 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISPLACE Challenge: DIarization of SPeaker and LAnguage in Conversational Environments
Mar 01, 2023The DISPLACE challenge entails a first-of-kind task to perform speaker and language diarization on the same data, as the data contains multi-speaker social conversations in multilingual code-mixed speech. The challenge attempts to benchmark and improve Speaker Diarization (SD) in multilingual settings and Language Diarization (LD) in multi-speaker settings. For this challenge, a natural multilingual, multi-speaker conversational dataset is distributed for development and evaluation purposes. Automatic systems are evaluated on single-channel far-field recordings containing natural code-mix, code-switch, overlap, reverberation, short turns, short pauses, and multiple dialects of the same language. A total of 60 teams from industry and academia have registered for this challenge.
Automatic Recognition of Facial Displays of Unfelt Emotions
Jan 09, 2018
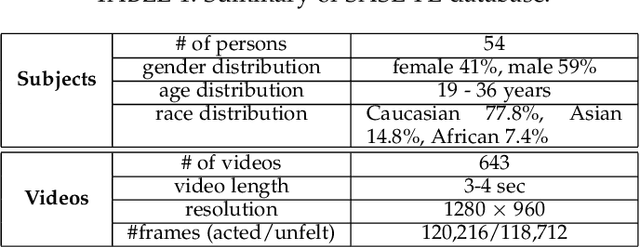

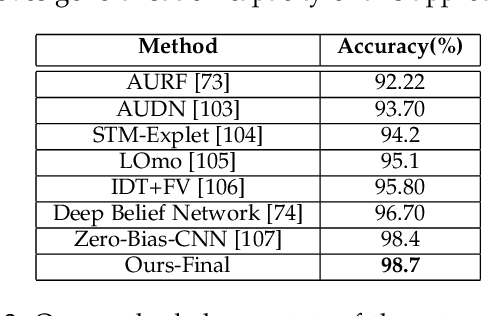
Humans modify their facial expressions in order to communicate their internal states and sometimes to mislead observers regarding their true emotional states. Evidence in experimental psychology shows that discriminative facial responses are short and subtle. This suggests that such behavior would be easier to distinguish when captured in high resolution at an increased frame rate. We are proposing SASE-FE, the first dataset of facial expressions that are either congruent or incongruent with underlying emotion states. We show that overall the problem of recognizing whether facial movements are expressions of authentic emotions or not can be successfully addressed by learning spatio-temporal representations of the data. For this purpose, we propose a method that aggregates features along fiducial trajectories in a deeply learnt space. Performance of the proposed model shows that on average it is easier to distinguish among genuine facial expressions of emotion than among unfelt facial expressions of emotion and that certain emotion pairs such as contempt and disgust are more difficult to distinguish than the rest. Furthermore, the proposed methodology improves state of the art results on CK+ and OULU-CASIA datasets for video emotion recognition, and achieves competitive results when classifying facial action units on BP4D datase.
Continuous Action Recognition Based on Sequence Alignment
Jun 02, 2014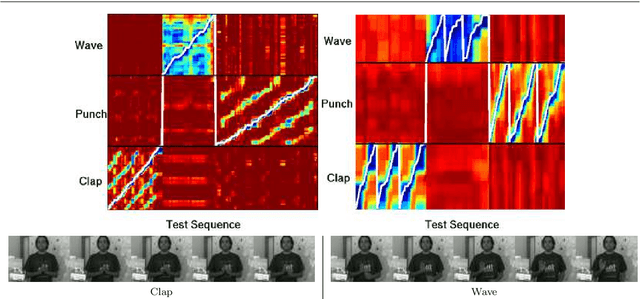
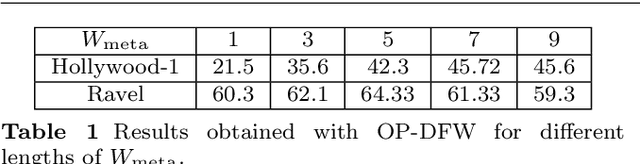

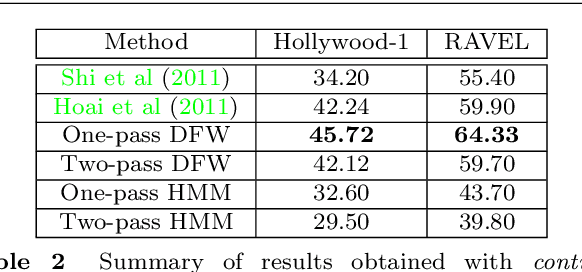
Continuous action recognition is more challenging than isolated recognition because classification and segmentation must be simultaneously carried out. We build on the well known dynamic time warping (DTW) framework and devise a novel visual alignment technique, namely dynamic frame warping (DFW), which performs isolated recognition based on per-frame representation of videos, and on aligning a test sequence with a model sequence. Moreover, we propose two extensions which enable to perform recognition concomitant with segmentation, namely one-pass DFW and two-pass DFW. These two methods have their roots in the domain of continuous recognition of speech and, to the best of our knowledge, their extension to continuous visual action recognition has been overlooked. We test and illustrate the proposed techniques with a recently released dataset (RAVEL) and with two public-domain datasets widely used in action recognition (Hollywood-1 and Hollywood-2). We also compare the performances of the proposed isolated and continuous recognition algorithms with several recently published methods.