 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Coreference Resolution via Cycle-Consistent Machine Translation
Jun 03, 2026Coreference resolution is a core NLP task, having a broad range of downstream applications, e.g.~machine translation, question answering, document summarization, etc. While the task is well-studied in English, comparatively less attention is dedicated to coreference resolution in other languages, especially low-resource ones. To mitigate this gap, we propose a novel coreference resolution pipeline that harnesses machine translation (MT) from English to a target low-resource language, to generate or expand training data. To automatically validate the quality of the translated samples, we back-translate the samples and assess the similarity with the original English samples via cosine similarity in the latent space of a BERT model. The resulting similarity scores are integrated into the loss function to weight training samples according to their MT cycle consistency. Extensive experiments on four low-resource languages show that our pipeline brings significant performance gains in coreference resolution. Moreover, our pipeline enables accurate coreference resolution in languages where no previous corpora were available.
MTL-MAD: Multi-Task Learners are Effective Medical Anomaly Detectors
May 07, 2026Anomaly detection in medical images is a challenging task, since anomalies are not typically available during training. Recent methods leverage a single pretext task coupled with a large-scale pre-trained model to reach state-of-the-art performance. Instead, we propose to learn multiple self-supervised and pseudo-labeling tasks from scratch, using a joint model based on Mixture-of-Experts (MoE). By carefully integrating multiple proxy tasks, the joint model effectively learns a robust representation of normal anatomical structures, so that anomaly scores can be derived based on how well the multi-task learner (MTL) solves each task during inference. We perform comprehensive experiments on BMAD, a recent benchmark that comprises a broad range of medical image modalities. The empirical results indicate that our multi-task learner is an effective anomaly detector, outperforming all state-of-the-art competitors on BMAD. Moreover, our model produces interpretable anomaly maps, potentially helping physicians in providing more accurate diagnoses.
Out of Context: Reliability in Multimodal Anomaly Detection Requires Contextual Inference
Apr 14, 2026Anomaly detection aims to identify observations that deviate from expected behavior. Because anomalous events are inherently sparse, most frameworks are trained exclusively on normal data to learn a single reference model of normality. This implicitly assumes that normal behavior can be captured by a single, unconditional reference distribution. In practice, however, anomalies are often context-dependent: A specific observation may be normal under one operating condition, yet anomalous under another. As machine learning systems are deployed in dynamic and heterogeneous environments, these fixed-context assumptions introduce structural ambiguity, i.e., the inability to distinguish contextual variation from genuine abnormality under marginal modeling, leading to unstable performance and unreliable anomaly assessments. While modern sensing systems frequently collect multimodal data capturing complementary aspects of both system behavior and operating conditions, existing methods treat all data streams equally, without distinguishing contextual information from anomaly-relevant signals. As a result, abnormality is often evaluated without explicitly conditioning on operating conditions. We argue that multimodal anomaly detection should be reframed as a cross-modal contextual inference problem, in which modalities play asymmetric roles, separating context from observation, to define abnormality conditionally rather than relative to a single global reference. This perspective has implications for model design, evaluation protocols, and benchmark construction, and outline open research challenges toward robust, context-aware multimodal anomaly detection.
SegMate: Asymmetric Attention-Based Lightweight Architecture for Efficient Multi-Organ Segmentation
Feb 27, 2026State-of-the-art models for medical image segmentation achieve excellent accuracy but require substantial computational resources, limiting deployment in resource-constrained clinical settings. We present SegMate, an efficient 2.5D framework that achieves state-of-the-art accuracy, while considerably reducing computational requirements. Our efficient design is the result of meticulously integrating asymmetric architectures, attention mechanisms, multi-scale feature fusion, slice-based positional conditioning, and multi-task optimization. We demonstrate the efficiency-accuracy trade-off of our framework across three modern backbones (EfficientNetV2-M, MambaOut-Tiny, FastViT-T12). We perform experiments on three datasets: TotalSegmentator, SegTHOR and AMOS22. Compared with the vanilla models, SegMate reduces computation (GFLOPs) by up to 2.5x and memory footprint (VRAM) by up to 2.1x, while generally registering performance gains of around 1%. On TotalSegmentator, we achieve a Dice score of 93.51% with only 295MB peak GPU memory. Zero-shot cross-dataset evaluations on SegTHOR and AMOS22 demonstrate strong generalization, with Dice scores of up to 86.85% and 89.35%, respectively. We release our open-source code at https://github.com/andreibunea99/SegMate.
