 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing IMU-Based Online Handwriting Recognition via Contrastive Learning with Zero Inference Overhead
Feb 04, 2026Online handwriting recognition using inertial measurement units opens up handwriting on paper as input for digital devices. Doing it on edge hardware improves privacy and lowers latency, but entails memory constraints. To address this, we propose Error-enhanced Contrastive Handwriting Recognition (ECHWR), a training framework designed to improve feature representation and recognition accuracy without increasing inference costs. ECHWR utilizes a temporary auxiliary branch that aligns sensor signals with semantic text embeddings during the training phase. This alignment is maintained through a dual contrastive objective: an in-batch contrastive loss for general modality alignment and a novel error-based contrastive loss that distinguishes between correct signals and synthetic hard negatives. The auxiliary branch is discarded after training, which allows the deployed model to keep its original, efficient architecture. Evaluations on the OnHW-Words500 dataset show that ECHWR significantly outperforms state-of-the-art baselines, reducing character error rates by up to 7.4% on the writer-independent split and 10.4% on the writer-dependent split. Finally, although our ablation studies indicate that solving specific challenges require specific architectural and objective configurations, error-based contrastive loss shows its effectiveness for handling unseen writing styles.
Benchmarking Content-Based Puzzle Solvers on Corrupted Jigsaw Puzzles
Jul 10, 2025Content-based puzzle solvers have been extensively studied, demonstrating significant progress in computational techniques. However, their evaluation often lacks realistic challenges crucial for real-world applications, such as the reassembly of fragmented artefacts or shredded documents. In this work, we investigate the robustness of State-Of-The-Art content-based puzzle solvers introducing three types of jigsaw puzzle corruptions: missing pieces, eroded edges, and eroded contents. Evaluating both heuristic and deep learning-based solvers, we analyse their ability to handle these corruptions and identify key limitations. Our results show that solvers developed for standard puzzles have a rapid decline in performance if more pieces are corrupted. However, deep learning models can significantly improve their robustness through fine-tuning with augmented data. Notably, the advanced Positional Diffusion model adapts particularly well, outperforming its competitors in most experiments. Based on our findings, we highlight promising research directions for enhancing the automated reconstruction of real-world artefacts.
Understanding Cross-Model Perceptual Invariances Through Ensemble Metamers
Apr 02, 2025Understanding the perceptual invariances of artificial neural networks is essential for improving explainability and aligning models with human vision. Metamers - stimuli that are physically distinct yet produce identical neural activations - serve as a valuable tool for investigating these invariances. We introduce a novel approach to metamer generation by leveraging ensembles of artificial neural networks, capturing shared representational subspaces across diverse architectures, including convolutional neural networks and vision transformers. To characterize the properties of the generated metamers, we employ a suite of image-based metrics that assess factors such as semantic fidelity and naturalness. Our findings show that convolutional neural networks generate more recognizable and human-like metamers, while vision transformers produce realistic but less transferable metamers, highlighting the impact of architectural biases on representational invariances.
Robust and Efficient Writer-Independent IMU-Based Handwriting Recognization
Feb 28, 2025Online handwriting recognition (HWR) using data from inertial measurement units (IMUs) remains challenging due to variations in writing styles and the limited availability of high-quality annotated datasets. Traditional models often struggle to recognize handwriting from unseen writers, making writer-independent (WI) recognition a crucial but difficult problem. This paper presents an HWR model with an encoder-decoder structure for IMU data, featuring a CNN-based encoder for feature extraction and a BiLSTM decoder for sequence modeling, which supports inputs of varying lengths. Our approach demonstrates strong robustness and data efficiency, outperforming existing methods on WI datasets, including the WI split of the OnHW dataset and our own dataset. Extensive evaluations show that our model maintains high accuracy across different age groups and writing conditions while effectively learning from limited data. Through comprehensive ablation studies, we analyze key design choices, achieving a balance between accuracy and efficiency. These findings contribute to the development of more adaptable and scalable HWR systems for real-world applications.
Human-inspired Explanations for Vision Transformers and Convolutional Neural Networks
Aug 20, 2024We introduce Foveation-based Explanations (FovEx), a novel human-inspired visual explainability (XAI) method for Deep Neural Networks. Our method achieves state-of-the-art performance on both transformer (on 4 out of 5 metrics) and convolutional models (on 3 out of 5 metrics), demonstrating its versatility. Furthermore, we show the alignment between the explanation map produced by FovEx and human gaze patterns (+14\% in NSS compared to RISE, +203\% in NSS compared to gradCAM), enhancing our confidence in FovEx's ability to close the interpretation gap between humans and machines.
Caption-Driven Explorations: Aligning Image and Text Embeddings through Human-Inspired Foveated Vision
Aug 19, 2024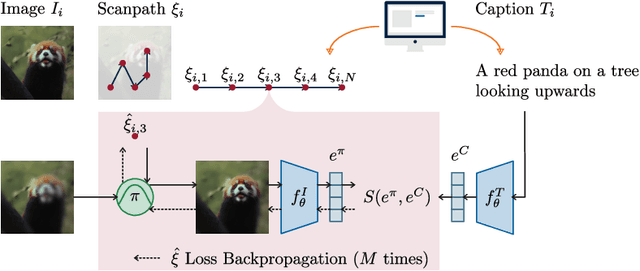

