 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContraLog: Log File Anomaly Detection with Contrastive Learning and Masked Language Modeling
Feb 03, 2026Log files record computational events that reflect system state and behavior, making them a primary source of operational insights in modern computer systems. Automated anomaly detection on logs is therefore critical, yet most established methods rely on log parsers that collapse messages into discrete templates, discarding variable values and semantic content. We propose ContraLog, a parser-free and self-supervised method that reframes log anomaly detection as predicting continuous message embeddings rather than discrete template IDs. ContraLog combines a message encoder that produces rich embeddings for individual log messages with a sequence encoder to model temporal dependencies within sequences. The model is trained with a combination of masked language modeling and contrastive learning to predict masked message embeddings based on the surrounding context. Experiments on the HDFS, BGL, and Thunderbird benchmark datasets empirically demonstrate effectiveness on complex datasets with diverse log messages. Additionally, we find that message embeddings generated by ContraLog carry meaningful information and are predictive of anomalies even without sequence context. These results highlight embedding-level prediction as an approach for log anomaly detection, with potential applicability to other event sequences.
Ridge partial correlation screening for ultrahigh-dimensional data
Apr 27, 2025

Variable selection in ultrahigh-dimensional linear regression is challenging due to its high computational cost. Therefore, a screening step is usually conducted before variable selection to significantly reduce the dimension. Here we propose a novel and simple screening method based on ordering the absolute sample ridge partial correlations. The proposed method takes into account not only the ridge regularized estimates of the regression coefficients but also the ridge regularized partial variances of the predictor variables providing sure screening property without strong assumptions on the marginal correlations. Simulation study and a real data analysis show that the proposed method has a competitive performance compared with the existing screening procedures. A publicly available software implementing the proposed screening accompanies the article.
How Intermodal Interaction Affects the Performance of Deep Multimodal Fusion for Mixed-Type Time Series
Jun 21, 2024Mixed-type time series (MTTS) is a bimodal data type that is common in many domains, such as healthcare, finance, environmental monitoring, and social media. It consists of regularly sampled continuous time series and irregularly sampled categorical event sequences. The integration of both modalities through multimodal fusion is a promising approach for processing MTTS. However, the question of how to effectively fuse both modalities remains open. In this paper, we present a comprehensive evaluation of several deep multimodal fusion approaches for MTTS forecasting. Our comparison includes three fusion types (early, intermediate, and late) and five fusion methods (concatenation, weighted mean, weighted mean with correlation, gating, and feature sharing). We evaluate these fusion approaches on three distinct datasets, one of which was generated using a novel framework. This framework allows for the control of key data properties, such as the strength and direction of intermodal interactions, modality imbalance, and the degree of randomness in each modality, providing a more controlled environment for testing fusion approaches. Our findings show that the performance of different fusion approaches can be substantially influenced by the direction and strength of intermodal interactions. The study reveals that early and intermediate fusion approaches excel at capturing fine-grained and coarse-grained cross-modal features, respectively. These findings underscore the crucial role of intermodal interactions in determining the most effective fusion strategy for MTTS forecasting.
Mixture of Experts Meets Prompt-Based Continual Learning
May 23, 2024Exploiting the power of pre-trained models, prompt-based approaches stand out compared to other continual learning solutions in effectively preventing catastrophic forgetting, even with very few learnable parameters and without the need for a memory buffer. While existing prompt-based continual learning methods excel in leveraging prompts for state-of-the-art performance, they often lack a theoretical explanation for the effectiveness of prompting. This paper conducts a theoretical analysis to unravel how prompts bestow such advantages in continual learning, thus offering a new perspective on prompt design. We first show that the attention block of pre-trained models like Vision Transformers inherently encodes a special mixture of experts architecture, characterized by linear experts and quadratic gating score functions. This realization drives us to provide a novel view on prefix tuning, reframing it as the addition of new task-specific experts, thereby inspiring the design of a novel gating mechanism termed Non-linear Residual Gates (NoRGa). Through the incorporation of non-linear activation and residual connection, NoRGa enhances continual learning performance while preserving parameter efficiency. The effectiveness of NoRGa is substantiated both theoretically and empirically across diverse benchmarks and pretraining paradigms.
