 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Are What You Say: Exploiting Linguistic Content for VoicePrivacy Attacks
Jun 11, 2025Speaker anonymization systems hide the identity of speakers while preserving other information such as linguistic content and emotions. To evaluate their privacy benefits, attacks in the form of automatic speaker verification (ASV) systems are employed. In this study, we assess the impact of intra-speaker linguistic content similarity in the attacker training and evaluation datasets, by adapting BERT, a language model, as an ASV system. On the VoicePrivacy Attacker Challenge datasets, our method achieves a mean equal error rate (EER) of 35%, with certain speakers attaining EERs as low as 2%, based solely on the textual content of their utterances. Our explainability study reveals that the system decisions are linked to semantically similar keywords within utterances, stemming from how LibriSpeech is curated. Our study suggests reworking the VoicePrivacy datasets to ensure a fair and unbiased evaluation and challenge the reliance on global EER for privacy evaluations.
The Second DISPLACE Challenge : DIarization of SPeaker and LAnguage in Conversational Environments
Jun 13, 2024



The DIarization of SPeaker and LAnguage in Conversational Environments (DISPLACE) 2024 challenge is the second in the series of DISPLACE challenges, which involves tasks of speaker diarization (SD) and language diarization (LD) on a challenging multilingual conversational speech dataset. In the DISPLACE 2024 challenge, we also introduced the task of automatic speech recognition (ASR) on this dataset. The dataset containing 158 hours of speech, consisting of both supervised and unsupervised mono-channel far-field recordings, was released for LD and SD tracks. Further, 12 hours of close-field mono-channel recordings were provided for the ASR track conducted on 5 Indian languages. The details of the dataset, baseline systems and the leader board results are highlighted in this paper. We have also compared our baseline models and the team's performances on evaluation data of DISPLACE-2023 to emphasize the advancements made in this second version of the challenge.
Overlap-aware End-to-End Supervised Hierarchical Graph Clustering for Speaker Diarization
Jan 23, 2024



Speaker diarization, the task of segmenting an audio recording based on speaker identity, constitutes an important speech pre-processing step for several downstream applications. The conventional approach to diarization involves multiple steps of embedding extraction and clustering, which are often optimized in an isolated fashion. While end-to-end diarization systems attempt to learn a single model for the task, they are often cumbersome to train and require large supervised datasets. In this paper, we propose an end-to-end supervised hierarchical clustering algorithm based on graph neural networks (GNN), called End-to-end Supervised HierARchical Clustering (E-SHARC). The E-SHARC approach uses front-end mel-filterbank features as input and jointly learns an embedding extractor and the GNN clustering module, performing representation learning, metric learning, and clustering with end-to-end optimization. Further, with additional inputs from an external overlap detector, the E-SHARC approach is capable of predicting the speakers in the overlapping speech regions. The experimental evaluation on several benchmark datasets like AMI, VoxConverse and DISPLACE, illustrates that the proposed E-SHARC framework improves significantly over the state-of-art diarization systems.
Summary of the DISPLACE Challenge 2023 -- DIarization of SPeaker and LAnguage in Conversational Environments
Nov 23, 2023In multi-lingual societies, where multiple languages are spoken in a small geographic vicinity, informal conversations often involve mix of languages. Existing speech technologies may be inefficient in extracting information from such conversations, where the speech data is rich in diversity with multiple languages and speakers. The DISPLACE (DIarization of SPeaker and LAnguage in Conversational Environments) challenge constitutes an open-call for evaluating and bench-marking the speaker and language diarization technologies on this challenging condition. The challenge entailed two tracks: Track-1 focused on speaker diarization (SD) in multilingual situations while, Track-2 addressed the language diarization (LD) in a multi-speaker scenario. Both the tracks were evaluated using the same underlying audio data. To facilitate this evaluation, a real-world dataset featuring multilingual, multi-speaker conversational far-field speech was recorded and distributed. Furthermore, a baseline system was made available for both SD and LD task which mimicked the state-of-art in these tasks. The challenge garnered a total of $42$ world-wide registrations and received a total of $19$ combined submissions for Track-1 and Track-2. This paper describes the challenge, details of the datasets, tasks, and the baseline system. Additionally, the paper provides a concise overview of the submitted systems in both tracks, with an emphasis given to the top performing systems. The paper also presents insights and future perspectives for SD and LD tasks, focusing on the key challenges that the systems need to overcome before wide-spread commercial deployment on such conversations.
DISPLACE Challenge: DIarization of SPeaker and LAnguage in Conversational Environments
Mar 01, 2023The DISPLACE challenge entails a first-of-kind task to perform speaker and language diarization on the same data, as the data contains multi-speaker social conversations in multilingual code-mixed speech. The challenge attempts to benchmark and improve Speaker Diarization (SD) in multilingual settings and Language Diarization (LD) in multi-speaker settings. For this challenge, a natural multilingual, multi-speaker conversational dataset is distributed for development and evaluation purposes. Automatic systems are evaluated on single-channel far-field recordings containing natural code-mix, code-switch, overlap, reverberation, short turns, short pauses, and multiple dialects of the same language. A total of 60 teams from industry and academia have registered for this challenge.
Audio Retrieval for Multimodal Design Documents: A New Dataset and Algorithms
Feb 28, 2023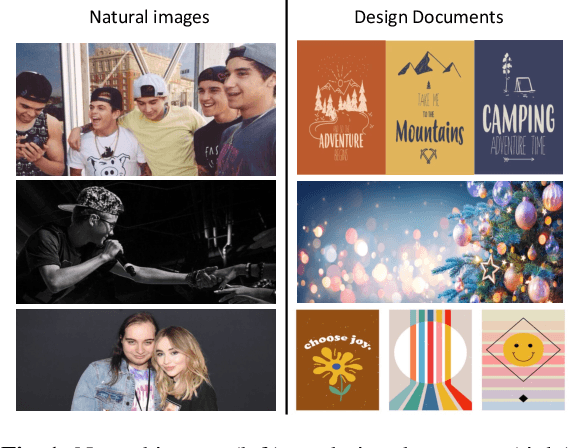
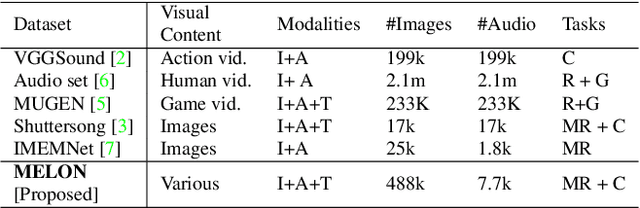

