 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum-DPO++: Direct Preference Optimization via Data and Model Curricula for Text-to-Image Generation
Feb 13, 2026Direct Preference Optimization (DPO) has been proposed as an effective and efficient alternative to reinforcement learning from human feedback (RLHF). However, neither RLHF nor DPO take into account the fact that learning certain preferences is more difficult than learning other preferences, rendering the optimization process suboptimal. To address this gap in text-to-image generation, we recently proposed Curriculum-DPO, a method that organizes image pairs by difficulty. In this paper, we introduce Curriculum-DPO++, an enhanced method that combines the original data-level curriculum with a novel model-level curriculum. More precisely, we propose to dynamically increase the learning capacity of the denoising network as training advances. We implement this capacity increase via two mechanisms. First, we initialize the model with only a subset of the trainable layers used in the original Curriculum-DPO. As training progresses, we sequentially unfreeze layers until the configuration matches the full baseline architecture. Second, as the fine-tuning is based on Low-Rank Adaptation (LoRA), we implement a progressive schedule for the dimension of the low-rank matrices. Instead of maintaining a fixed capacity, we initialize the low-rank matrices with a dimension significantly smaller than that of the baseline. As training proceeds, we incrementally increase their rank, allowing the capacity to grow until it converges to the same rank value as in Curriculum-DPO. Furthermore, we propose an alternative ranking strategy to the one employed by Curriculum-DPO. Finally, we compare Curriculum-DPO++ against Curriculum-DPO and other state-of-the-art preference optimization approaches on nine benchmarks, outperforming the competing methods in terms of text alignment, aesthetics and human preference. Our code is available at https://github.com/CroitoruAlin/Curriculum-DPO.
MAVOS-DD: Multilingual Audio-Video Open-Set Deepfake Detection Benchmark
May 16, 2025We present the first large-scale open-set benchmark for multilingual audio-video deepfake detection. Our dataset comprises over 250 hours of real and fake videos across eight languages, with 60% of data being generated. For each language, the fake videos are generated with seven distinct deepfake generation models, selected based on the quality of the generated content. We organize the training, validation and test splits such that only a subset of the chosen generative models and languages are available during training, thus creating several challenging open-set evaluation setups. We perform experiments with various pre-trained and fine-tuned deepfake detectors proposed in recent literature. Our results show that state-of-the-art detectors are not currently able to maintain their performance levels when tested in our open-set scenarios. We publicly release our data and code at: https://huggingface.co/datasets/unibuc-cs/MAVOS-DD.
Deepfake Media Generation and Detection in the Generative AI Era: A Survey and Outlook
Nov 29, 2024



With the recent advancements in generative modeling, the realism of deepfake content has been increasing at a steady pace, even reaching the point where people often fail to detect manipulated media content online, thus being deceived into various kinds of scams. In this paper, we survey deepfake generation and detection techniques, including the most recent developments in the field, such as diffusion models and Neural Radiance Fields. Our literature review covers all deepfake media types, comprising image, video, audio and multimodal (audio-visual) content. We identify various kinds of deepfakes, according to the procedure used to alter or generate the fake content. We further construct a taxonomy of deepfake generation and detection methods, illustrating the important groups of methods and the domains where these methods are applied. Next, we gather datasets used for deepfake detection and provide updated rankings of the best performing deepfake detectors on the most popular datasets. In addition, we develop a novel multimodal benchmark to evaluate deepfake detectors on out-of-distribution content. The results indicate that state-of-the-art detectors fail to generalize to deepfake content generated by unseen deepfake generators. Finally, we propose future directions to obtain robust and powerful deepfake detectors. Our project page and new benchmark are available at https://github.com/CroitoruAlin/biodeep.
CBM: Curriculum by Masking
Jul 09, 2024



We propose Curriculum by Masking (CBM), a novel state-of-the-art curriculum learning strategy that effectively creates an easy-to-hard training schedule via patch (token) masking, offering significant accuracy improvements over the conventional training regime and previous curriculum learning (CL) methods. CBM leverages gradient magnitudes to prioritize the masking of salient image regions via a novel masking algorithm and a novel masking block. Our approach enables controlling sample difficulty via the patch masking ratio, generating an effective easy-to-hard curriculum by gradually introducing harder samples as training progresses. CBM operates with two easily configurable parameters, i.e. the number of patches and the curriculum schedule, making it a versatile curriculum learning approach for object recognition and detection. We conduct experiments with various neural architectures, ranging from convolutional networks to vision transformers, on five benchmark data sets (CIFAR-10, CIFAR-100, ImageNet, Food-101 and PASCAL VOC), to compare CBM with conventional as well as curriculum-based training regimes. Our results reveal the superiority of our strategy compared with the state-of-the-art curriculum learning regimes. We also observe improvements in transfer learning contexts, where CBM surpasses previous work by considerable margins in terms of accuracy. We release our code for free non-commercial use at https://github.com/CroitoruAlin/CBM.