Just a Matter of Scale? Reevaluating Scale Equivariance in Convolutional Neural Networks
Nov 18, 2022The widespread success of convolutional neural networks may largely be attributed to their intrinsic property of translation equivariance. However, convolutions are not equivariant to variations in scale and fail to generalize to objects of different sizes. Despite recent advances in this field, it remains unclear how well current methods generalize to unobserved scales on real-world data and to what extent scale equivariance plays a role. To address this, we propose the novel Scaled and Translated Image Recognition (STIR) benchmark based on four different domains. Additionally, we introduce a new family of models that applies many re-scaled kernels with shared weights in parallel and then selects the most appropriate one. Our experimental results on STIR show that both the existing and proposed approaches can improve generalization across scales compared to standard convolutions. We also demonstrate that our family of models is able to generalize well towards larger scales and improve scale equivariance. Moreover, due to their unique design we can validate that kernel selection is consistent with input scale. Even so, none of the evaluated models maintain their performance for large differences in scale, demonstrating that a general understanding of how scale equivariance can improve generalization and robustness is still lacking.
Improving Robustness against Real-World and Worst-Case Distribution Shifts through Decision Region Quantification
May 19, 2022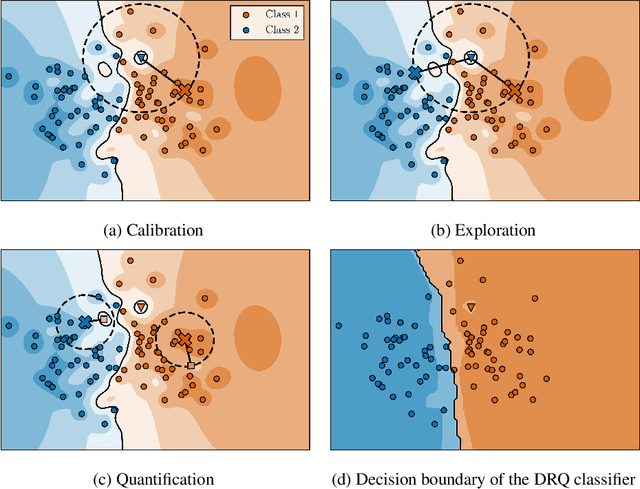
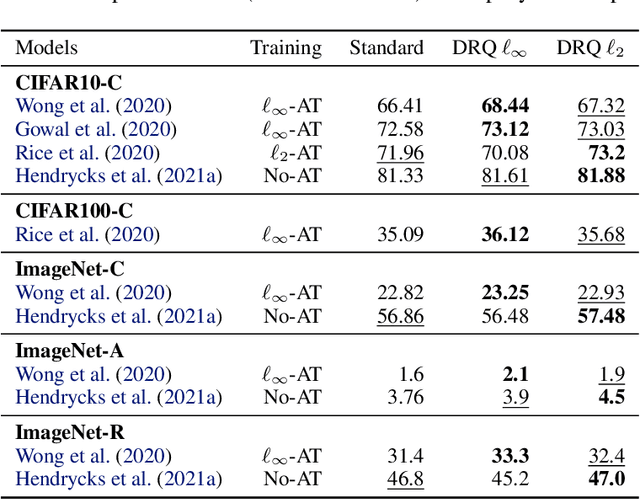

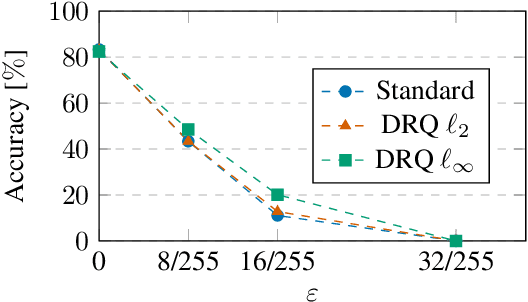
The reliability of neural networks is essential for their use in safety-critical applications. Existing approaches generally aim at improving the robustness of neural networks to either real-world distribution shifts (e.g., common corruptions and perturbations, spatial transformations, and natural adversarial examples) or worst-case distribution shifts (e.g., optimized adversarial examples). In this work, we propose the Decision Region Quantification (DRQ) algorithm to improve the robustness of any differentiable pre-trained model against both real-world and worst-case distribution shifts in the data. DRQ analyzes the robustness of local decision regions in the vicinity of a given data point to make more reliable predictions. We theoretically motivate the DRQ algorithm by showing that it effectively smooths spurious local extrema in the decision surface. Furthermore, we propose an implementation using targeted and untargeted adversarial attacks. An extensive empirical evaluation shows that DRQ increases the robustness of adversarially and non-adversarially trained models against real-world and worst-case distribution shifts on several computer vision benchmark datasets.
