 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaption-Driven Explorations: Aligning Image and Text Embeddings through Human-Inspired Foveated Vision
Paper and Code
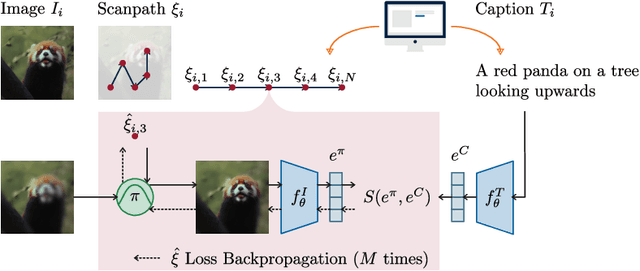

Understanding human attention is crucial for vision science and AI. While many models exist for free-viewing, less is known about task-driven image exploration. To address this, we introduce CapMIT1003, a dataset with captions and click-contingent image explorations, to study human attention during the captioning task. We also present NevaClip, a zero-shot method for predicting visual scanpaths by combining CLIP models with NeVA algorithms. NevaClip generates fixations to align the representations of foveated visual stimuli and captions. The simulated scanpaths outperform existing human attention models in plausibility for captioning and free-viewing tasks. This research enhances the understanding of human attention and advances scanpath prediction models.