Curriculum Direct Preference Optimization for Diffusion and Consistency Models
May 22, 2024



Direct Preference Optimization (DPO) has been proposed as an effective and efficient alternative to reinforcement learning from human feedback (RLHF). In this paper, we propose a novel and enhanced version of DPO based on curriculum learning for text-to-image generation. Our method is divided into two training stages. First, a ranking of the examples generated for each prompt is obtained by employing a reward model. Then, increasingly difficult pairs of examples are sampled and provided to a text-to-image generative (diffusion or consistency) model. Generated samples that are far apart in the ranking are considered to form easy pairs, while those that are close in the ranking form hard pairs. In other words, we use the rank difference between samples as a measure of difficulty. The sampled pairs are split into batches according to their difficulty levels, which are gradually used to train the generative model. Our approach, Curriculum DPO, is compared against state-of-the-art fine-tuning approaches on three benchmarks, outperforming the competing methods in terms of text alignment, aesthetics and human preference. Our code is available at https://anonymous.4open.science/r/Curriculum-DPO-EE14.
Reverse Stable Diffusion: What prompt was used to generate this image?
Aug 02, 2023



Text-to-image diffusion models such as Stable Diffusion have recently attracted the interest of many researchers, and inverting the diffusion process can play an important role in better understanding the generative process and how to engineer prompts in order to obtain the desired images. To this end, we introduce the new task of predicting the text prompt given an image generated by a generative diffusion model. We combine a series of white-box and black-box models (with and without access to the weights of the diffusion network) to deal with the proposed task. We propose a novel learning framework comprising of a joint prompt regression and multi-label vocabulary classification objective that generates improved prompts. To further improve our method, we employ a curriculum learning procedure that promotes the learning of image-prompt pairs with lower labeling noise (i.e. that are better aligned), and an unsupervised domain-adaptive kernel learning method that uses the similarities between samples in the source and target domains as extra features. We conduct experiments on the DiffusionDB data set, predicting text prompts from images generated by Stable Diffusion. Our novel learning framework produces excellent results on the aforementioned task, yielding the highest gains when applied on the white-box model. In addition, we make an interesting discovery: training a diffusion model on the prompt generation task can make the model generate images that are much better aligned with the input prompts, when the model is directly reused for text-to-image generation.
Self-Distilled Masked Auto-Encoders are Efficient Video Anomaly Detectors
Jun 21, 2023



We propose an efficient abnormal event detection model based on a lightweight masked auto-encoder (AE) applied at the video frame level. The novelty of the proposed model is threefold. First, we introduce an approach to weight tokens based on motion gradients, thus avoiding learning to reconstruct the static background scene. Second, we integrate a teacher decoder and a student decoder into our architecture, leveraging the discrepancy between the outputs given by the two decoders to improve anomaly detection. Third, we generate synthetic abnormal events to augment the training videos, and task the masked AE model to jointly reconstruct the original frames (without anomalies) and the corresponding pixel-level anomaly maps. Our design leads to an efficient and effective model, as demonstrated by the extensive experiments carried out on three benchmarks: Avenue, ShanghaiTech and UCSD Ped2. The empirical results show that our model achieves an excellent trade-off between speed and accuracy, obtaining competitive AUC scores, while processing 1670 FPS. Hence, our model is between 8 and 70 times faster than competing methods. We also conduct an ablation study to justify our design.
