 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxATtack: A Multimodal Attack on Voice Anonymization Systems
Jul 16, 2025Voice anonymization systems aim to protect speaker privacy by obscuring vocal traits while preserving the linguistic content relevant for downstream applications. However, because these linguistic cues remain intact, they can be exploited to identify semantic speech patterns associated with specific speakers. In this work, we present VoxATtack, a novel multimodal de-anonymization model that incorporates both acoustic and textual information to attack anonymization systems. While previous research has focused on refining speaker representations extracted from speech, we show that incorporating textual information with a standard ECAPA-TDNN improves the attacker's performance. Our proposed VoxATtack model employs a dual-branch architecture, with an ECAPA-TDNN processing anonymized speech and a pretrained BERT encoding the transcriptions. Both outputs are projected into embeddings of equal dimensionality and then fused based on confidence weights computed on a per-utterance basis. When evaluating our approach on the VoicePrivacy Attacker Challenge (VPAC) dataset, it outperforms the top-ranking attackers on five out of seven benchmarks, namely B3, B4, B5, T8-5, and T12-5. To further boost performance, we leverage anonymized speech and SpecAugment as augmentation techniques. This enhancement enables VoxATtack to achieve state-of-the-art on all VPAC benchmarks, after scoring 20.6% and 27.2% average equal error rate on T10-2 and T25-1, respectively. Our results demonstrate that incorporating textual information and selective data augmentation reveals critical vulnerabilities in current voice anonymization methods and exposes potential weaknesses in the datasets used to evaluate them.
You Are What You Say: Exploiting Linguistic Content for VoicePrivacy Attacks
Jun 11, 2025Speaker anonymization systems hide the identity of speakers while preserving other information such as linguistic content and emotions. To evaluate their privacy benefits, attacks in the form of automatic speaker verification (ASV) systems are employed. In this study, we assess the impact of intra-speaker linguistic content similarity in the attacker training and evaluation datasets, by adapting BERT, a language model, as an ASV system. On the VoicePrivacy Attacker Challenge datasets, our method achieves a mean equal error rate (EER) of 35%, with certain speakers attaining EERs as low as 2%, based solely on the textual content of their utterances. Our explainability study reveals that the system decisions are linked to semantically similar keywords within utterances, stemming from how LibriSpeech is curated. Our study suggests reworking the VoicePrivacy datasets to ensure a fair and unbiased evaluation and challenge the reliance on global EER for privacy evaluations.
Resolution-Invariant Image Classification based on Fourier Neural Operators
Apr 02, 2023In this paper we investigate the use of Fourier Neural Operators (FNOs) for image classification in comparison to standard Convolutional Neural Networks (CNNs). Neural operators are a discretization-invariant generalization of neural networks to approximate operators between infinite dimensional function spaces. FNOs - which are neural operators with a specific parametrization - have been applied successfully in the context of parametric PDEs. We derive the FNO architecture as an example for continuous and Fr\'echet-differentiable neural operators on Lebesgue spaces. We further show how CNNs can be converted into FNOs and vice versa and propose an interpolation-equivariant adaptation of the architecture.
Neural Architecture Search via Bregman Iterations
Jun 04, 2021

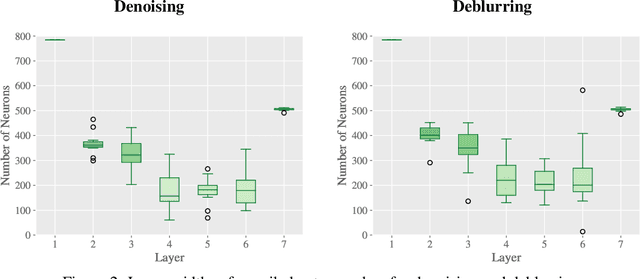
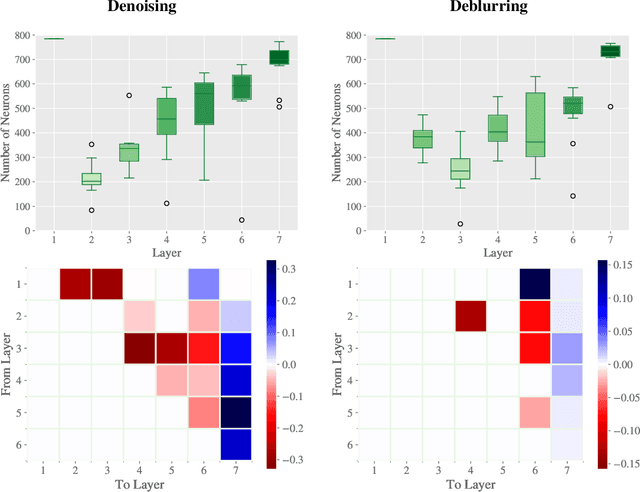
We propose a novel strategy for Neural Architecture Search (NAS) based on Bregman iterations. Starting from a sparse neural network our gradient-based one-shot algorithm gradually adds relevant parameters in an inverse scale space manner. This allows the network to choose the best architecture in the search space which makes it well-designed for a given task, e.g., by adding neurons or skip connections. We demonstrate that using our approach one can unveil, for instance, residual autoencoders for denoising, deblurring, and classification tasks. Code is available at https://github.com/TimRoith/BregmanLearning.
A Bregman Learning Framework for Sparse Neural Networks
May 17, 2021

