 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Coreference Resolution via Cycle-Consistent Machine Translation
Jun 03, 2026Coreference resolution is a core NLP task, having a broad range of downstream applications, e.g.~machine translation, question answering, document summarization, etc. While the task is well-studied in English, comparatively less attention is dedicated to coreference resolution in other languages, especially low-resource ones. To mitigate this gap, we propose a novel coreference resolution pipeline that harnesses machine translation (MT) from English to a target low-resource language, to generate or expand training data. To automatically validate the quality of the translated samples, we back-translate the samples and assess the similarity with the original English samples via cosine similarity in the latent space of a BERT model. The resulting similarity scores are integrated into the loss function to weight training samples according to their MT cycle consistency. Extensive experiments on four low-resource languages show that our pipeline brings significant performance gains in coreference resolution. Moreover, our pipeline enables accurate coreference resolution in languages where no previous corpora were available.
Real-time tightly coupled GNSS and IMU integration via Factor Graph Optimization
Mar 03, 2026Reliable positioning in dense urban environments remains challenging due to frequent GNSS signal blockage, multipath, and rapidly varying satellite geometry. While factor graph optimization (FGO)-based GNSS-IMU fusion has demonstrated strong robustness and accuracy, most formulations remain offline. In this work, we present a real-time tightly coupled GNSS-IMU FGO method that enables causal state estimation via incremental optimization with fixed-lag marginalization, and we evaluate its performance in a highly urbanized GNSS-degraded environment using the UrbanNav dataset.
Real-time loosely coupled GNSS and IMU integration via Factor Graph Optimization
Mar 03, 2026Accurate positioning, navigation, and timing (PNT) is fundamental to the operation of modern technologies and a key enabler of autonomous systems. A very important component of PNT is the Global Navigation Satellite System (GNSS) which ensures outdoor positioning. Modern research directions have pushed the performance of GNSS localization to new heights by fusing GNSS measurements with other sensory information, mainly measurements from Inertial Measurement Units (IMU). In this paper, we propose a loosely coupled architecture to integrate GNSS and IMU measurements using a Factor Graph Optimization (FGO) framework. Because the FGO method can be computationally challenging and often used as a post-processing method, our focus is on assessing its localization accuracy and service availability while operating in real-time in challenging environments (urban canyons). Experimental results on the UrbanNav-HK-MediumUrban-1 dataset show that the proposed approach achieves real-time operation and increased service availability compared to batch FGO methods. While this improvement comes at the cost of reduced positioning accuracy, the paper provides a detailed analysis of the trade-offs between accuracy, availability, and computational efficiency that characterize real-time FGO-based GNSS/IMU fusion.
MOSLD-Bench: Multilingual Open-Set Learning and Discovery Benchmark for Text Categorization
Jan 19, 2026Open-set learning and discovery (OSLD) is a challenging machine learning task in which samples from new (unknown) classes can appear at test time. It can be seen as a generalization of zero-shot learning, where the new classes are not known a priori, hence involving the active discovery of new classes. While zero-shot learning has been extensively studied in text classification, especially with the emergence of pre-trained language models, open-set learning and discovery is a comparatively new setup for the text domain. To this end, we introduce the first multilingual open-set learning and discovery (MOSLD) benchmark for text categorization by topic, comprising 960K data samples across 12 languages. To construct the benchmark, we (i) rearrange existing datasets and (ii) collect new data samples from the news domain. Moreover, we propose a novel framework for the OSLD task, which integrates multiple stages to continuously discover and learn new classes. We evaluate several language models, including our own, to obtain results that can be used as reference for future work. We release our benchmark at https://github.com/Adriana19Valentina/MOSLD-Bench.
A Survey of Text Classification Under Class Distribution Shift
Feb 18, 2025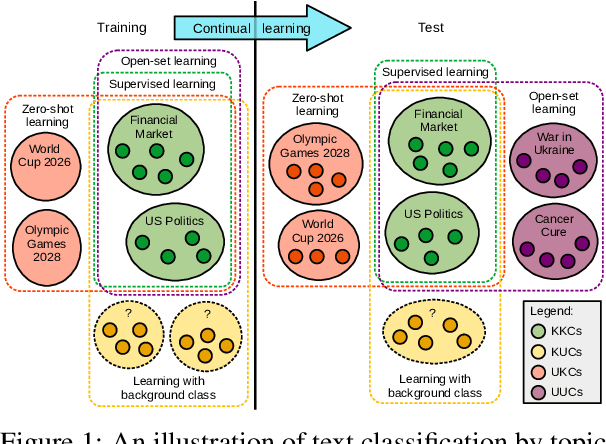

