 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Competitions and Benchmarks: Dataset Development
Apr 15, 2024



Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
Winning solutions and post-challenge analyses of the ChaLearn AutoDL challenge 2019
Jan 11, 2022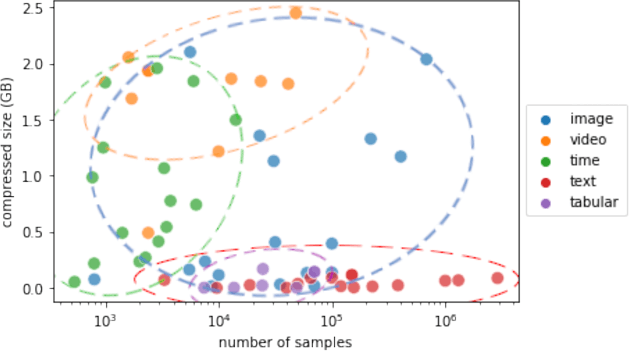
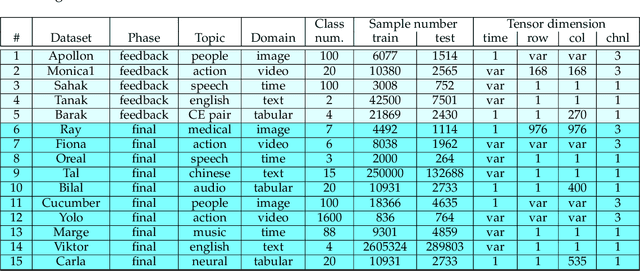
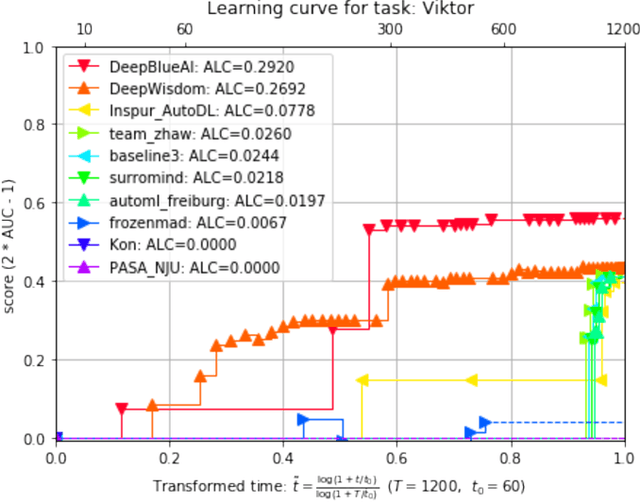
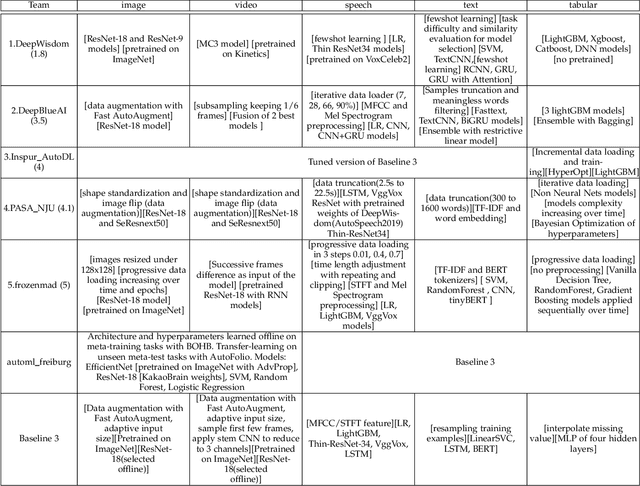
This paper reports the results and post-challenge analyses of ChaLearn's AutoDL challenge series, which helped sorting out a profusion of AutoML solutions for Deep Learning (DL) that had been introduced in a variety of settings, but lacked fair comparisons. All input data modalities (time series, images, videos, text, tabular) were formatted as tensors and all tasks were multi-label classification problems. Code submissions were executed on hidden tasks, with limited time and computational resources, pushing solutions that get results quickly. In this setting, DL methods dominated, though popular Neural Architecture Search (NAS) was impractical. Solutions relied on fine-tuned pre-trained networks, with architectures matching data modality. Post-challenge tests did not reveal improvements beyond the imposed time limit. While no component is particularly original or novel, a high level modular organization emerged featuring a "meta-learner", "data ingestor", "model selector", "model/learner", and "evaluator". This modularity enabled ablation studies, which revealed the importance of (off-platform) meta-learning, ensembling, and efficient data management. Experiments on heterogeneous module combinations further confirm the (local) optimality of the winning solutions. Our challenge legacy includes an ever-lasting benchmark (http://autodl.chalearn.org), the open-sourced code of the winners, and a free "AutoDL self-service".