Lightning Fast Video Anomaly Detection via Adversarial Knowledge Distillation
Nov 28, 2022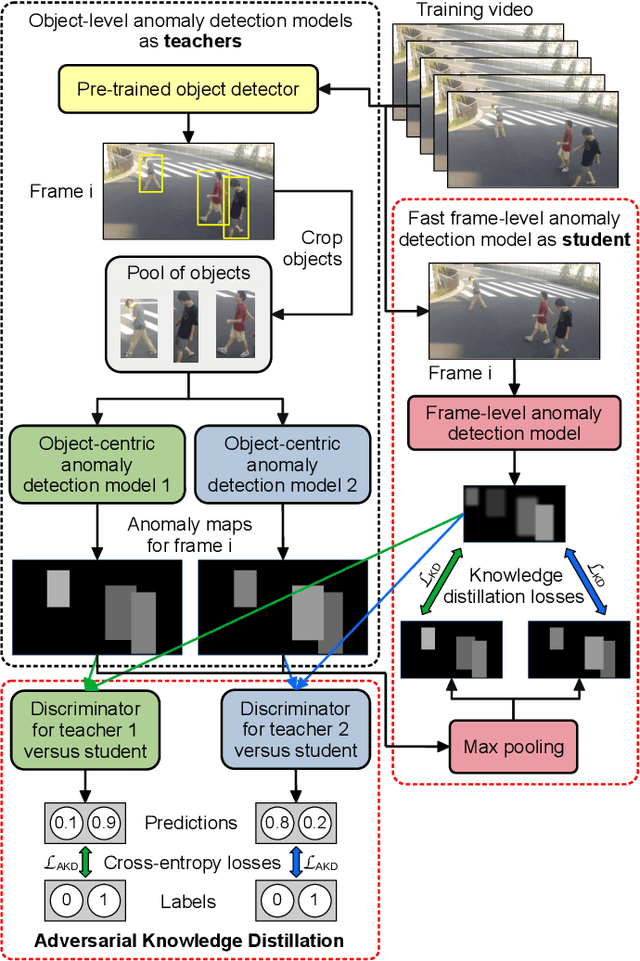
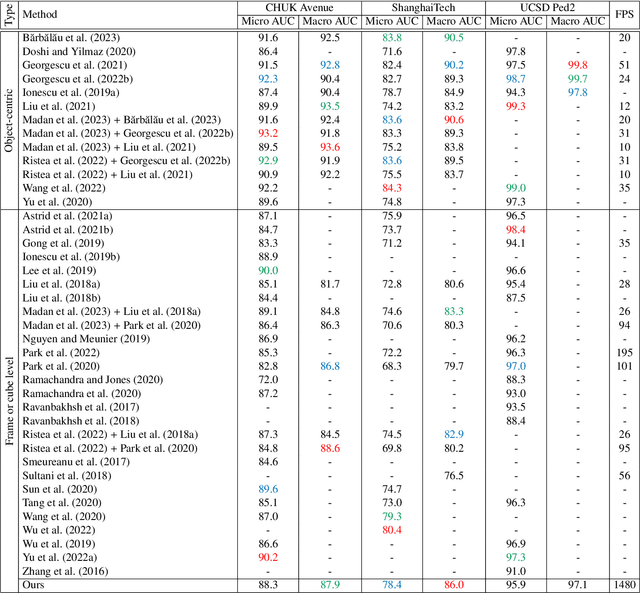
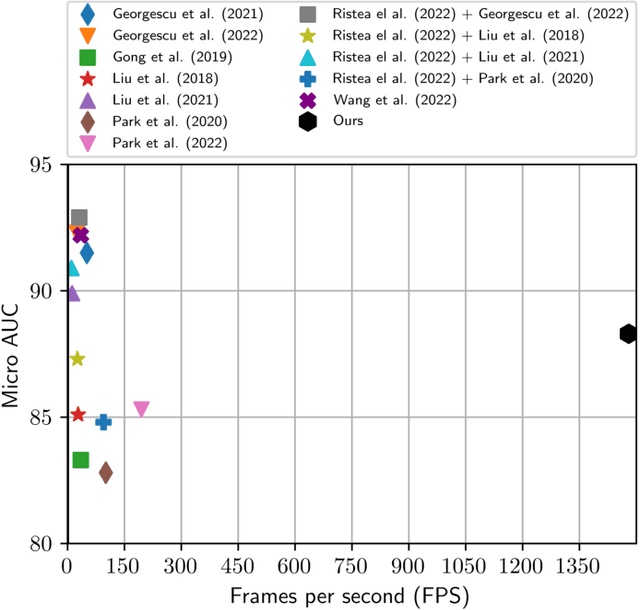
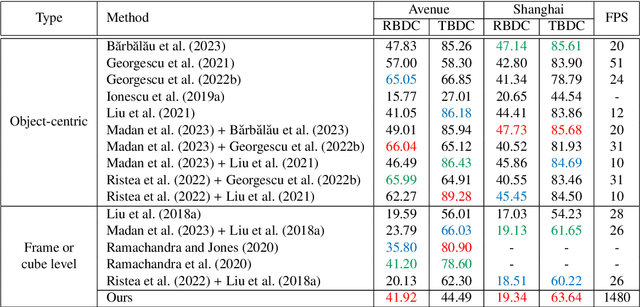
We propose a very fast frame-level model for anomaly detection in video, which learns to detect anomalies by distilling knowledge from multiple highly accurate object-level teacher models. To improve the fidelity of our student, we distill the low-resolution anomaly maps of the teachers by jointly applying standard and adversarial distillation, introducing an adversarial discriminator for each teacher to distinguish between target and generated anomaly maps. We conduct experiments on three benchmarks (Avenue, ShanghaiTech, UCSD Ped2), showing that our method is over 7 times faster than the fastest competing method, and between 28 and 62 times faster than object-centric models, while obtaining comparable results to recent methods. Our evaluation also indicates that our model achieves the best trade-off between speed and accuracy, due to its previously unheard-of speed of 1480 FPS. In addition, we carry out a comprehensive ablation study to justify our architectural design choices.
