 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyadformer: A Multi-modal Transformer for Long-Range Modeling of Dyadic Interactions
Sep 20, 2021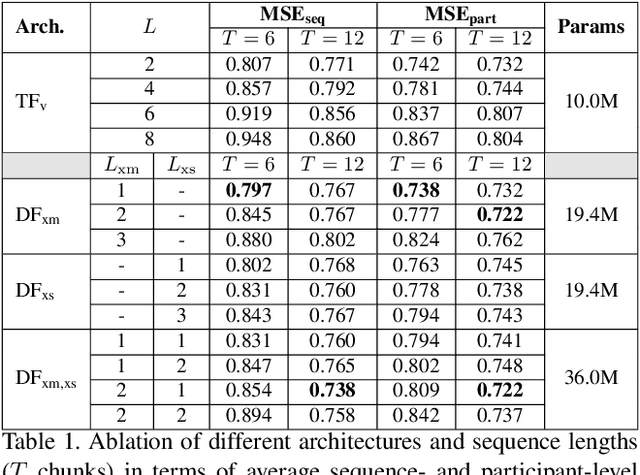
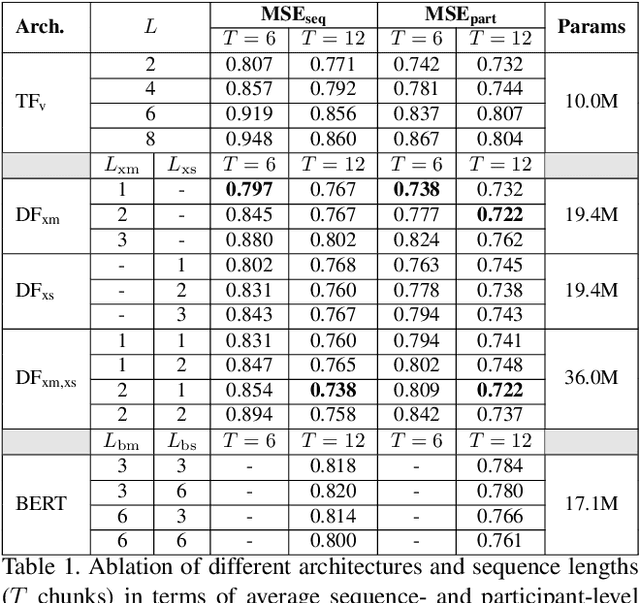
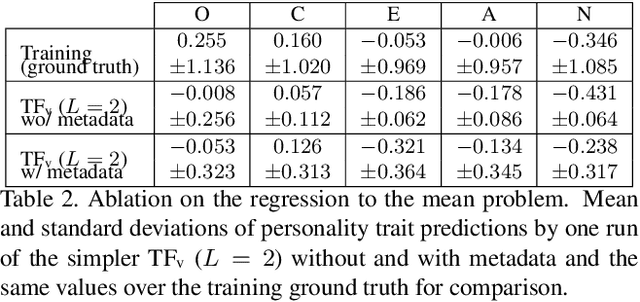
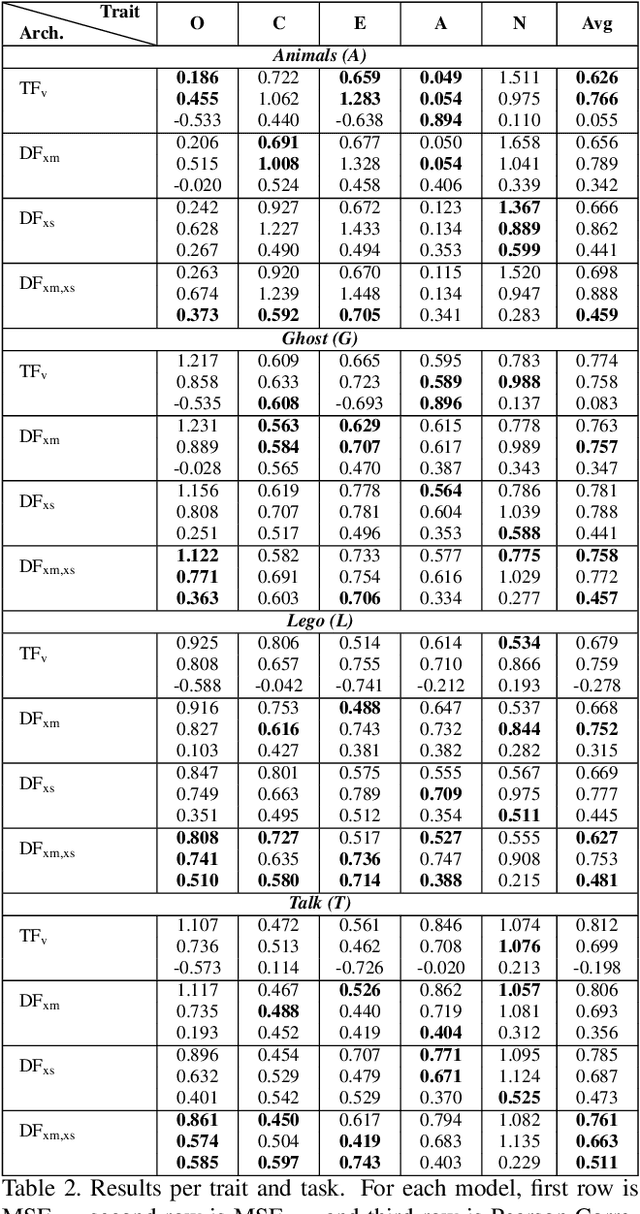
Personality computing has become an emerging topic in computer vision, due to the wide range of applications it can be used for. However, most works on the topic have focused on analyzing the individual, even when applied to interaction scenarios, and for short periods of time. To address these limitations, we present the Dyadformer, a novel multi-modal multi-subject Transformer architecture to model individual and interpersonal features in dyadic interactions using variable time windows, thus allowing the capture of long-term interdependencies. Our proposed cross-subject layer allows the network to explicitly model interactions among subjects through attentional operations. This proof-of-concept approach shows how multi-modality and joint modeling of both interactants for longer periods of time helps to predict individual attributes. With Dyadformer, we improve state-of-the-art self-reported personality inference results on individual subjects on the UDIVA v0.5 dataset.