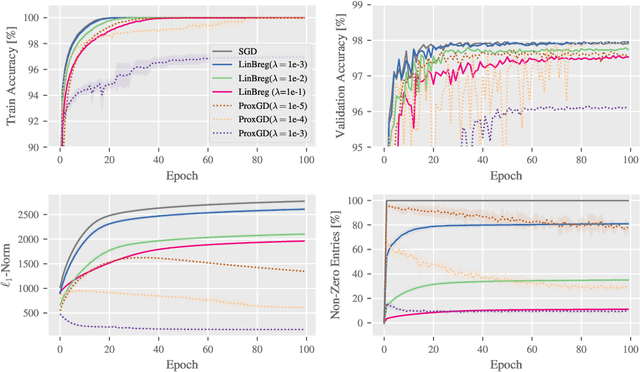
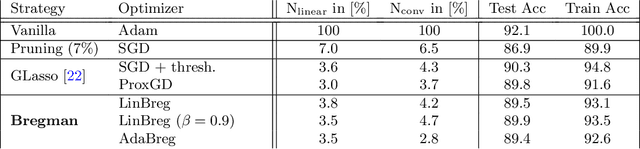
We propose a learning framework based on stochastic Bregman iterations to train sparse neural networks with an inverse scale space approach. We derive a baseline algorithm called LinBreg, an accelerated version using momentum, and AdaBreg, which is a Bregmanized generalization of the Adam algorithm. In contrast to established methods for sparse training the proposed family of algorithms constitutes a regrowth strategy for neural networks that is solely optimization-based without additional heuristics. Our Bregman learning framework starts the training with very few initial parameters, successively adding only significant ones to obtain a sparse and expressive network. The proposed approach is extremely easy and efficient, yet supported by the rich mathematical theory of inverse scale space methods. We derive a statistically profound sparse parameter initialization strategy and provide a rigorous stochastic convergence analysis of the loss decay and additional convergence proofs in the convex regime. Using only 3.4% of the parameters of ResNet-18 we achieve 90.2% test accuracy on CIFAR-10, compared to 93.6% using the dense network. Our algorithm also unveils an autoencoder architecture for a denoising task. The proposed framework also has a huge potential for integrating sparse backpropagation and resource-friendly training.
CLIP: Cheap Lipschitz Training of Neural Networks
Mar 23, 2021
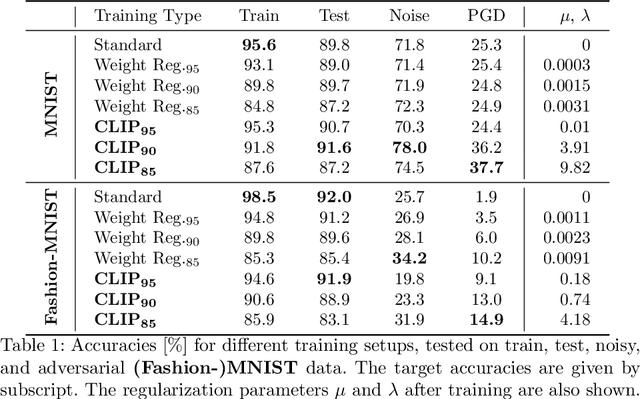
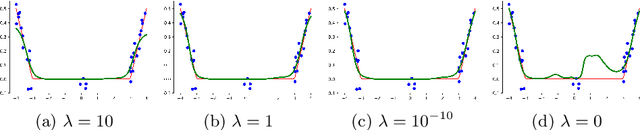
Despite the large success of deep neural networks (DNN) in recent years, most neural networks still lack mathematical guarantees in terms of stability. For instance, DNNs are vulnerable to small or even imperceptible input perturbations, so called adversarial examples, that can cause false predictions. This instability can have severe consequences in applications which influence the health and safety of humans, e.g., biomedical imaging or autonomous driving. While bounding the Lipschitz constant of a neural network improves stability, most methods rely on restricting the Lipschitz constants of each layer which gives a poor bound for the actual Lipschitz constant. In this paper we investigate a variational regularization method named CLIP for controlling the Lipschitz constant of a neural network, which can easily be integrated into the training procedure. We mathematically analyze the proposed model, in particular discussing the impact of the chosen regularization parameter on the output of the network. Finally, we numerically evaluate our method on both a nonlinear regression problem and the MNIST and Fashion-MNIST classification databases, and compare our results with a weight regularization approach.
Identifying Untrustworthy Predictions in Neural Networks by Geometric Gradient Analysis
Feb 24, 2021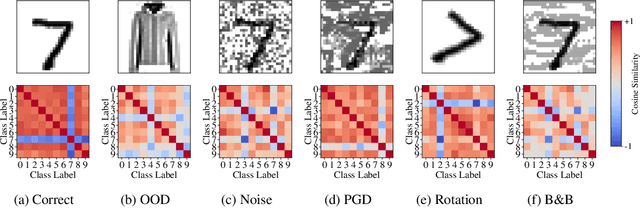
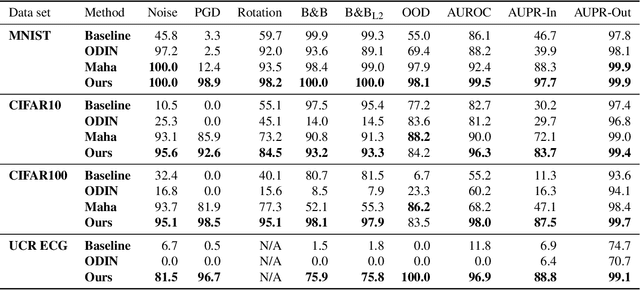
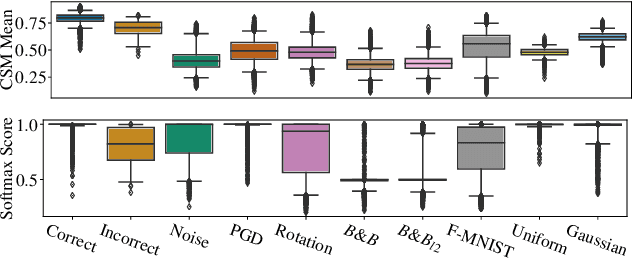
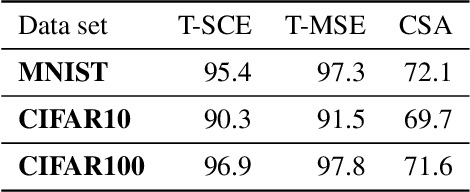
The susceptibility of deep neural networks to untrustworthy predictions, including out-of-distribution (OOD) data and adversarial examples, still prevent their widespread use in safety-critical applications. Most existing methods either require a re-training of a given model to achieve robust identification of adversarial attacks or are limited to out-of-distribution sample detection only. In this work, we propose a geometric gradient analysis (GGA) to improve the identification of untrustworthy predictions without retraining of a given model. GGA analyzes the geometry of the loss landscape of neural networks based on the saliency maps of their respective input. To motivate the proposed approach, we provide theoretical connections between gradients' geometrical properties and local minima of the loss function. Furthermore, we demonstrate that the proposed method outperforms prior approaches in detecting OOD data and adversarial attacks, including state-of-the-art and adaptive attacks.
Sampled Nonlocal Gradients for Stronger Adversarial Attacks
Nov 05, 2020