Diffusion Models in Vision: A Survey
Sep 10, 2022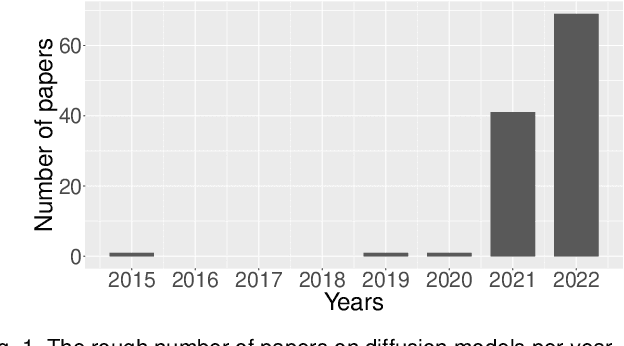
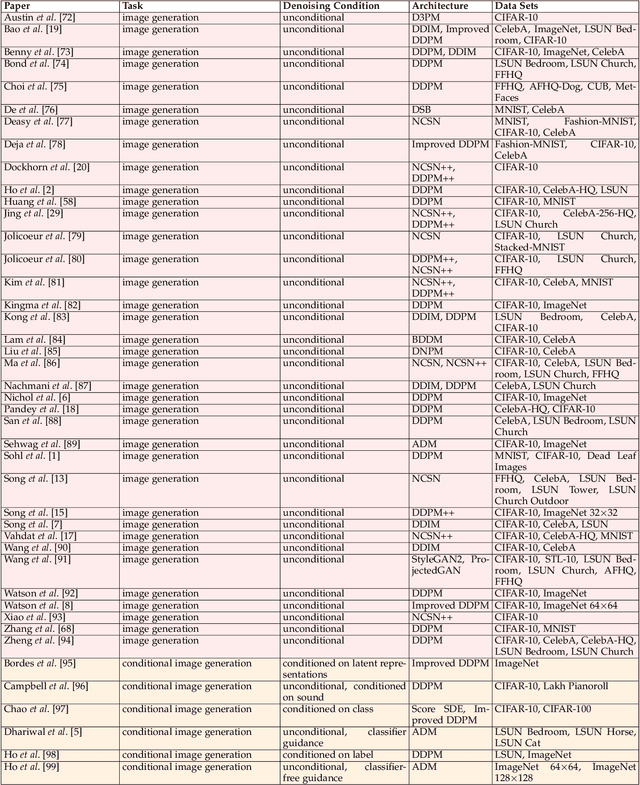

Denoising diffusion models represent a recent emerging topic in computer vision, demonstrating remarkable results in the area of generative modeling. A diffusion model is a deep generative model that is based on two stages, a forward diffusion stage and a reverse diffusion stage. In the forward diffusion stage, the input data is gradually perturbed over several steps by adding Gaussian noise. In the reverse stage, a model is tasked at recovering the original input data by learning to gradually reverse the diffusion process, step by step. Diffusion models are widely appreciated for the quality and diversity of the generated samples, despite their known computational burdens, i.e. low speeds due to the high number of steps involved during sampling. In this survey, we provide a comprehensive review of articles on denoising diffusion models applied in vision, comprising both theoretical and practical contributions in the field. First, we identify and present three generic diffusion modeling frameworks, which are based on denoising diffusion probabilistic models, noise conditioned score networks, and stochastic differential equations. We further discuss the relations between diffusion models and other deep generative models, including variational auto-encoders, generative adversarial networks, energy-based models, autoregressive models and normalizing flows. Then, we introduce a multi-perspective categorization of diffusion models applied in computer vision. Finally, we illustrate the current limitations of diffusion models and envision some interesting directions for future research.