Curriculum-DPO++: Direct Preference Optimization via Data and Model Curricula for Text-to-Image Generation
Feb 13, 2026Direct Preference Optimization (DPO) has been proposed as an effective and efficient alternative to reinforcement learning from human feedback (RLHF). However, neither RLHF nor DPO take into account the fact that learning certain preferences is more difficult than learning other preferences, rendering the optimization process suboptimal. To address this gap in text-to-image generation, we recently proposed Curriculum-DPO, a method that organizes image pairs by difficulty. In this paper, we introduce Curriculum-DPO++, an enhanced method that combines the original data-level curriculum with a novel model-level curriculum. More precisely, we propose to dynamically increase the learning capacity of the denoising network as training advances. We implement this capacity increase via two mechanisms. First, we initialize the model with only a subset of the trainable layers used in the original Curriculum-DPO. As training progresses, we sequentially unfreeze layers until the configuration matches the full baseline architecture. Second, as the fine-tuning is based on Low-Rank Adaptation (LoRA), we implement a progressive schedule for the dimension of the low-rank matrices. Instead of maintaining a fixed capacity, we initialize the low-rank matrices with a dimension significantly smaller than that of the baseline. As training proceeds, we incrementally increase their rank, allowing the capacity to grow until it converges to the same rank value as in Curriculum-DPO. Furthermore, we propose an alternative ranking strategy to the one employed by Curriculum-DPO. Finally, we compare Curriculum-DPO++ against Curriculum-DPO and other state-of-the-art preference optimization approaches on nine benchmarks, outperforming the competing methods in terms of text alignment, aesthetics and human preference. Our code is available at https://github.com/CroitoruAlin/Curriculum-DPO.
MOSLD-Bench: Multilingual Open-Set Learning and Discovery Benchmark for Text Categorization
Jan 19, 2026Open-set learning and discovery (OSLD) is a challenging machine learning task in which samples from new (unknown) classes can appear at test time. It can be seen as a generalization of zero-shot learning, where the new classes are not known a priori, hence involving the active discovery of new classes. While zero-shot learning has been extensively studied in text classification, especially with the emergence of pre-trained language models, open-set learning and discovery is a comparatively new setup for the text domain. To this end, we introduce the first multilingual open-set learning and discovery (MOSLD) benchmark for text categorization by topic, comprising 960K data samples across 12 languages. To construct the benchmark, we (i) rearrange existing datasets and (ii) collect new data samples from the news domain. Moreover, we propose a novel framework for the OSLD task, which integrates multiple stages to continuously discover and learn new classes. We evaluate several language models, including our own, to obtain results that can be used as reference for future work. We release our benchmark at https://github.com/Adriana19Valentina/MOSLD-Bench.
CLewR: Curriculum Learning with Restarts for Machine Translation Preference Learning
Jan 09, 2026Large language models (LLMs) have demonstrated competitive performance in zero-shot multilingual machine translation (MT). Some follow-up works further improved MT performance via preference optimization, but they leave a key aspect largely underexplored: the order in which data samples are given during training. We address this topic by integrating curriculum learning into various state-of-the-art preference optimization algorithms to boost MT performance. We introduce a novel curriculum learning strategy with restarts (CLewR), which reiterates easy-to-hard curriculum multiple times during training to effectively mitigate the catastrophic forgetting of easy examples. We demonstrate consistent gains across several model families (Gemma2, Qwen2.5, Llama3.1) and preference optimization techniques. We publicly release our code at https://github.com/alexandra-dragomir/CLewR.