Context-Aware Personality Inference in Dyadic Scenarios: Introducing the UDIVA Dataset
Dec 28, 2020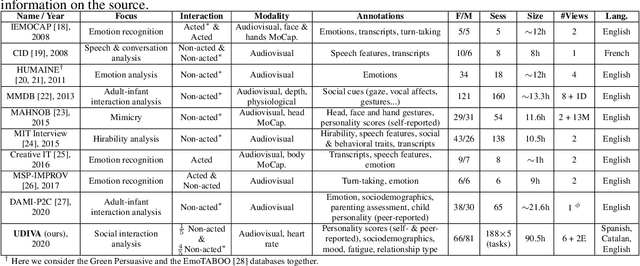


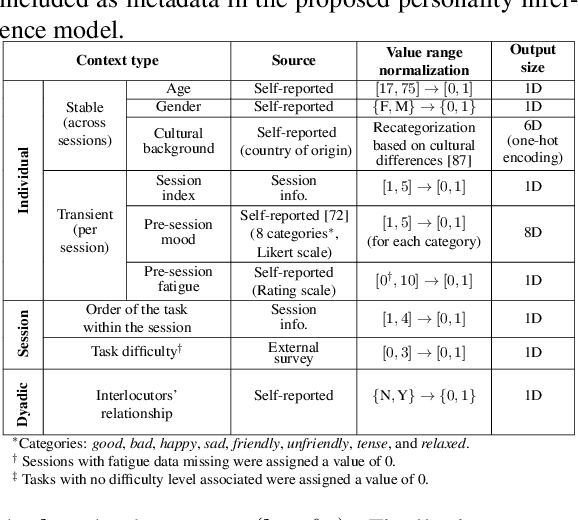
This paper introduces UDIVA, a new non-acted dataset of face-to-face dyadic interactions, where interlocutors perform competitive and collaborative tasks with different behavior elicitation and cognitive workload. The dataset consists of 90.5 hours of dyadic interactions among 147 participants distributed in 188 sessions, recorded using multiple audiovisual and physiological sensors. Currently, it includes sociodemographic, self- and peer-reported personality, internal state, and relationship profiling from participants. As an initial analysis on UDIVA, we propose a transformer-based method for self-reported personality inference in dyadic scenarios, which uses audiovisual data and different sources of context from both interlocutors to regress a target person's personality traits. Preliminary results from an incremental study show consistent improvements when using all available context information.