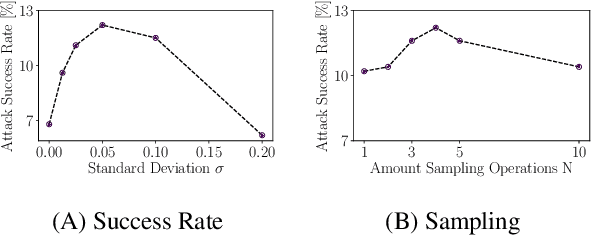

The vulnerability of deep neural networks to small and even imperceptible perturbations has become a central topic in deep learning research. The evaluation of new defense mechanisms for these so-called adversarial attacks has proven to be challenging. Although several sophisticated defense mechanisms were introduced, most of them were later shown to be ineffective. However, a reliable evaluation of model robustness is mandatory for deployment in safety-critical real-world scenarios. We propose a simple yet effective modification to the gradient calculation of state-of-the-art first-order adversarial attacks, which increases their success rate and thus leads to more accurate robustness estimates. Normally, the gradient update of an attack is directly calculated for the given data point. In general, this approach is sensitive to noise and small local optima of the loss function. Inspired by gradient sampling techniques from non-convex optimization, we propose to calculate the gradient direction of the adversarial attack as the weighted average over multiple points in the local vicinity. We empirically show that by incorporating this additional gradient information, we are able to give a more accurate estimation of the global descent direction on noisy and non-convex loss surfaces. Additionally, we show that the proposed method achieves higher success rates than a variety of state-of-the-art attacks on the benchmark datasets MNIST, Fashion-MNIST, and CIFAR10.
Computing Nonlinear Eigenfunctions via Gradient Flow Extinction
Feb 27, 2019



In this work we investigate the computation of nonlinear eigenfunctions via the extinction profiles of gradient flows. We analyze a scheme that recursively subtracts such eigenfunctions from given data and show that this procedure yields a decomposition of the data into eigenfunctions in some cases as the 1-dimensional total variation, for instance. We discuss results of numerical experiments in which we use extinction profiles and the gradient flow for the task of spectral graph clustering as used, e.g., in machine learning applications.