* The first three authors contributed equally; This is only a draft version
Dyadformer: A Multi-modal Transformer for Long-Range Modeling of Dyadic Interactions
Sep 20, 2021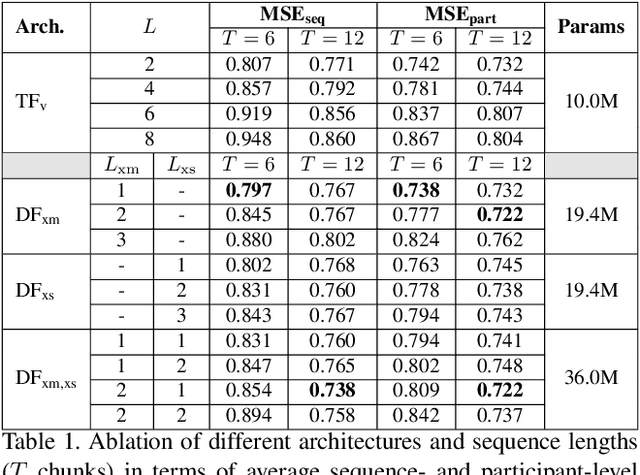
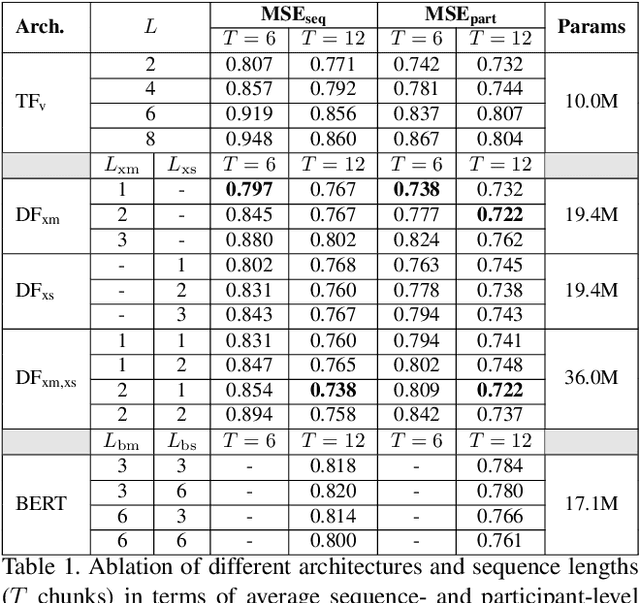
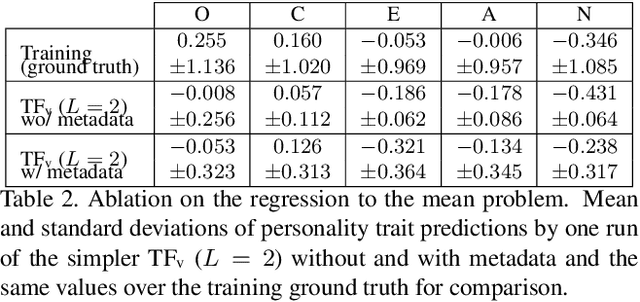
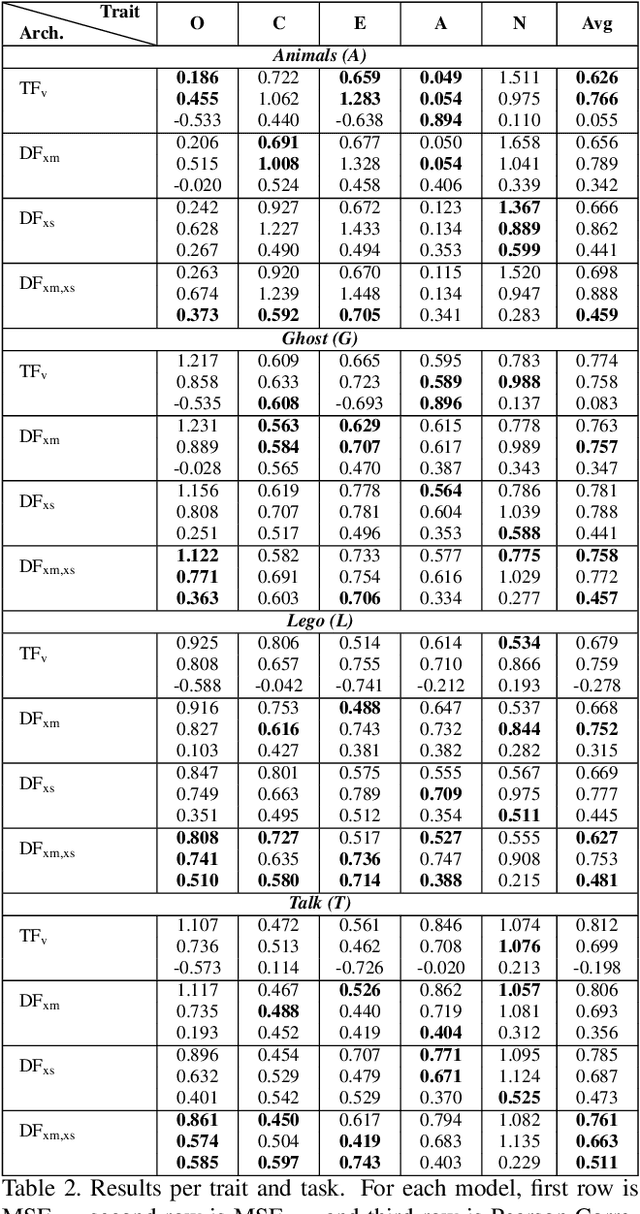
Personality computing has become an emerging topic in computer vision, due to the wide range of applications it can be used for. However, most works on the topic have focused on analyzing the individual, even when applied to interaction scenarios, and for short periods of time. To address these limitations, we present the Dyadformer, a novel multi-modal multi-subject Transformer architecture to model individual and interpersonal features in dyadic interactions using variable time windows, thus allowing the capture of long-term interdependencies. Our proposed cross-subject layer allows the network to explicitly model interactions among subjects through attentional operations. This proof-of-concept approach shows how multi-modality and joint modeling of both interactants for longer periods of time helps to predict individual attributes. With Dyadformer, we improve state-of-the-art self-reported personality inference results on individual subjects on the UDIVA v0.5 dataset.
