 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex-Valued Unitary Representations as Classification Heads for Improved Uncertainty Quantification in Deep Neural Networks
Feb 17, 2026Modern deep neural networks achieve high predictive accuracy but remain poorly calibrated: their confidence scores do not reliably reflect the true probability of correctness. We propose a quantum-inspired classification head architecture that projects backbone features into a complex-valued Hilbert space and evolves them under a learned unitary transformation parameterised via the Cayley map. Through a controlled hybrid experimental design - training a single shared backbone and comparing lightweight interchangeable heads - we isolate the effect of complex-valued unitary representations on calibration. Our ablation study on CIFAR-10 reveals that the unitary magnitude head (complex features evolved under a Cayley unitary, read out via magnitude and softmax) achieves an Expected Calibration Error (ECE) of 0.0146, representing a 2.4x improvement over a standard softmax head (0.0355) and a 3.5x improvement over temperature scaling (0.0510). Surprisingly, replacing the softmax readout with a Born rule measurement layer - the quantum-mechanically motivated approach - degrades calibration to an ECE of 0.0819. On the CIFAR-10H human-uncertainty benchmark, the wave function head achieves the lowest KL-divergence (0.336) to human soft labels among all compared methods, indicating that complex-valued representations better capture the structure of human perceptual ambiguity. We provide theoretical analysis connecting norm-preserving unitary dynamics to calibration through feature-space geometry, report negative results on out-of-distribution detection and sentiment analysis to delineate the method's scope, and discuss practical implications for safety-critical applications. Code is publicly available.
Responsible AI: The Good, The Bad, The AI
Jan 28, 2026The rapid proliferation of artificial intelligence across organizational contexts has generated profound strategic opportunities while introducing significant ethical and operational risks. Despite growing scholarly attention to responsible AI, extant literature remains fragmented and is often adopting either an optimistic stance emphasizing value creation or an excessively cautious perspective fixated on potential harms. This paper addresses this gap by presenting a comprehensive examination of AI's dual nature through the lens of strategic information systems. Drawing upon a systematic synthesis of the responsible AI literature and grounded in paradox theory, we develop the Paradox-based Responsible AI Governance (PRAIG) framework that articulates: (1) the strategic benefits of AI adoption, (2) the inherent risks and unintended consequences, and (3) governance mechanisms that enable organizations to navigate these tensions. Our framework advances theoretical understanding by conceptualizing responsible AI governance as the dynamic management of paradoxical tensions between value creation and risk mitigation. We provide formal propositions demonstrating that trade-off approaches amplify rather than resolve these tensions, and we develop a taxonomy of paradox management strategies with specified contingency conditions. For practitioners, we offer actionable guidance for developing governance structures that neither stifle innovation nor expose organizations to unacceptable risks. The paper concludes with a research agenda for advancing responsible AI governance scholarship.
A Lightweight Modular Framework for Constructing Autonomous Agents Driven by Large Language Models: Design, Implementation, and Applications in AgentForge
Jan 19, 2026The emergence of LLMs has catalyzed a paradigm shift in autonomous agent development, enabling systems capable of reasoning, planning, and executing complex multi-step tasks. However, existing agent frameworks often suffer from architectural rigidity, vendor lock-in, and prohibitive complexity that impedes rapid prototyping and deployment. This paper presents AgentForge, a lightweight, open-source Python framework designed to democratize the construction of LLM-driven autonomous agents through a principled modular architecture. AgentForge introduces three key innovations: (1) a composable skill abstraction that enables fine-grained task decomposition with formally defined input-output contracts, (2) a unified LLM backend interface supporting seamless switching between cloud-based APIs and local inference engines, and (3) a declarative YAML-based configuration system that separates agent logic from implementation details. We formalize the skill composition mechanism as a directed acyclic graph (DAG) and prove its expressiveness for representing arbitrary sequential and parallel task workflows. Comprehensive experimental evaluation across four benchmark scenarios demonstrates that AgentForge achieves competitive task completion rates while reducing development time by 62% compared to LangChain and 78% compared to direct API integration. Latency measurements confirm sub-100ms orchestration overhead, rendering the framework suitable for real-time applications. The modular design facilitates extension: we demonstrate the integration of six built-in skills and provide comprehensive documentation for custom skill development. AgentForge addresses a critical gap in the LLM agent ecosystem by providing researchers and practitioners with a production-ready foundation for constructing, evaluating, and deploying autonomous agents without sacrificing flexibility or performance.