We consider and propose a new problem of retrieving audio files relevant to multimodal design document inputs comprising both textual elements and visual imagery, e.g., birthday/greeting cards. In addition to enhancing user experience, integrating audio that matches the theme/style of these inputs also helps improve the accessibility of these documents (e.g., visually impaired people can listen to the audio instead). While recent work in audio retrieval exists, these methods and datasets are targeted explicitly towards natural images. However, our problem considers multimodal design documents (created by users using creative software) substantially different from a naturally clicked photograph. To this end, our first contribution is collecting and curating a new large-scale dataset called Melodic-Design (or MELON), comprising design documents representing various styles, themes, templates, illustrations, etc., paired with music audio. Given our paired image-text-audio dataset, our next contribution is a novel multimodal cross-attention audio retrieval (MMCAR) algorithm that enables training neural networks to learn a common shared feature space across image, text, and audio dimensions. We use these learned features to demonstrate that our method outperforms existing state-of-the-art methods and produce a new reference benchmark for the research community on our new dataset.
Supervised Hierarchical Clustering using Graph Neural Networks for Speaker Diarization
Feb 24, 2023Conventional methods for speaker diarization involve windowing an audio file into short segments to extract speaker embeddings, followed by an unsupervised clustering of the embeddings. This multi-step approach generates speaker assignments for each segment. In this paper, we propose a novel Supervised HierArchical gRaph Clustering algorithm (SHARC) for speaker diarization where we introduce a hierarchical structure using Graph Neural Network (GNN) to perform supervised clustering. The supervision allows the model to update the representations and directly improve the clustering performance, thus enabling a single-step approach for diarization. In the proposed work, the input segment embeddings are treated as nodes of a graph with the edge weights corresponding to the similarity scores between the nodes. We also propose an approach to jointly update the embedding extractor and the GNN model to perform end-to-end speaker diarization (E2E-SHARC). During inference, the hierarchical clustering is performed using node densities and edge existence probabilities to merge the segments until convergence. In the diarization experiments, we illustrate that the proposed E2E-SHARC approach achieves 53% and 44% relative improvements over the baseline systems on benchmark datasets like AMI and Voxconverse, respectively.
Self-Supervised Metric Learning With Graph Clustering For Speaker Diarization
Sep 14, 2021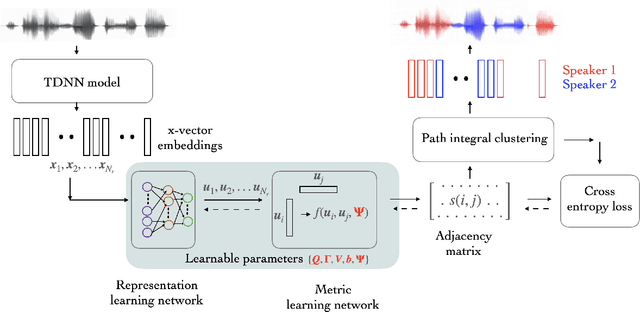

