 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaption-Driven Explorations: Aligning Image and Text Embeddings through Human-Inspired Foveated Vision
Aug 19, 2024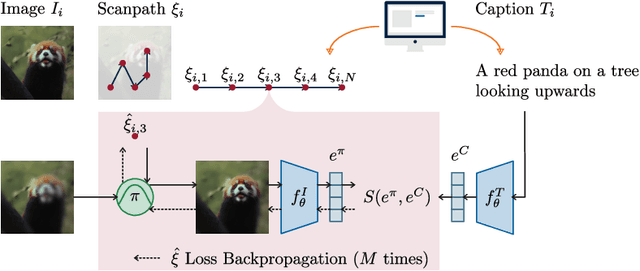

Understanding human attention is crucial for vision science and AI. While many models exist for free-viewing, less is known about task-driven image exploration. To address this, we introduce CapMIT1003, a dataset with captions and click-contingent image explorations, to study human attention during the captioning task. We also present NevaClip, a zero-shot method for predicting visual scanpaths by combining CLIP models with NeVA algorithms. NevaClip generates fixations to align the representations of foveated visual stimuli and captions. The simulated scanpaths outperform existing human attention models in plausibility for captioning and free-viewing tasks. This research enhances the understanding of human attention and advances scanpath prediction models.
Contrastive Language-Image Pretrained Models are Zero-Shot Human Scanpath Predictors
May 23, 2023
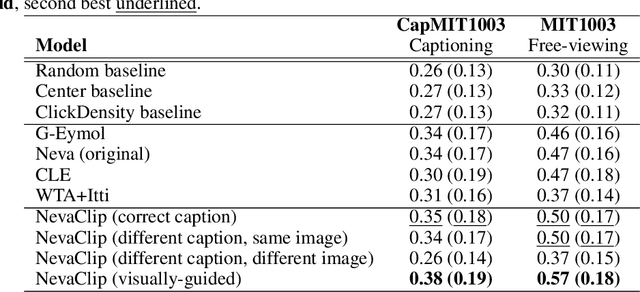

Understanding the mechanisms underlying human attention is a fundamental challenge for both vision science and artificial intelligence. While numerous computational models of free-viewing have been proposed, less is known about the mechanisms underlying task-driven image exploration. To address this gap, we present CapMIT1003, a database of captions and click-contingent image explorations collected during captioning tasks. CapMIT1003 is based on the same stimuli from the well-known MIT1003 benchmark, for which eye-tracking data under free-viewing conditions is available, which offers a promising opportunity to concurrently study human attention under both tasks. We make this dataset publicly available to facilitate future research in this field. In addition, we introduce NevaClip, a novel zero-shot method for predicting visual scanpaths that combines contrastive language-image pretrained (CLIP) models with biologically-inspired neural visual attention (NeVA) algorithms. NevaClip simulates human scanpaths by aligning the representation of the foveated visual stimulus and the representation of the associated caption, employing gradient-driven visual exploration to generate scanpaths. Our experimental results demonstrate that NevaClip outperforms existing unsupervised computational models of human visual attention in terms of scanpath plausibility, for both captioning and free-viewing tasks. Furthermore, we show that conditioning NevaClip with incorrect or misleading captions leads to random behavior, highlighting the significant impact of caption guidance in the decision-making process. These findings contribute to a better understanding of mechanisms that guide human attention and pave the way for more sophisticated computational approaches to scanpath prediction that can integrate direct top-down guidance of downstream tasks.