Dynamic Nested Hierarchies: Pioneering Self-Evolution in Machine Learning Architectures for Lifelong Intelligence
Nov 18, 2025Contemporary machine learning models, including large language models, exhibit remarkable capabilities in static tasks yet falter in non-stationary environments due to rigid architectures that hinder continual adaptation and lifelong learning. Building upon the nested learning paradigm, which decomposes models into multi-level optimization problems with fixed update frequencies, this work proposes dynamic nested hierarchies as the next evolutionary step in advancing artificial intelligence and machine learning. Dynamic nested hierarchies empower models to autonomously adjust the number of optimization levels, their nesting structures, and update frequencies during training or inference, inspired by neuroplasticity to enable self-evolution without predefined constraints. This innovation addresses the anterograde amnesia in existing models, facilitating true lifelong learning by dynamically compressing context flows and adapting to distribution shifts. Through rigorous mathematical formulations, theoretical proofs of convergence, expressivity bounds, and sublinear regret in varying regimes, alongside empirical demonstrations of superior performance in language modeling, continual learning, and long-context reasoning, dynamic nested hierarchies establish a foundational advancement toward adaptive, general-purpose intelligence.
A Mathematical Framework for AI Singularity: Conditions, Bounds, and Control of Recursive Improvement
Nov 08, 2025AI systems improve by drawing on more compute, data, energy, and better training methods. This paper asks a precise, testable version of the "runaway growth" question: under what measurable conditions could capability escalate without bound in finite time, and under what conditions can that be ruled out? We develop an analytic framework for recursive self-improvement that links capability growth to resource build-out and deployment policies. Physical and information-theoretic limits from power, bandwidth, and memory define a service envelope that caps instantaneous improvement. An endogenous growth model couples capital to compute, data, and energy and defines a critical boundary separating superlinear from subcritical regimes. We derive decision rules that map observable series (facility power, IO bandwidth, training throughput, benchmark losses, and spending) into yes/no certificates for runaway versus nonsingular behavior. The framework yields falsifiable tests based on how fast improvement accelerates relative to its current level, and it provides safety controls that are directly implementable in practice, such as power caps, throughput throttling, and evaluation gates. Analytical case studies cover capped-power, saturating-data, and investment-amplified settings, illustrating when the envelope binds and when it does not. The approach is simulation-free and grounded in measurements engineers already collect. Limitations include dependence on the chosen capability metric and on regularity diagnostics; future work will address stochastic dynamics, multi-agent competition, and abrupt architectural shifts. Overall, the results replace speculation with testable conditions and deployable controls for certifying or precluding an AI singularity.
Responsible AI: Gender bias assessment in emotion recognition
Mar 21, 2021
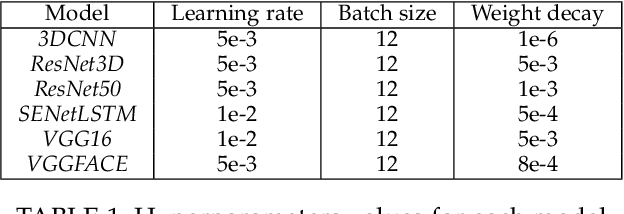

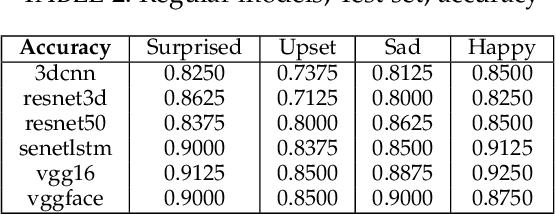
Rapid development of artificial intelligence (AI) systems amplify many concerns in society. These AI algorithms inherit different biases from humans due to mysterious operational flow and because of that it is becoming adverse in usage. As a result, researchers have started to address the issue by investigating deeper in the direction towards Responsible and Explainable AI. Among variety of applications of AI, facial expression recognition might not be the most important one, yet is considered as a valuable part of human-AI interaction. Evolution of facial expression recognition from the feature based methods to deep learning drastically improve quality of such algorithms. This research work aims to study a gender bias in deep learning methods for facial expression recognition by investigating six distinct neural networks, training them, and further analysed on the presence of bias, according to the three definition of fairness. The main outcomes show which models are gender biased, which are not and how gender of subject affects its emotion recognition. More biased neural networks show bigger accuracy gap in emotion recognition between male and female test sets. Furthermore, this trend keeps for true positive and false positive rates. In addition, due to the nature of the research, we can observe which types of emotions are better classified for men and which for women. Since the topic of biases in facial expression recognition is not well studied, a spectrum of continuation of this research is truly extensive, and may comprise detail analysis of state-of-the-art methods, as well as targeting other biases.