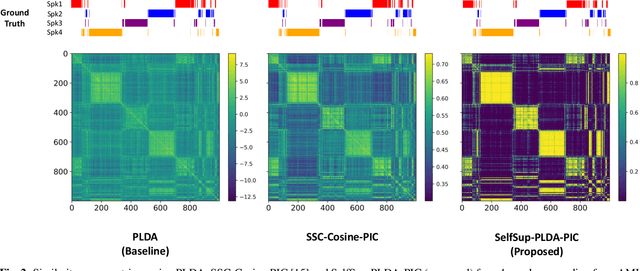

In this paper, we propose a novel algorithm for speaker diarization using metric learning for graph based clustering. The graph clustering algorithms use an adjacency matrix consisting of similarity scores. These scores are computed between speaker embeddings extracted from pairs of audio segments within the given recording. In this paper, we propose an approach that jointly learns the speaker embeddings and the similarity metric using principles of self-supervised learning. The metric learning network implements a neural model of the probabilistic linear discriminant analysis (PLDA). The self-supervision is derived from the pseudo labels obtained from a previous iteration of clustering. The entire model of representation learning and metric learning is trained with a binary cross entropy loss. By combining the self-supervision based metric learning along with the graph-based clustering algorithm, we achieve significant relative improvements of 60% and 7% over the x-vector PLDA agglomerative hierarchical clustering (AHC) approach on AMI and the DIHARD datasets respectively in terms of diarization error rates (DER).
Self-supervised Representation Learning With Path Integral Clustering For Speaker Diarization
Apr 19, 2021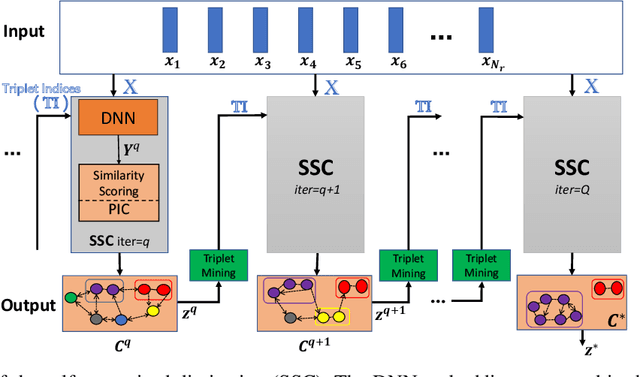
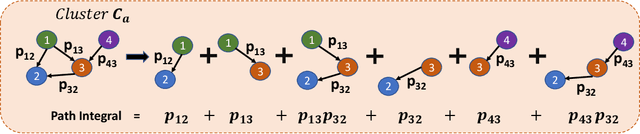
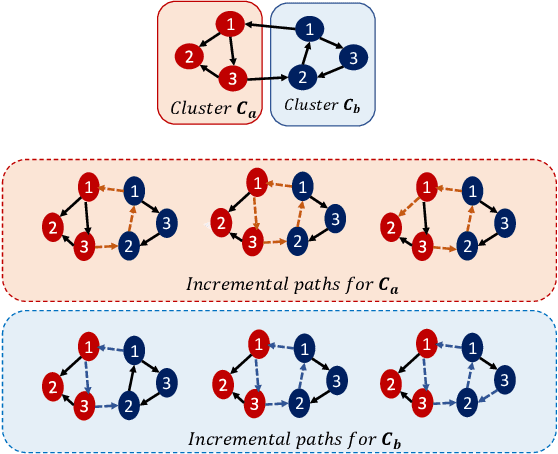
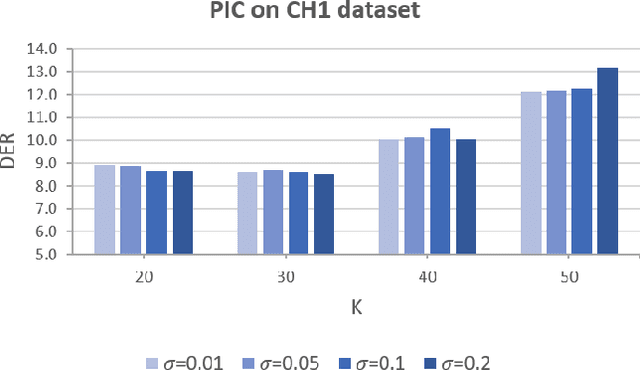
Automatic speaker diarization techniques typically involve a two-stage processing approach where audio segments of fixed duration are converted to vector representations in the first stage. This is followed by an unsupervised clustering of the representations in the second stage. In most of the prior approaches, these two stages are performed in an isolated manner with independent optimization steps. In this paper, we propose a representation learning and clustering algorithm that can be iteratively performed for improved speaker diarization. The representation learning is based on principles of self-supervised learning while the clustering algorithm is a graph structural method based on path integral clustering (PIC). The representation learning step uses the cluster targets from PIC and the clustering step is performed on embeddings learned from the self-supervised deep model. This iterative approach is referred to as self-supervised clustering (SSC). The diarization experiments are performed on CALLHOME and AMI meeting datasets. In these experiments, we show that the SSC algorithm improves significantly over the baseline system (relative improvements of 13% and 59% on CALLHOME and AMI datasets respectively in terms of diarization error rate (DER)). In addition, the DER results reported in this work improve over several other recent approaches for speaker diarization.
LEAP Submission for the Third DIHARD Diarization Challenge
Apr 06, 2021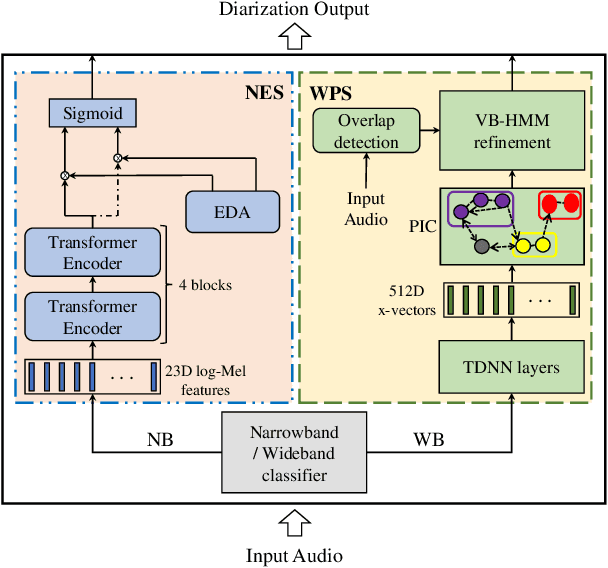