Detecting abnormal events in video using Narrowed Motion Clusters
Jun 15, 2018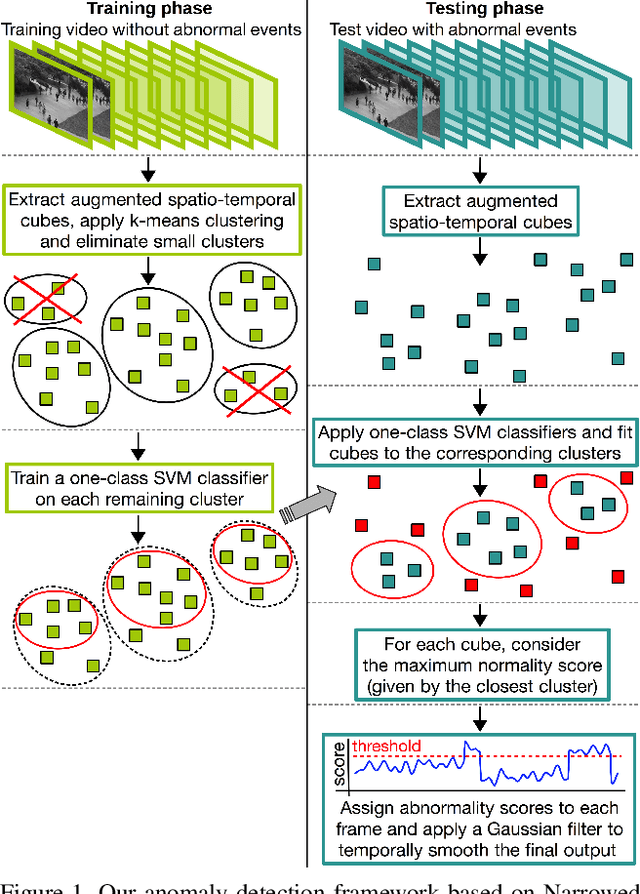
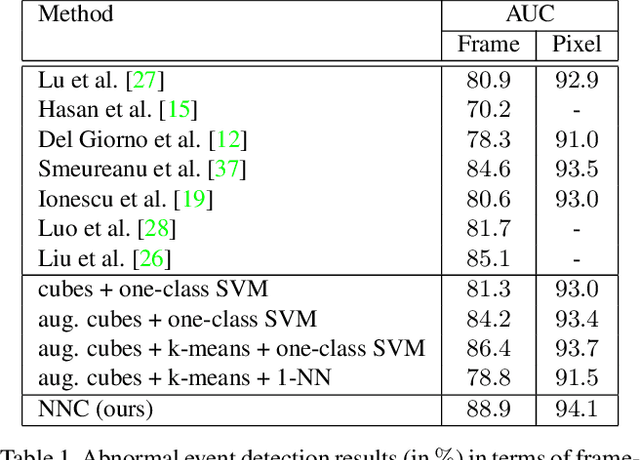
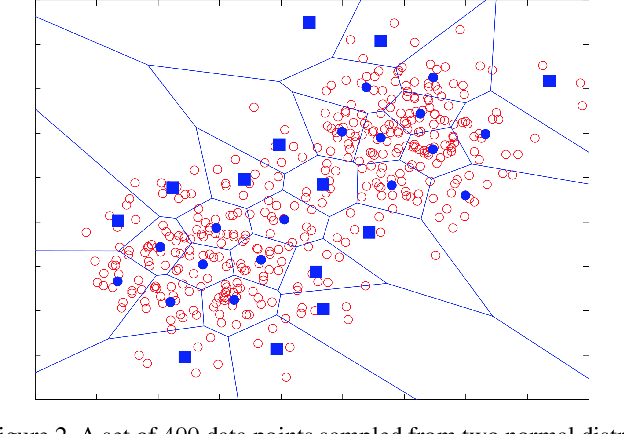
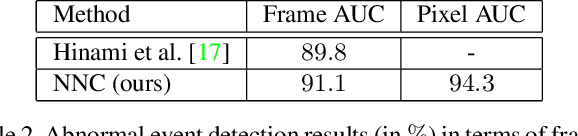
We formulate the abnormal event detection problem as an outlier detection task and we propose a two-stage algorithm based on k-means clustering and one-class Support Vector Machines (SVM) to eliminate outliers. After extracting motion features from the training video containing only normal events, we apply k-means clustering to find clusters representing different types of motion. In the first stage, we consider that clusters with fewer samples (with respect to a given threshold) contain only outliers and we eliminate these clusters altogether. In the second stage, we shrink the borders of the remaining clusters by training a one-class SVM model on each cluster. To detected abnormal events in the test video, we analyze each test sample and consider its maximum normality score provided by the trained one-class SVM models, based on the intuition that a test sample can belong to only one cluster of normal motion. If the test sample does not fit well in any narrowed cluster, than it is labeled as abnormal. We also combine our approach based on motion features with a recent approach based on deep appearance features extracted with pre-trained convolutional neural networks (CNN). We combine our two-stage algorithm with the deep framework