ChaLearn LAP Large Scale Signer Independent Isolated Sign Language Recognition Challenge: Design, Results and Future Research
May 11, 2021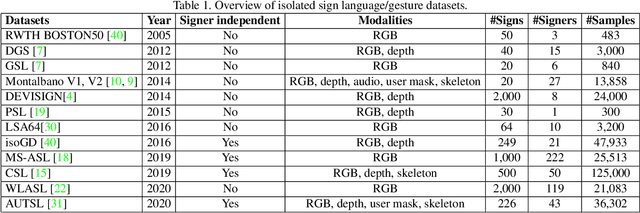

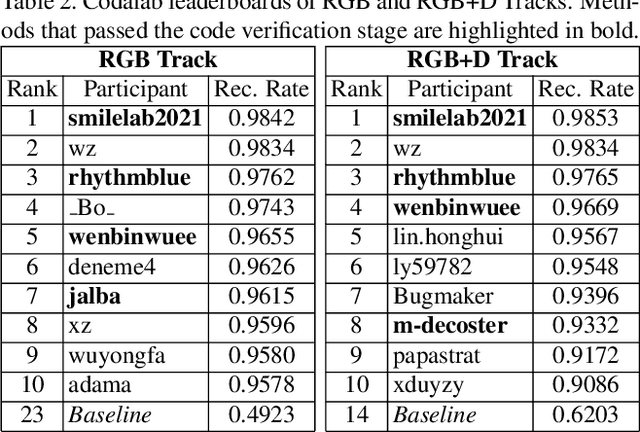
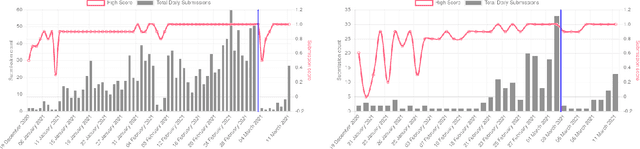
The performances of Sign Language Recognition (SLR) systems have improved considerably in recent years. However, several open challenges still need to be solved to allow SLR to be useful in practice. The research in the field is in its infancy in regards to the robustness of the models to a large diversity of signs and signers, and to fairness of the models to performers from different demographics. This work summarises the ChaLearn LAP Large Scale Signer Independent Isolated SLR Challenge, organised at CVPR 2021 with the goal of overcoming some of the aforementioned challenges. We analyse and discuss the challenge design, top winning solutions and suggestions for future research. The challenge attracted 132 participants in the RGB track and 59 in the RGB+Depth track, receiving more than 1.5K submissions in total. Participants were evaluated using a new large-scale multi-modal Turkish Sign Language (AUTSL) dataset, consisting of 226 sign labels and 36,302 isolated sign video samples performed by 43 different signers. Winning teams achieved more than 96% recognition rate, and their approaches benefited from pose/hand/face estimation, transfer learning, external data, fusion/ensemble of modalities and different strategies to model spatio-temporal information. However, methods still fail to distinguish among very similar signs, in particular those sharing similar hand trajectories.
Context-Aware Personality Inference in Dyadic Scenarios: Introducing the UDIVA Dataset
Dec 28, 2020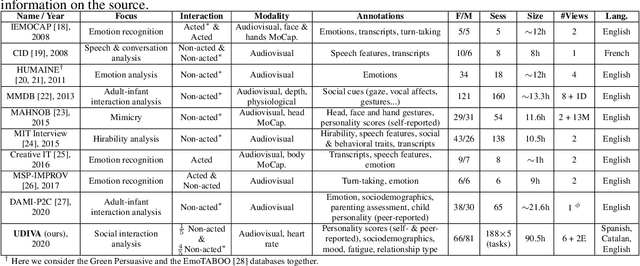


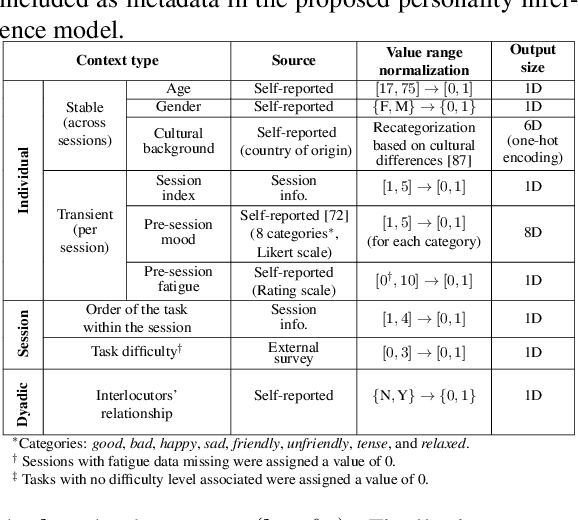
This paper introduces UDIVA, a new non-acted dataset of face-to-face dyadic interactions, where interlocutors perform competitive and collaborative tasks with different behavior elicitation and cognitive workload. The dataset consists of 90.5 hours of dyadic interactions among 147 participants distributed in 188 sessions, recorded using multiple audiovisual and physiological sensors. Currently, it includes sociodemographic, self- and peer-reported personality, internal state, and relationship profiling from participants. As an initial analysis on UDIVA, we propose a transformer-based method for self-reported personality inference in dyadic scenarios, which uses audiovisual data and different sources of context from both interlocutors to regress a target person's personality traits. Preliminary results from an incremental study show consistent improvements when using all available context information.
