 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyadformer: A Multi-modal Transformer for Long-Range Modeling of Dyadic Interactions
Sep 20, 2021
Personality computing has become an emerging topic in computer vision, due to the wide range of applications it can be used for. However, most works on the topic have focused on analyzing the individual, even when applied to interaction scenarios, and for short periods of time. To address these limitations, we present the Dyadformer, a novel multi-modal multi-subject Transformer architecture to model individual and interpersonal features in dyadic interactions using variable time windows, thus allowing the capture of long-term interdependencies. Our proposed cross-subject layer allows the network to explicitly model interactions among subjects through attentional operations. This proof-of-concept approach shows how multi-modality and joint modeling of both interactants for longer periods of time helps to predict individual attributes. With Dyadformer, we improve state-of-the-art self-reported personality inference results on individual subjects on the UDIVA v0.5 dataset.
Context-Aware Personality Inference in Dyadic Scenarios: Introducing the UDIVA Dataset
Dec 28, 2020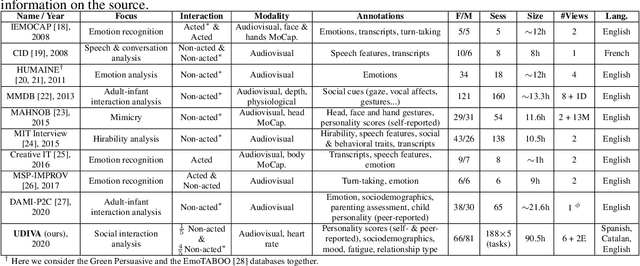


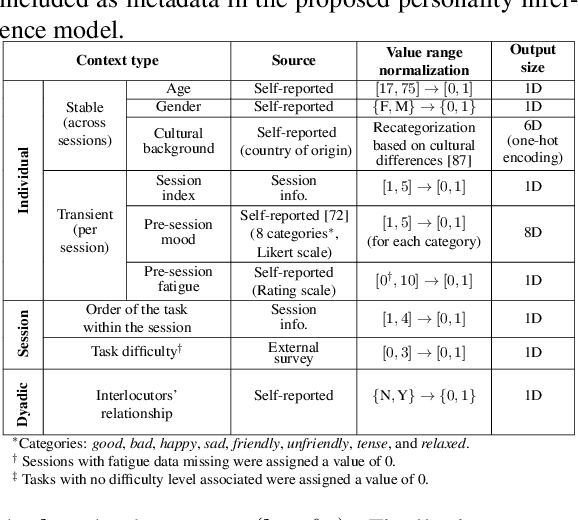
This paper introduces UDIVA, a new non-acted dataset of face-to-face dyadic interactions, where interlocutors perform competitive and collaborative tasks with different behavior elicitation and cognitive workload. The dataset consists of 90.5 hours of dyadic interactions among 147 participants distributed in 188 sessions, recorded using multiple audiovisual and physiological sensors. Currently, it includes sociodemographic, self- and peer-reported personality, internal state, and relationship profiling from participants. As an initial analysis on UDIVA, we propose a transformer-based method for self-reported personality inference in dyadic scenarios, which uses audiovisual data and different sources of context from both interlocutors to regress a target person's personality traits. Preliminary results from an incremental study show consistent improvements when using all available context information.