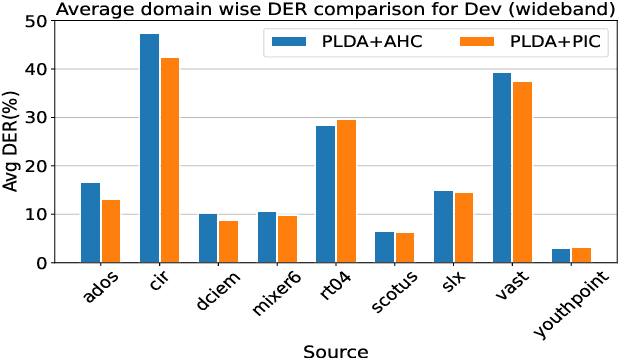

The LEAP submission for DIHARD-III challenge is described in this paper. The proposed system is composed of a speech bandwidth classifier, and diarization systems fine-tuned for narrowband and wideband speech separately. We use an end-to-end speaker diarization system for the narrowband conversational telephone speech recordings. For the wideband multi-speaker recordings, we use a neural embedding based clustering approach, similar to the baseline system. The embeddings are extracted from a time-delay neural network (called x-vectors) followed by the graph based path integral clustering (PIC) approach. The LEAP system showed 24% and 18% relative improvements for Track-1 and Track-2 respectively over the baseline system provided by the organizers. This paper describes the challenge submission, the post-evaluation analysis and improvements observed on the DIHARD-III dataset.