Person Perception Biases Exposed: Revisiting the First Impressions Dataset
Nov 30, 2020


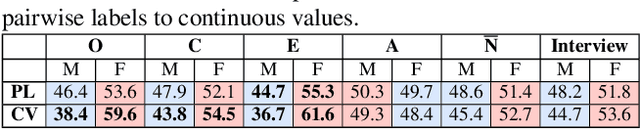
This work revisits the ChaLearn First Impressions database, annotated for personality perception using pairwise comparisons via crowdsourcing. We analyse for the first time the original pairwise annotations, and reveal existing person perception biases associated to perceived attributes like gender, ethnicity, age and face attractiveness. We show how person perception bias can influence data labelling of a subjective task, which has received little attention from the computer vision and machine learning communities by now. We further show that the mechanism used to convert pairwise annotations to continuous values may magnify the biases if no special treatment is considered. The findings of this study are relevant for the computer vision community that is still creating new datasets on subjective tasks, and using them for practical applications, ignoring these perceptual biases.
FairFace Challenge at ECCV 2020: Analyzing Bias in Face Recognition
Sep 16, 2020
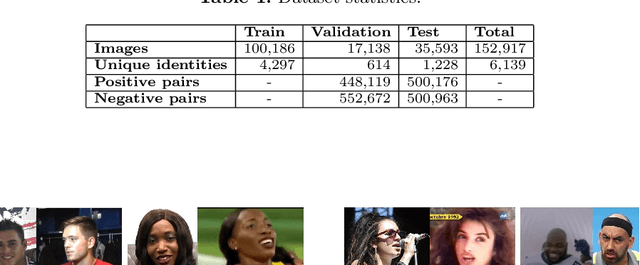
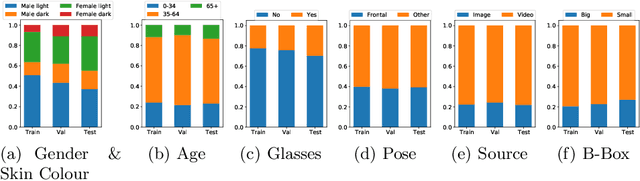
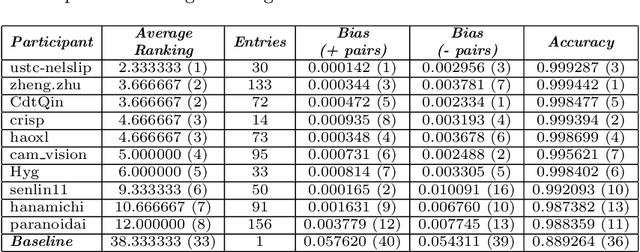
This work summarizes the 2020 ChaLearn Looking at People Fair Face Recognition and Analysis Challenge and provides a description of the top-winning solutions and analysis of the results. The aim of the challenge was to evaluate accuracy and bias in gender and skin colour of submitted algorithms on the task of 1:1 face verification in the presence of other confounding attributes. Participants were evaluated using an in-the-wild dataset based on reannotated IJB-C, further enriched by 12.5K new images and additional labels. The dataset is not balanced, which simulates a real world scenario where AI-based models supposed to present fair outcomes are trained and evaluated on imbalanced data. The challenge attracted 151 participants, who made more than 1.8K submissions in total. The final phase of the challenge attracted 36 active teams out of which 10 exceeded 0.999 AUC-ROC while achieving very low scores in the proposed bias metrics. Common strategies by the participants were face pre-processing, homogenization of data distributions, the use of bias aware loss functions and ensemble models. The analysis of top-10 teams shows higher false positive rates (and lower false negative rates) for females with dark skin tone as well as the potential of eyeglasses and young age to increase the false positive rates too.