Machine Unlearning in the Era of Quantum Machine Learning: An Empirical Study
Dec 23, 2025


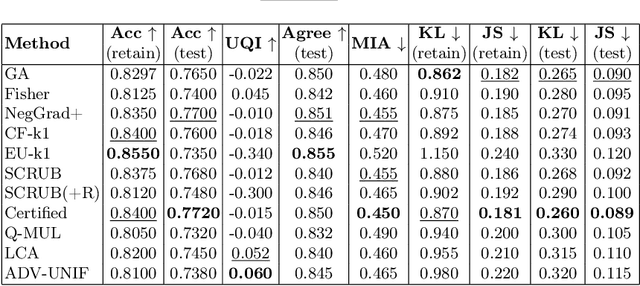
We present the first comprehensive empirical study of machine unlearning (MU) in hybrid quantum-classical neural networks. While MU has been extensively explored in classical deep learning, its behavior within variational quantum circuits (VQCs) and quantum-augmented architectures remains largely unexplored. First, we adapt a broad suite of unlearning methods to quantum settings, including gradient-based, distillation-based, regularization-based and certified techniques. Second, we introduce two new unlearning strategies tailored to hybrid models. Experiments across Iris, MNIST, and Fashion-MNIST, under both subset removal and full-class deletion, reveal that quantum models can support effective unlearning, but outcomes depend strongly on circuit depth, entanglement structure, and task complexity. Shallow VQCs display high intrinsic stability with minimal memorization, whereas deeper hybrid models exhibit stronger trade-offs between utility, forgetting strength, and alignment with retrain oracle. We find that certain methods, e.g. EU-k, LCA, and Certified Unlearning, consistently provide the best balance across metrics. These findings establish baseline empirical insights into quantum machine unlearning and highlight the need for quantum-aware algorithms and theoretical guarantees, as quantum machine learning systems continue to expand in scale and capability. We publicly release our code at: https://github.com/CrivoiCarla/HQML.
AutoMalDesc: Large-Scale Script Analysis for Cyber Threat Research
Nov 17, 2025Generating thorough natural language explanations for threat detections remains an open problem in cybersecurity research, despite significant advances in automated malware detection systems. In this work, we present AutoMalDesc, an automated static analysis summarization framework that, following initial training on a small set of expert-curated examples, operates independently at scale. This approach leverages an iterative self-paced learning pipeline to progressively enhance output quality through synthetic data generation and validation cycles, eliminating the need for extensive manual data annotation. Evaluation across 3,600 diverse samples in five scripting languages demonstrates statistically significant improvements between iterations, showing consistent gains in both summary quality and classification accuracy. Our comprehensive validation approach combines quantitative metrics based on established malware labels with qualitative assessment from both human experts and LLM-based judges, confirming both technical precision and linguistic coherence of generated summaries. To facilitate reproducibility and advance research in this domain, we publish our complete dataset of more than 100K script samples, including annotated seed (0.9K) and test (3.6K) datasets, along with our methodology and evaluation framework.
Curriculum Multi-Task Self-Supervision Improves Lightweight Architectures for Onboard Satellite Hyperspectral Image Segmentation
Sep 16, 2025



Hyperspectral imaging (HSI) captures detailed spectral signatures across hundreds of contiguous bands per pixel, being indispensable for remote sensing applications such as land-cover classification, change detection, and environmental monitoring. Due to the high dimensionality of HSI data and the slow rate of data transfer in satellite-based systems, compact and efficient models are required to support onboard processing and minimize the transmission of redundant or low-value data, e.g. cloud-covered areas. To this end, we introduce a novel curriculum multi-task self-supervised learning (CMTSSL) framework designed for lightweight architectures for HSI analysis. CMTSSL integrates masked image modeling with decoupled spatial and spectral jigsaw puzzle solving, guided by a curriculum learning strategy that progressively increases data complexity during self-supervision. This enables the encoder to jointly capture fine-grained spectral continuity, spatial structure, and global semantic features. Unlike prior dual-task SSL methods, CMTSSL simultaneously addresses spatial and spectral reasoning within a unified and computationally efficient design, being particularly suitable for training lightweight models for onboard satellite deployment. We validate our approach on four public benchmark datasets, demonstrating consistent gains in downstream segmentation tasks, using architectures that are over 16,000x lighter than some state-of-the-art models. These results highlight the potential of CMTSSL in generalizable representation learning with lightweight architectures for real-world HSI applications. Our code is publicly available at https://github.com/hugocarlesso/CMTSSL.