Explain to Not Forget: Defending Against Catastrophic Forgetting with XAI
May 11, 2022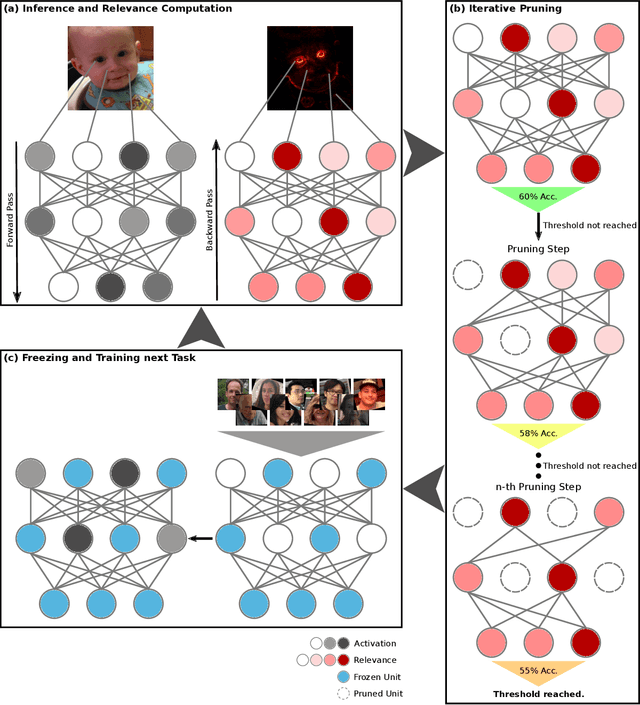
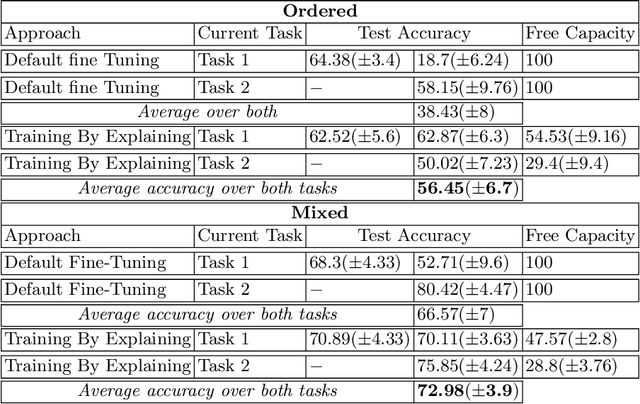
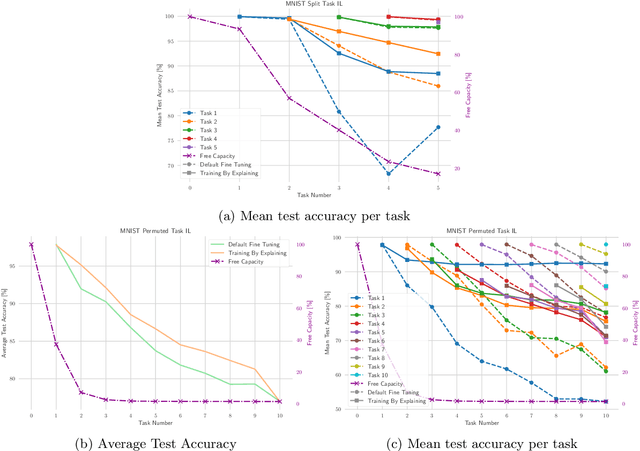
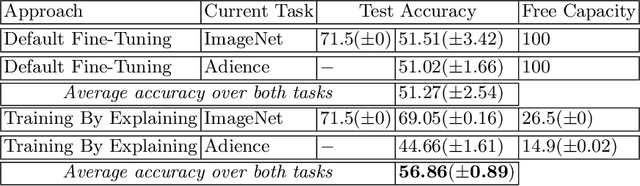
The ability to continuously process and retain new information like we do naturally as humans is a feat that is highly sought after when training neural networks. Unfortunately, the traditional optimization algorithms often require large amounts of data available during training time and updates wrt. new data are difficult after the training process has been completed. In fact, when new data or tasks arise, previous progress may be lost as neural networks are prone to catastrophic forgetting. Catastrophic forgetting describes the phenomenon when a neural network completely forgets previous knowledge when given new information. We propose a novel training algorithm called training by explaining in which we leverage Layer-wise Relevance Propagation in order to retain the information a neural network has already learned in previous tasks when training on new data. The method is evaluated on a range of benchmark datasets as well as more complex data. Our method not only successfully retains the knowledge of old tasks within the neural networks but does so more resource-efficiently than other state-of-the-art solutions.