Ensemble approach for detection of depression using EEG features
Mar 07, 2021
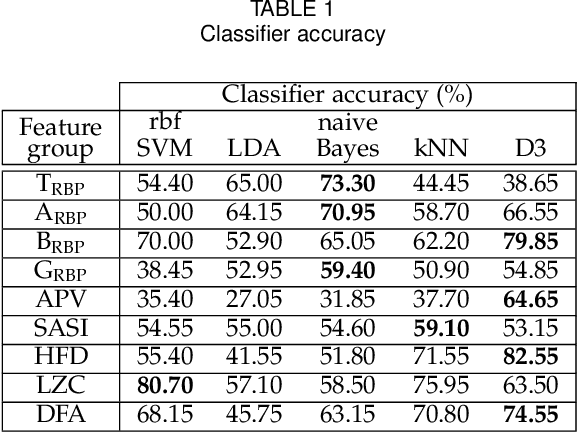
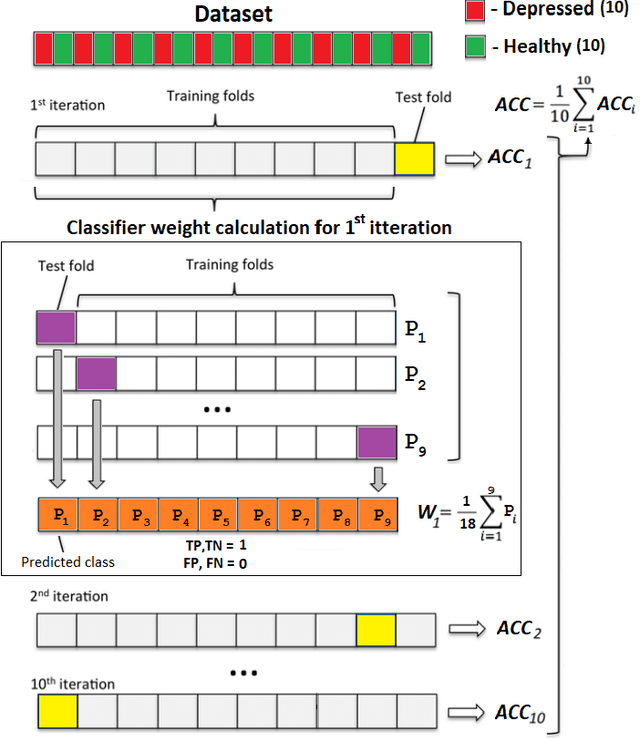
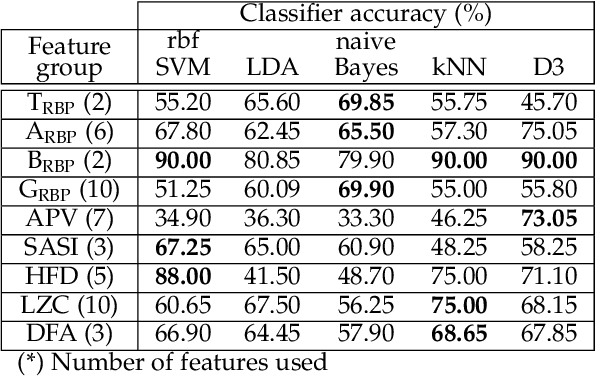
Depression is a public health issue which severely affects one's well being and cause negative social and economic effect for society. To rise awareness of these problems, this publication aims to determine if long lasting effects of depression can be determined from electoencephalographic (EEG) signals. The article contains accuracy comparison for SVM, LDA, NB, kNN and D3 binary classifiers which were trained using linear (relative band powers, APV, SASI) and non-linear (HFD, LZC, DFA) EEG features. The age and gender matched dataset consisted of 10 healthy subjects and 10 subjects with depression diagnosis at some point in their lifetime. Several of the proposed feature selection and classifier combinations reached accuracy of 90% where all models where evaluated using 10-fold cross validation and averaged over 100 repetitions with random sample permutations.
