 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContraLog: Log File Anomaly Detection with Contrastive Learning and Masked Language Modeling
Feb 03, 2026Log files record computational events that reflect system state and behavior, making them a primary source of operational insights in modern computer systems. Automated anomaly detection on logs is therefore critical, yet most established methods rely on log parsers that collapse messages into discrete templates, discarding variable values and semantic content. We propose ContraLog, a parser-free and self-supervised method that reframes log anomaly detection as predicting continuous message embeddings rather than discrete template IDs. ContraLog combines a message encoder that produces rich embeddings for individual log messages with a sequence encoder to model temporal dependencies within sequences. The model is trained with a combination of masked language modeling and contrastive learning to predict masked message embeddings based on the surrounding context. Experiments on the HDFS, BGL, and Thunderbird benchmark datasets empirically demonstrate effectiveness on complex datasets with diverse log messages. Additionally, we find that message embeddings generated by ContraLog carry meaningful information and are predictive of anomalies even without sequence context. These results highlight embedding-level prediction as an approach for log anomaly detection, with potential applicability to other event sequences.
Caption-Driven Explorations: Aligning Image and Text Embeddings through Human-Inspired Foveated Vision
Aug 19, 2024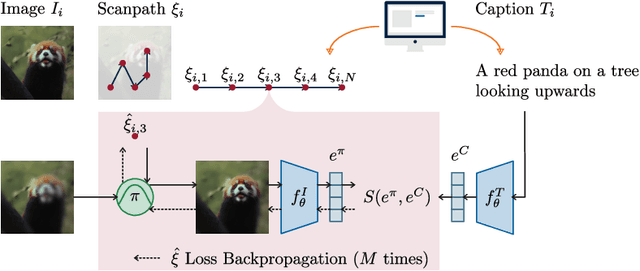

Understanding human attention is crucial for vision science and AI. While many models exist for free-viewing, less is known about task-driven image exploration. To address this, we introduce CapMIT1003, a dataset with captions and click-contingent image explorations, to study human attention during the captioning task. We also present NevaClip, a zero-shot method for predicting visual scanpaths by combining CLIP models with NeVA algorithms. NevaClip generates fixations to align the representations of foveated visual stimuli and captions. The simulated scanpaths outperform existing human attention models in plausibility for captioning and free-viewing tasks. This research enhances the understanding of human attention and advances scanpath prediction models.
How Intermodal Interaction Affects the Performance of Deep Multimodal Fusion for Mixed-Type Time Series
Jun 21, 2024Mixed-type time series (MTTS) is a bimodal data type that is common in many domains, such as healthcare, finance, environmental monitoring, and social media. It consists of regularly sampled continuous time series and irregularly sampled categorical event sequences. The integration of both modalities through multimodal fusion is a promising approach for processing MTTS. However, the question of how to effectively fuse both modalities remains open. In this paper, we present a comprehensive evaluation of several deep multimodal fusion approaches for MTTS forecasting. Our comparison includes three fusion types (early, intermediate, and late) and five fusion methods (concatenation, weighted mean, weighted mean with correlation, gating, and feature sharing). We evaluate these fusion approaches on three distinct datasets, one of which was generated using a novel framework. This framework allows for the control of key data properties, such as the strength and direction of intermodal interactions, modality imbalance, and the degree of randomness in each modality, providing a more controlled environment for testing fusion approaches. Our findings show that the performance of different fusion approaches can be substantially influenced by the direction and strength of intermodal interactions. The study reveals that early and intermediate fusion approaches excel at capturing fine-grained and coarse-grained cross-modal features, respectively. These findings underscore the crucial role of intermodal interactions in determining the most effective fusion strategy for MTTS forecasting.
Contrastive Language-Image Pretrained Models are Zero-Shot Human Scanpath Predictors
May 23, 2023
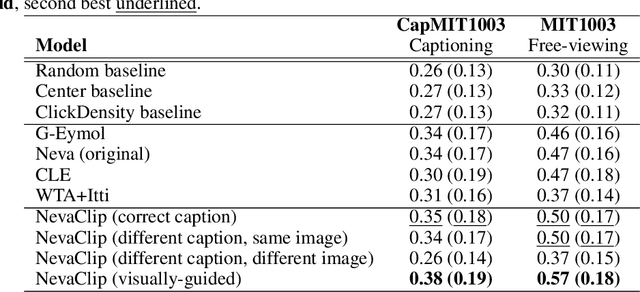

Understanding the mechanisms underlying human attention is a fundamental challenge for both vision science and artificial intelligence. While numerous computational models of free-viewing have been proposed, less is known about the mechanisms underlying task-driven image exploration. To address this gap, we present CapMIT1003, a database of captions and click-contingent image explorations collected during captioning tasks. CapMIT1003 is based on the same stimuli from the well-known MIT1003 benchmark, for which eye-tracking data under free-viewing conditions is available, which offers a promising opportunity to concurrently study human attention under both tasks. We make this dataset publicly available to facilitate future research in this field. In addition, we introduce NevaClip, a novel zero-shot method for predicting visual scanpaths that combines contrastive language-image pretrained (CLIP) models with biologically-inspired neural visual attention (NeVA) algorithms. NevaClip simulates human scanpaths by aligning the representation of the foveated visual stimulus and the representation of the associated caption, employing gradient-driven visual exploration to generate scanpaths. Our experimental results demonstrate that NevaClip outperforms existing unsupervised computational models of human visual attention in terms of scanpath plausibility, for both captioning and free-viewing tasks. Furthermore, we show that conditioning NevaClip with incorrect or misleading captions leads to random behavior, highlighting the significant impact of caption guidance in the decision-making process. These findings contribute to a better understanding of mechanisms that guide human attention and pave the way for more sophisticated computational approaches to scanpath prediction that can integrate direct top-down guidance of downstream tasks.