Language Model Evaluation in Open-ended Text Generation
Aug 08, 2021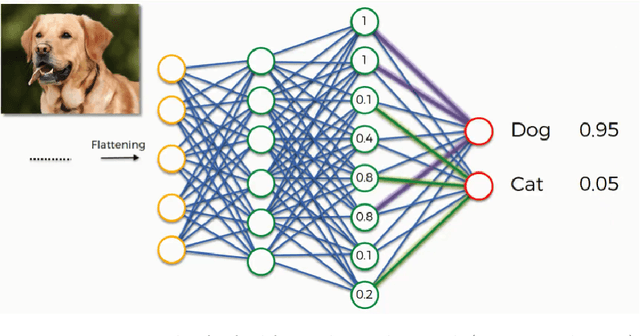

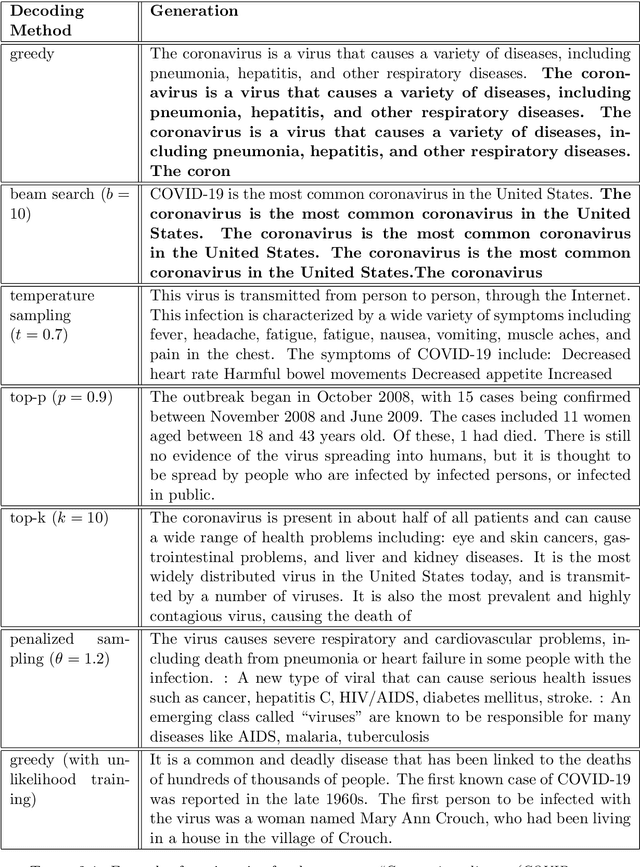
Although current state-of-the-art language models have achieved impressive results in numerous natural language processing tasks, still they could not solve the problem of producing repetitive, dull and sometimes inconsistent text in open-ended text generation. Studies often attribute this problem to the maximum likelihood training objective, and propose alternative approaches by using stochastic decoding methods or altering the training objective. However, there is still a lack of consistent evaluation metrics to directly compare the efficacy of these solutions. In this work, we study different evaluation metrics that have been proposed to evaluate quality, diversity and consistency of machine-generated text. From there, we propose a practical pipeline to evaluate language models in open-ended generation task, and research on how to improve the model's performance in all dimensions by leveraging different auxiliary training objectives.