Understanding human attention is crucial for vision science and AI. While many models exist for free-viewing, less is known about task-driven image exploration. To address this, we introduce CapMIT1003, a dataset with captions and click-contingent image explorations, to study human attention during the captioning task. We also present NevaClip, a zero-shot method for predicting visual scanpaths by combining CLIP models with NeVA algorithms. NevaClip generates fixations to align the representations of foveated visual stimuli and captions. The simulated scanpaths outperform existing human attention models in plausibility for captioning and free-viewing tasks. This research enhances the understanding of human attention and advances scanpath prediction models.
FovEx: Human-inspired Explanations for Vision Transformers and Convolutional Neural Networks
Aug 04, 2024Explainability in artificial intelligence (XAI) remains a crucial aspect for fostering trust and understanding in machine learning models. Current visual explanation techniques, such as gradient-based or class-activation-based methods, often exhibit a strong dependence on specific model architectures. Conversely, perturbation-based methods, despite being model-agnostic, are computationally expensive as they require evaluating models on a large number of forward passes. In this work, we introduce Foveation-based Explanations (FovEx), a novel XAI method inspired by human vision. FovEx seamlessly integrates biologically inspired perturbations by iteratively creating foveated renderings of the image and combines them with gradient-based visual explorations to determine locations of interest efficiently. These locations are selected to maximize the performance of the model to be explained with respect to the downstream task and then combined to generate an attribution map. We provide a thorough evaluation with qualitative and quantitative assessments on established benchmarks. Our method achieves state-of-the-art performance on both transformers (on 4 out of 5 metrics) and convolutional models (on 3 out of 5 metrics), demonstrating its versatility among various architectures. Furthermore, we show the alignment between the explanation map produced by FovEx and human gaze patterns (+14\% in NSS compared to RISE, +203\% in NSS compared to GradCAM). This comparison enhances our confidence in FovEx's ability to close the interpretation gap between humans and machines.
How Intermodal Interaction Affects the Performance of Deep Multimodal Fusion for Mixed-Type Time Series
Jun 21, 2024Mixed-type time series (MTTS) is a bimodal data type that is common in many domains, such as healthcare, finance, environmental monitoring, and social media. It consists of regularly sampled continuous time series and irregularly sampled categorical event sequences. The integration of both modalities through multimodal fusion is a promising approach for processing MTTS. However, the question of how to effectively fuse both modalities remains open. In this paper, we present a comprehensive evaluation of several deep multimodal fusion approaches for MTTS forecasting. Our comparison includes three fusion types (early, intermediate, and late) and five fusion methods (concatenation, weighted mean, weighted mean with correlation, gating, and feature sharing). We evaluate these fusion approaches on three distinct datasets, one of which was generated using a novel framework. This framework allows for the control of key data properties, such as the strength and direction of intermodal interactions, modality imbalance, and the degree of randomness in each modality, providing a more controlled environment for testing fusion approaches. Our findings show that the performance of different fusion approaches can be substantially influenced by the direction and strength of intermodal interactions. The study reveals that early and intermediate fusion approaches excel at capturing fine-grained and coarse-grained cross-modal features, respectively. These findings underscore the crucial role of intermodal interactions in determining the most effective fusion strategy for MTTS forecasting.
Trends, Applications, and Challenges in Human Attention Modelling
Feb 28, 2024

Human attention modelling has proven, in recent years, to be particularly useful not only for understanding the cognitive processes underlying visual exploration, but also for providing support to artificial intelligence models that aim to solve problems in various domains, including image and video processing, vision-and-language applications, and language modelling. This survey offers a reasoned overview of recent efforts to integrate human attention mechanisms into contemporary deep learning models and discusses future research directions and challenges. For a comprehensive overview on the ongoing research refer to our dedicated repository available at https://github.com/aimagelab/awesome-human-visual-attention.
Contrastive Language-Image Pretrained Models are Zero-Shot Human Scanpath Predictors
May 23, 2023
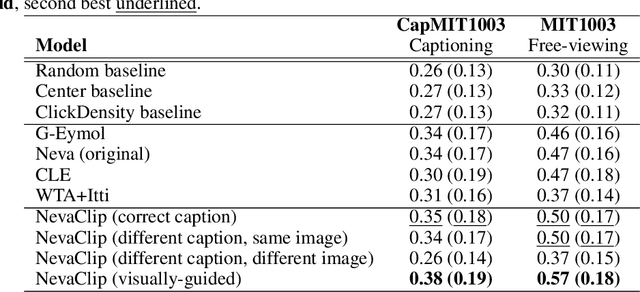

Understanding the mechanisms underlying human attention is a fundamental challenge for both vision science and artificial intelligence. While numerous computational models of free-viewing have been proposed, less is known about the mechanisms underlying task-driven image exploration. To address this gap, we present CapMIT1003, a database of captions and click-contingent image explorations collected during captioning tasks. CapMIT1003 is based on the same stimuli from the well-known MIT1003 benchmark, for which eye-tracking data under free-viewing conditions is available, which offers a promising opportunity to concurrently study human attention under both tasks. We make this dataset publicly available to facilitate future research in this field. In addition, we introduce NevaClip, a novel zero-shot method for predicting visual scanpaths that combines contrastive language-image pretrained (CLIP) models with biologically-inspired neural visual attention (NeVA) algorithms. NevaClip simulates human scanpaths by aligning the representation of the foveated visual stimulus and the representation of the associated caption, employing gradient-driven visual exploration to generate scanpaths. Our experimental results demonstrate that NevaClip outperforms existing unsupervised computational models of human visual attention in terms of scanpath plausibility, for both captioning and free-viewing tasks. Furthermore, we show that conditioning NevaClip with incorrect or misleading captions leads to random behavior, highlighting the significant impact of caption guidance in the decision-making process. These findings contribute to a better understanding of mechanisms that guide human attention and pave the way for more sophisticated computational approaches to scanpath prediction that can integrate direct top-down guidance of downstream tasks.