terms of the Information Bottleneck principle promotes a latent affective space, hitherto surmised as an appealing and intuitive solution, as a suitable mediator between the different stimuli.
Attentive monitoring of multiple video streams driven by a Bayesian foraging strategy
Apr 27, 2015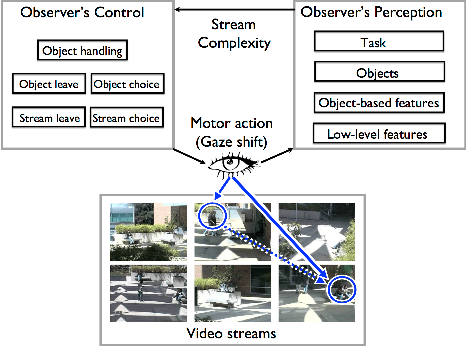
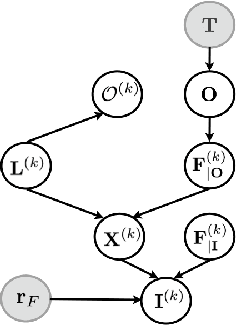
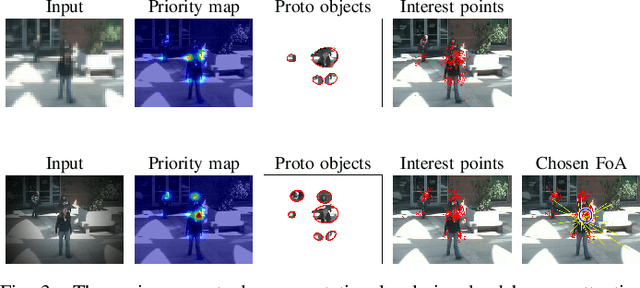
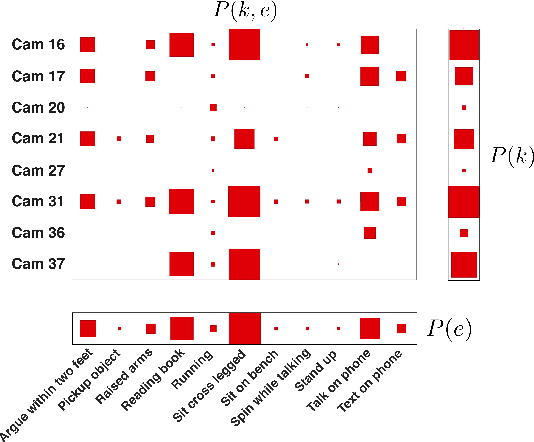
In this paper we shall consider the problem of deploying attention to subsets of the video streams for collating the most relevant data and information of interest related to a given task. We formalize this monitoring problem as a foraging problem. We propose a probabilistic framework to model observer's attentive behavior as the behavior of a forager. The forager, moment to moment, focuses its attention on the most informative stream/camera, detects interesting objects or activities, or switches to a more profitable stream. The approach proposed here is suitable to be exploited for multi-stream video summarization. Meanwhile, it can serve as a preliminary step for more sophisticated video surveillance, e.g. activity and behavior analysis. Experimental results achieved on the UCR Videoweb Activities Dataset, a publicly available dataset, are presented to illustrate the utility of the proposed technique.
Affective Facial Expression Processing via Simulation: A Probabilistic Model
Nov 03, 2014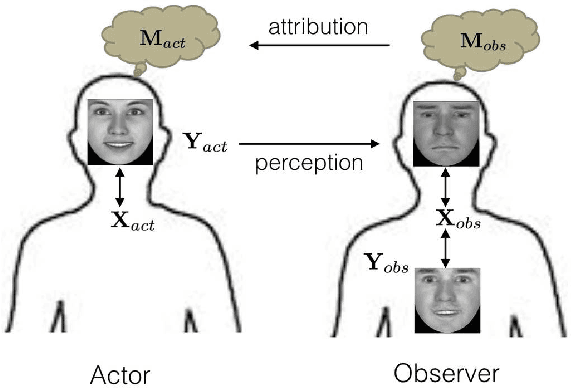
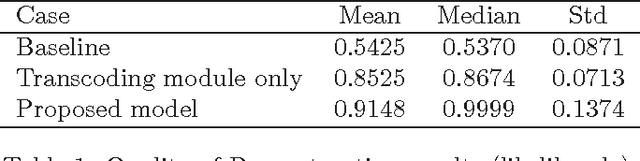
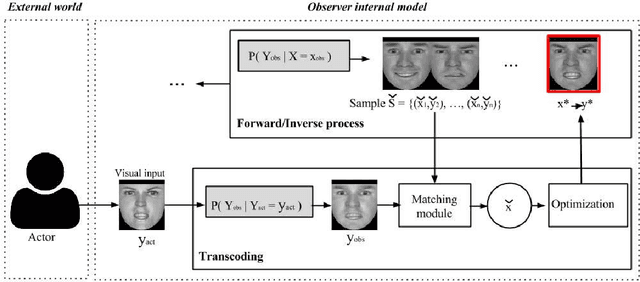

Understanding the mental state of other people is an important skill for intelligent agents and robots to operate within social environments. However, the mental processes involved in `mind-reading' are complex. One explanation of such processes is Simulation Theory - it is supported by a large body of neuropsychological research. Yet, determining the best computational model or theory to use in simulation-style emotion detection, is far from being understood. In this work, we use Simulation Theory and neuroscience findings on Mirror-Neuron Systems as the basis for a novel computational model, as a way to handle affective facial expressions. The model is based on a probabilistic mapping of observations from multiple identities onto a single fixed identity (`internal transcoding of external stimuli'), and then onto a latent space (`phenomenological response'). Together with the proposed architecture we present some promising preliminary results