using a late fusion strategy, keeping the pipelines of the two approaches independent. We compare our method with several state-of-the-art supervised and unsupervised methods on four benchmark data sets. The empirical results indicate that our abnormal event detection framework can achieve better results in most cases, while processing the test video in real-time at 32 frames per second on CPU.
Real-Time Deep Learning Method for Abandoned Luggage Detection in Video
Jun 15, 2018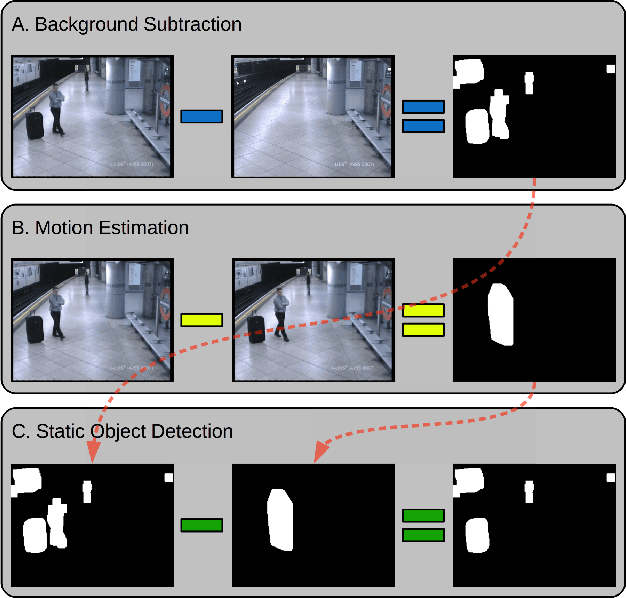
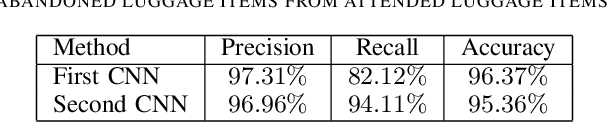

Recent terrorist attacks in major cities around the world have brought many casualties among innocent citizens. One potential threat is represented by abandoned luggage items (that could contain bombs or biological warfare) in public areas. In this paper, we describe an approach for real-time automatic detection of abandoned luggage in video captured by surveillance cameras. The approach is comprised of two stages: (i) static object detection based on background subtraction and motion estimation and (ii) abandoned luggage recognition based on a cascade of convolutional neural networks (CNN). To train our neural networks we provide two types of examples: images collected from the Internet and realistic examples generated by imposing various suitcases and bags over the scene's background. We present empirical results demonstrating that our approach yields better performance than a strong CNN baseline method.