ChaLearn Looking at People: IsoGD and ConGD Large-scale RGB-D Gesture Recognition
Jul 29, 2019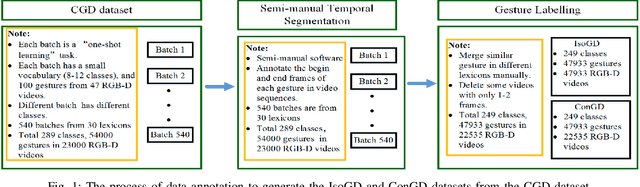


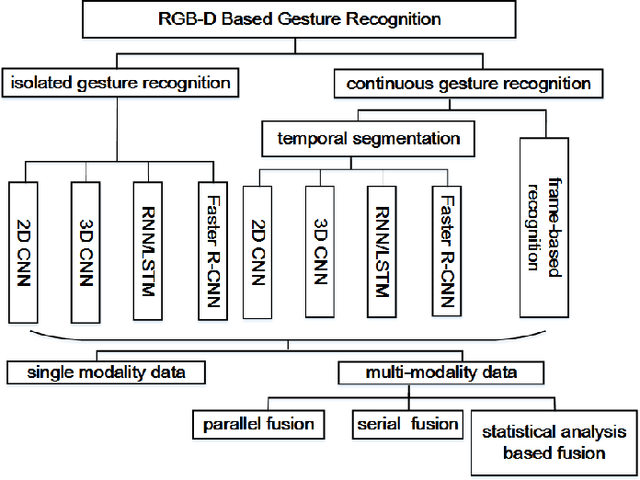
The ChaLearn large-scale gesture recognition challenge has been run twice in two workshops in conjunction with the International Conference on Pattern Recognition (ICPR) 2016 and International Conference on Computer Vision (ICCV) 2017, attracting more than $200$ teams round the world. This challenge has two tracks, focusing on isolated and continuous gesture recognition, respectively. This paper describes the creation of both benchmark datasets and analyzes the advances in large-scale gesture recognition based on these two datasets. We discuss the challenges of collecting large-scale ground-truth annotations of gesture recognition, and provide a detailed analysis of the current state-of-the-art methods for large-scale isolated and continuous gesture recognition based on RGB-D video sequences. In addition to recognition rate and mean jaccard index (MJI) as evaluation metrics used in our previous challenges, we also introduce the corrected segmentation rate (CSR) metric to evaluate the performance of temporal segmentation for continuous gesture recognition. Furthermore, we propose a bidirectional long short-term memory (Bi-LSTM) baseline method, determining the video division points based on the skeleton points extracted by convolutional pose machine (CPM). Experiments demonstrate that the proposed Bi-LSTM outperforms the state-of-the-art methods with an absolute improvement of $8.1\%$ (from $0.8917$ to $0.9639$) of CSR.