LeRaC: Learning Rate Curriculum
May 18, 2022
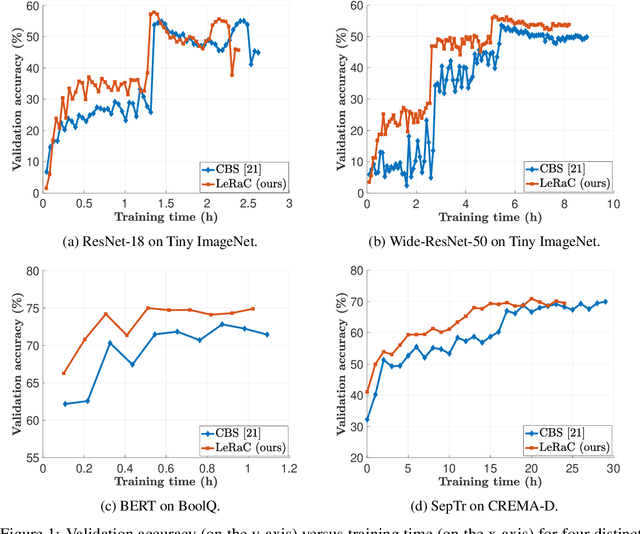
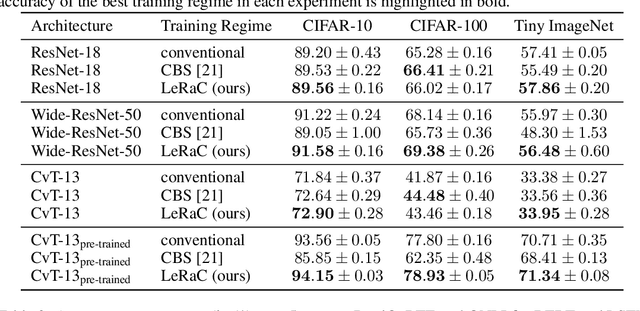
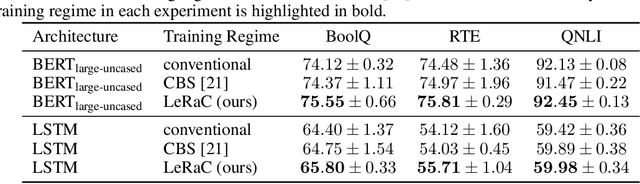
Most curriculum learning methods require an approach to sort the data samples by difficulty, which is often cumbersome to perform. In this work, we propose a novel curriculum learning approach termed Learning Rate Curriculum (LeRaC), which leverages the use of a different learning rate for each layer of a neural network to create a data-free curriculum during the initial training epochs. More specifically, LeRaC assigns higher learning rates to neural layers closer to the input, gradually decreasing the learning rates as the layers are placed farther away from the input. The learning rates increase at various paces during the first training iterations, until they all reach the same value. From this point on, the neural model is trained as usual. This creates a model-level curriculum learning strategy that does not require sorting the examples by difficulty and is compatible with any neural network, generating higher performance levels regardless of the architecture. We conduct comprehensive experiments on eight datasets from the computer vision (CIFAR-10, CIFAR-100, Tiny ImageNet), language (BoolQ, QNLI, RTE) and audio (ESC-50, CREMA-D) domains, considering various convolutional (ResNet-18, Wide-ResNet-50, DenseNet-121), recurrent (LSTM) and transformer (CvT, BERT, SepTr) architectures, comparing our approach with the conventional training regime. Moreover, we also compare with Curriculum by Smoothing (CBS), a state-of-the-art data-free curriculum learning approach. Unlike CBS, our performance improvements over the standard training regime are consistent across all datasets and models. Furthermore, we significantly surpass CBS in terms of training time (there is no additional cost over the standard training regime for LeRaC).