On the Effect of Observed Subject Biases in Apparent Personality Analysis from Audio-visual Signals
Sep 12, 2019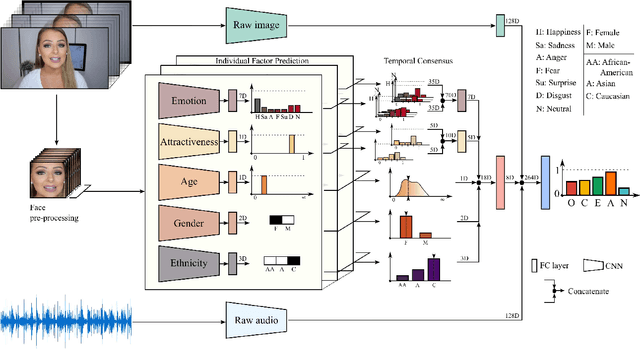



Personality perception is implicitly biased due to many subjective factors, such as cultural, social, contextual, gender and appearance. Approaches developed for automatic personality perception are not expected to predict the real personality of the target, but the personality external observers attributed to it. Hence, they have to deal with human bias, inherently transferred to the training data. However, bias analysis in personality computing is an almost unexplored area. In this work, we study different possible sources of bias affecting personality perception, including emotions from facial expressions, attractiveness, age, gender, and ethnicity, as well as their influence on prediction ability for apparent personality estimation. To this end, we propose a multi-modal deep neural network that combines raw audio and visual information alongside predictions of attribute-specific models to regress apparent personality. We also analyse spatio-temporal aggregation schemes and the effect of different time intervals on first impressions. We base our study on the ChaLearn First Impressions dataset, consisting of one-person conversational videos. Our model shows state-of-the-art results regressing apparent personality based on the Big-Five model. Furthermore, given the interpretability nature of our network design, we provide an incremental analysis on the impact of each possible source of bias on final network predictions.
