 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model Evaluation in Open-ended Text Generation
Paper and Code

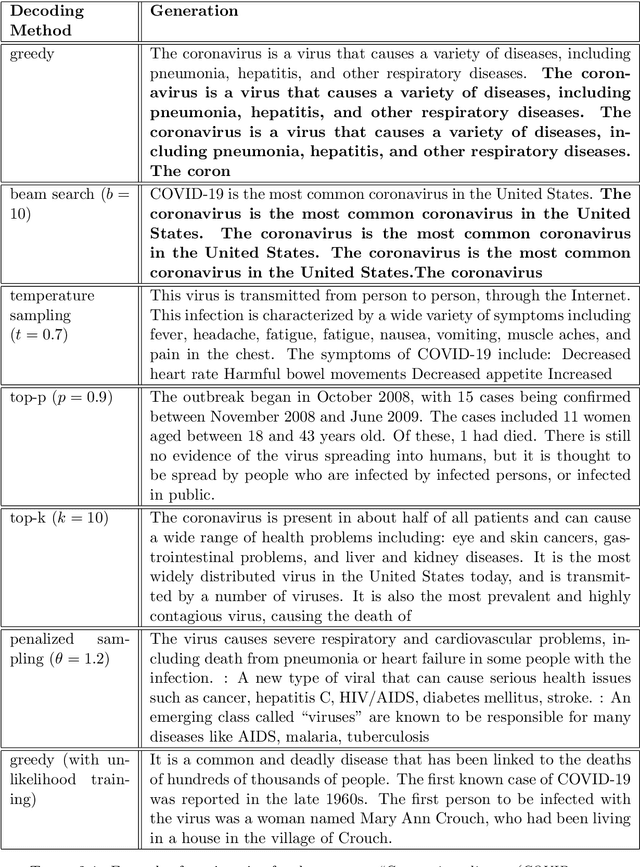
Although current state-of-the-art language models have achieved impressive results in numerous natural language processing tasks, still they could not solve the problem of producing repetitive, dull and sometimes inconsistent text in open-ended text generation. Studies often attribute this problem to the maximum likelihood training objective, and propose alternative approaches by using stochastic decoding methods or altering the training objective. However, there is still a lack of consistent evaluation metrics to directly compare the efficacy of these solutions. In this work, we study different evaluation metrics that have been proposed to evaluate quality, diversity and consistency of machine-generated text. From there, we propose a practical pipeline to evaluate language models in open-ended generation task, and research on how to improve the model's performance in all dimensions by leveraging different auxiliary training objectives.