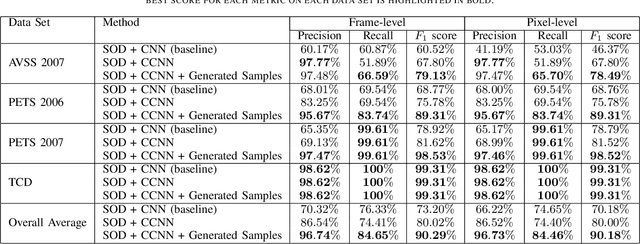
Unmasking the abnormal events in video
Jul 25, 2017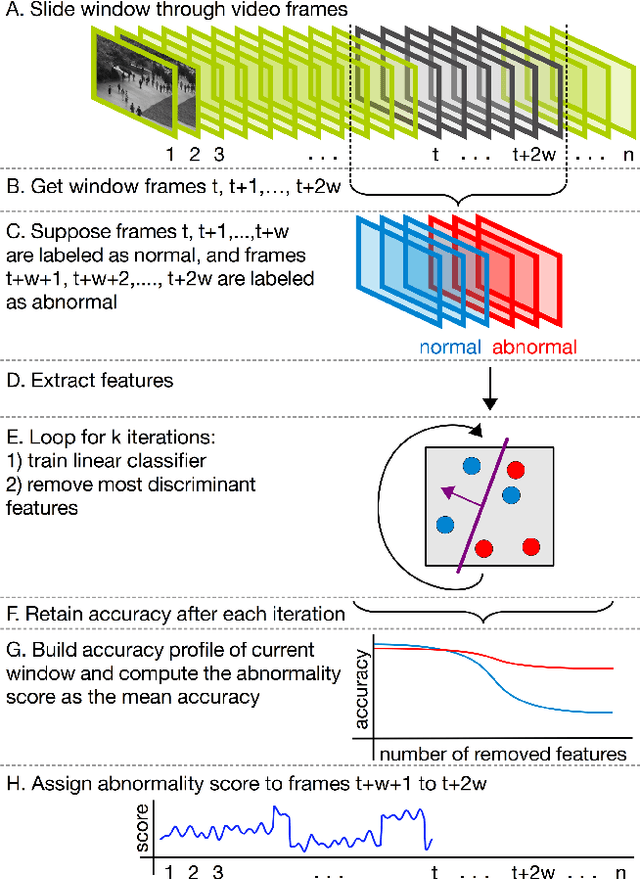
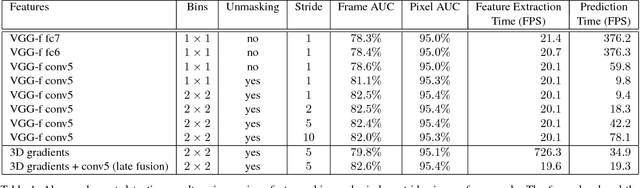
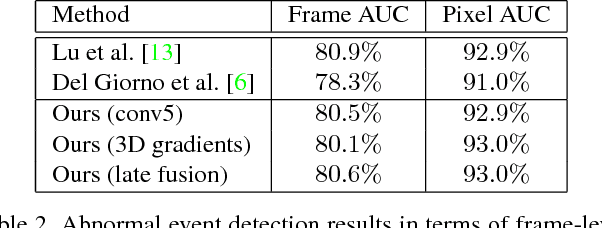
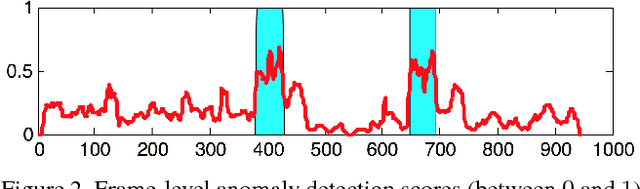
We propose a novel framework for abnormal event detection in video that requires no training sequences. Our framework is based on unmasking, a technique previously used for authorship verification in text documents, which we adapt to our task. We iteratively train a binary classifier to distinguish between two consecutive video sequences while removing at each step the most discriminant features. Higher training accuracy rates of the intermediately obtained classifiers represent abnormal events. To the best of our knowledge, this is the first work to apply unmasking for a computer vision task. We compare our method with several state-of-the-art supervised and unsupervised methods on four benchmark data sets. The empirical results indicate that our abnormal event detection framework can achieve state-of-the-art results, while running in real-time at 20 frames per second.