Exploring Misclassifications of Robust Neural Networks to Enhance Adversarial Attacks
May 25, 2021

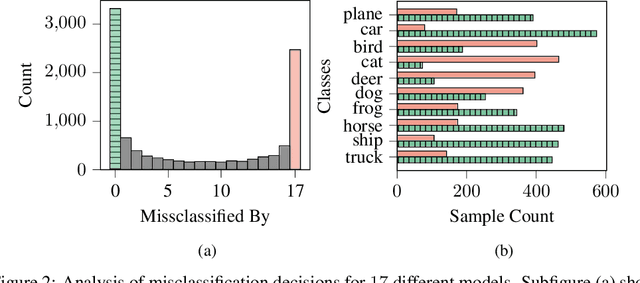
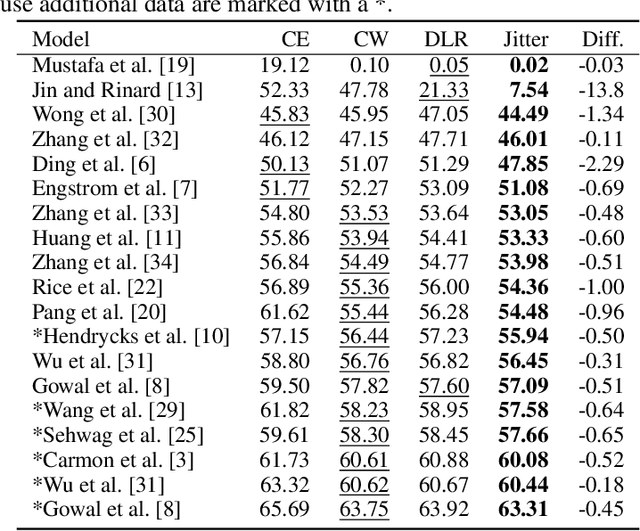
Progress in making neural networks more robust against adversarial attacks is mostly marginal, despite the great efforts of the research community. Moreover, the robustness evaluation is often imprecise, making it difficult to identify promising approaches. We analyze the classification decisions of 19 different state-of-the-art neural networks trained to be robust against adversarial attacks. Our findings suggest that current untargeted adversarial attacks induce misclassification towards only a limited amount of different classes. Additionally, we observe that both over- and under-confidence in model predictions result in an inaccurate assessment of model robustness. Based on these observations, we propose a novel loss function for adversarial attacks that consistently improves attack success rate compared to prior loss functions for 19 out of 19 analyzed models.
Identifying Untrustworthy Predictions in Neural Networks by Geometric Gradient Analysis
Feb 24, 2021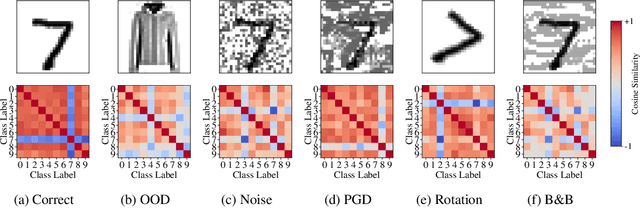
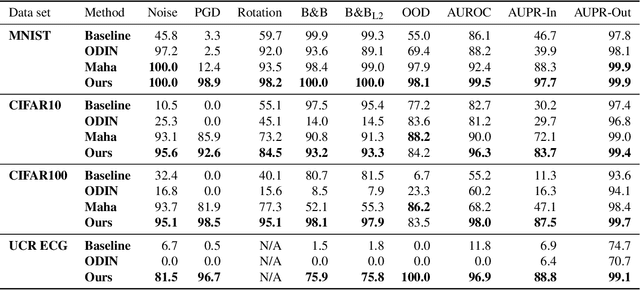
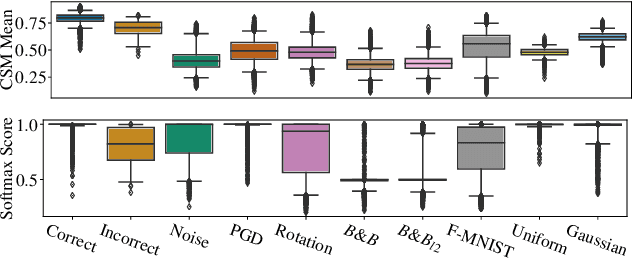
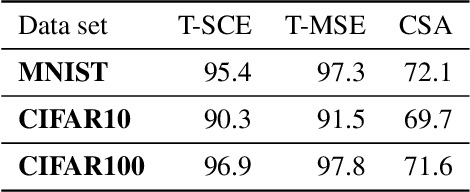
The susceptibility of deep neural networks to untrustworthy predictions, including out-of-distribution (OOD) data and adversarial examples, still prevent their widespread use in safety-critical applications. Most existing methods either require a re-training of a given model to achieve robust identification of adversarial attacks or are limited to out-of-distribution sample detection only. In this work, we propose a geometric gradient analysis (GGA) to improve the identification of untrustworthy predictions without retraining of a given model. GGA analyzes the geometry of the loss landscape of neural networks based on the saliency maps of their respective input. To motivate the proposed approach, we provide theoretical connections between gradients' geometrical properties and local minima of the loss function. Furthermore, we demonstrate that the proposed method outperforms prior approaches in detecting OOD data and adversarial attacks, including state-of-the-art and adaptive attacks.