On the effect of age perception biases for real age regression
Feb 20, 2019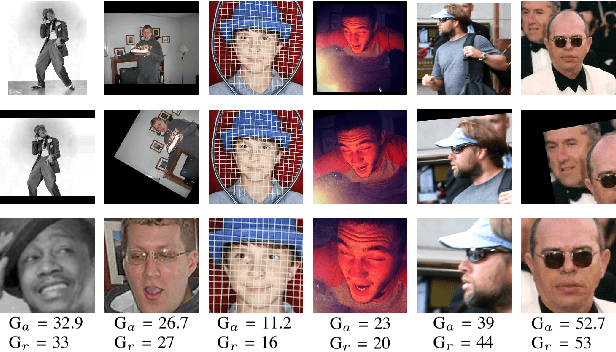
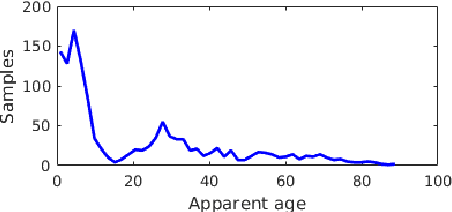
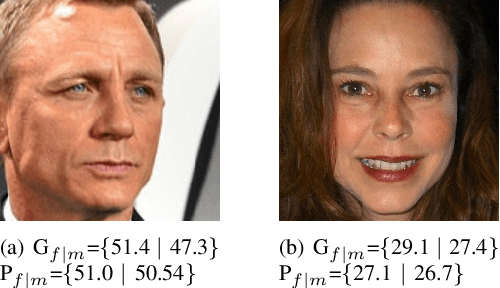

Automatic age estimation from facial images represents an important task in computer vision. This paper analyses the effect of gender, age, ethnic, makeup and expression attributes of faces as sources of bias to improve deep apparent age prediction. Following recent works where it is shown that apparent age labels benefit real age estimation, rather than direct real to real age regression, our main contribution is the integration, in an end-to-end architecture, of face attributes for apparent age prediction with an additional loss for real age regression. Experimental results on the APPA-REAL dataset indicate the proposed network successfully take advantage of the adopted attributes to improve both apparent and real age estimation. Our model outperformed a state-of-the-art architecture proposed to separately address apparent and real age regression. Finally, we present preliminary results and discussion of a proof of concept application using the proposed model to regress the apparent age of an individual based on the gender of an external observer.
A Study of Language and Classifier-independent Feature Analysis for Vocal Emotion Recognition
Nov 14, 2018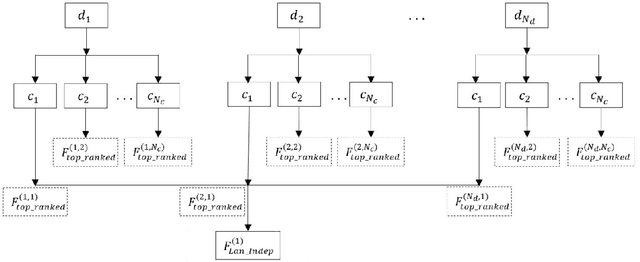

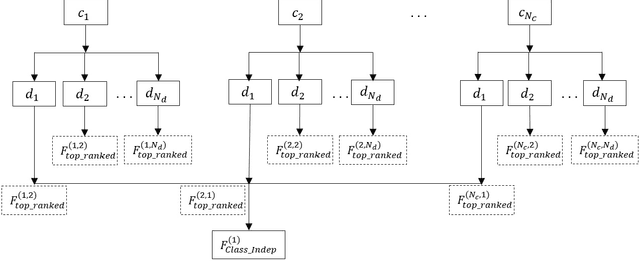

Every speech signal carries implicit information about the emotions, which can be extracted by speech processing methods. In this paper, we propose an algorithm for extracting features that are independent from the spoken language and the classification method to have comparatively good recognition performance on different languages independent from the employed classification methods. The proposed algorithm is composed of three stages. In the first stage, we propose a feature ranking method analyzing the state-of-the-art voice quality features. In the second stage, we propose a method for finding the subset of the common features for each language and classifier. In the third stage, we compare our approach with the recognition rate of the state-of-the-art filter methods. We use three databases with different languages, namely, Polish, Serbian and English. Also three different classifiers, namely, nearest neighbour, support vector machine and gradient descent neural network, are employed. It is shown that our method for selecting the most significant language-independent and method-independent features in many cases outperforms state-of-the-art filter methods.