On the effect of age perception biases for real age regression
Feb 20, 2019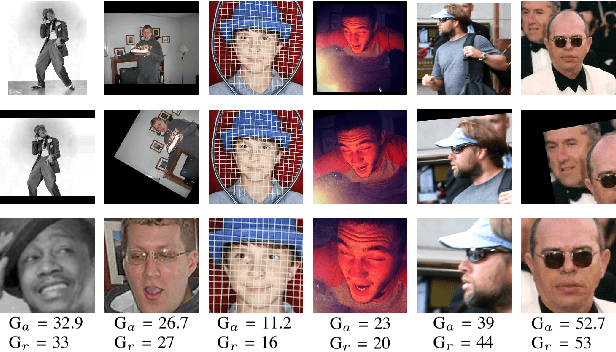
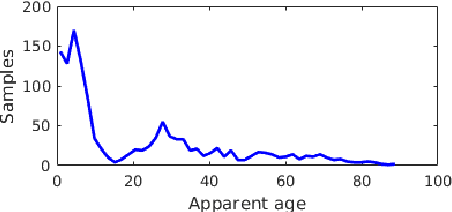
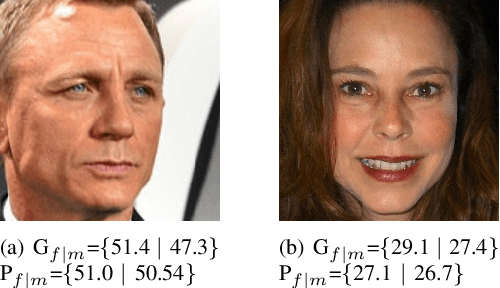

Automatic age estimation from facial images represents an important task in computer vision. This paper analyses the effect of gender, age, ethnic, makeup and expression attributes of faces as sources of bias to improve deep apparent age prediction. Following recent works where it is shown that apparent age labels benefit real age estimation, rather than direct real to real age regression, our main contribution is the integration, in an end-to-end architecture, of face attributes for apparent age prediction with an additional loss for real age regression. Experimental results on the APPA-REAL dataset indicate the proposed network successfully take advantage of the adopted attributes to improve both apparent and real age estimation. Our model outperformed a state-of-the-art architecture proposed to separately address apparent and real age regression. Finally, we present preliminary results and discussion of a proof of concept application using the proposed model to regress the apparent age of an individual based on the gender of an external observer.
First Impressions: A Survey on Computer Vision-Based Apparent Personality Trait Analysis
Apr 21, 2018
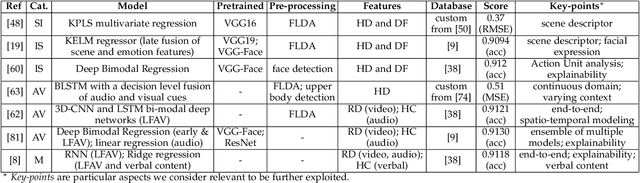
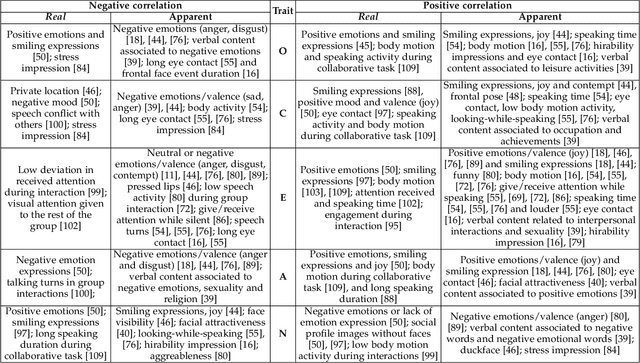
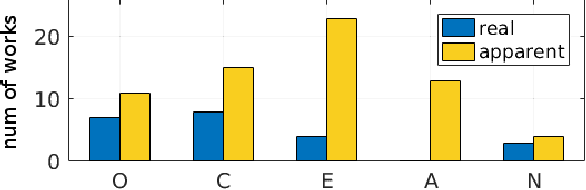
Personality analysis has been widely studied in psychology, neuropsychology, signal processing fields, among others. From the computing point of view, by far speech and text have been the most analyzed cues of information for analyzing personality. However, recently there has been an increasing interest form the computer vision community in analyzing personality starting from visual information. Recent computer vision approaches are able to accurately analyze human faces, body postures and behaviors, and use these information to infer apparent personality traits. Because of the overwhelming research interest in this topic, and of the potential impact that this sort of methods could have in society, we present in this paper an up-to-date review of existing computer vision-based visual and multimodal approaches for apparent personality trait recognition. We describe seminal and cutting edge works on the subject, discussing and comparing their distinctive features. More importantly, future venues of research in the field are identified and discussed. Furthermore, aspects on the subjectivity in data labeling/evaluation, as well as current datasets and challenges organized to push the research on the field are reviewed. Hence, the survey provides an up-to-date review of research progress in a wide range of aspects of this research theme.