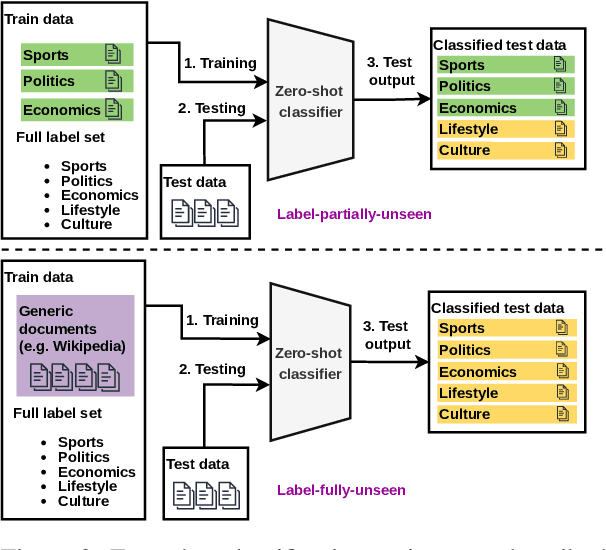
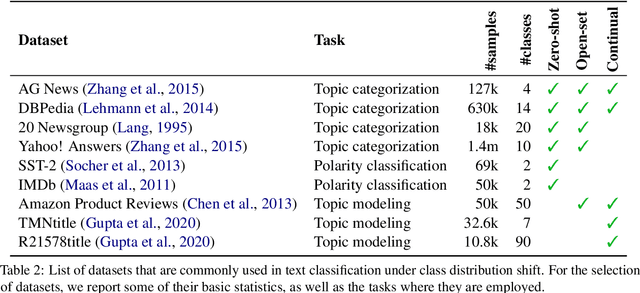
The basic underlying assumption of machine learning (ML) models is that the training and test data are sampled from the same distribution. However, in daily practice, this assumption is often broken, i.e.~the distribution of the test data changes over time, which hinders the application of conventional ML models. One domain where the distribution shift naturally occurs is text classification, since people always find new topics to discuss. To this end, we survey research articles studying open-set text classification and related tasks. We divide the methods in this area based on the constraints that define the kind of distribution shift and the corresponding problem formulation, i.e.~learning with the Universum, zero-shot learning, and open-set learning. We next discuss the predominant mitigation approaches for each problem setup. Finally, we identify several future work directions, aiming to push the boundaries beyond the state of the art. Interestingly, we find that continual learning can solve many of the issues caused by the shifting class distribution. We maintain a list of relevant papers at https://github.com/Eduard6421/Open-Set-Survey.
Dual Unscented Kalman Filter Architecture for Sensor Fusion in Water Networks Leak Localization
Dec 16, 2024



Leakage in water systems results in significant daily water losses, degrading service quality, increasing costs, and aggravating environmental problems. Most leak localization methods rely solely on pressure data, missing valuable information from other sensor types. This article proposes a hydraulic state estimation methodology based on a dual Unscented Kalman Filter (UKF) approach, which enhances the estimation of both nodal hydraulic heads, critical in localization tasks, and pipe flows, useful for operational purposes. The approach enables the fusion of different sensor types, such as pressure, flow and demand meters. The strategy is evaluated in well-known open source case studies, namely Modena and L-TOWN, showing improvements over other state-of-the-art estimation approaches in terms of interpolation accuracy, as well as more precise leak localization performance in L-TOWN.
Deepfake Media Generation and Detection in the Generative AI Era: A Survey and Outlook
Nov 29, 2024



With the recent advancements in generative modeling, the realism of deepfake content has been increasing at a steady pace, even reaching the point where people often fail to detect manipulated media content online, thus being deceived into various kinds of scams. In this paper, we survey deepfake generation and detection techniques, including the most recent developments in the field, such as diffusion models and Neural Radiance Fields. Our literature review covers all deepfake media types, comprising image, video, audio and multimodal (audio-visual) content. We identify various kinds of deepfakes, according to the procedure used to alter or generate the fake content. We further construct a taxonomy of deepfake generation and detection methods, illustrating the important groups of methods and the domains where these methods are applied. Next, we gather datasets used for deepfake detection and provide updated rankings of the best performing deepfake detectors on the most popular datasets. In addition, we develop a novel multimodal benchmark to evaluate deepfake detectors on out-of-distribution content. The results indicate that state-of-the-art detectors fail to generalize to deepfake content generated by unseen deepfake generators. Finally, we propose future directions to obtain robust and powerful deepfake detectors. Our project page and new benchmark are available at https://github.com/CroitoruAlin/biodeep.
Fusing Dictionary Learning and Support Vector Machines for Unsupervised Anomaly Detection
Apr 05, 2024



We study in this paper the improvement of one-class support vector machines (OC-SVM) through sparse representation techniques for unsupervised anomaly detection. As Dictionary Learning (DL) became recently a common analysis technique that reveals hidden sparse patterns of data, our approach uses this insight to endow unsupervised detection with more control on pattern finding and dimensions. We introduce a new anomaly detection model that unifies the OC-SVM and DL residual functions into a single composite objective, subsequently solved through K-SVD-type iterative algorithms. A closed-form of the alternating K-SVD iteration is explicitly derived for the new composite model and practical implementable schemes are discussed. The standard DL model is adapted for the Dictionary Pair Learning (DPL) context, where the usual sparsity constraints are naturally eliminated. Finally, we extend both objectives to the more general setting that allows the use of kernel functions. The empirical convergence properties of the resulting algorithms are provided and an in-depth analysis of their parametrization is performed while also demonstrating their numerical performance in comparison with existing methods.
Learning Explicitly Conditioned Sparsifying Transforms
Mar 05, 2024


Sparsifying transforms became in the last decades widely known tools for finding structured sparse representations of signals in certain transform domains. Despite the popularity of classical transforms such as DCT and Wavelet, learning optimal transforms that guarantee good representations of data into the sparse domain has been recently analyzed in a series of papers. Typically, the conditioning number and representation ability are complementary key features of learning square transforms that may not be explicitly controlled in a given optimization model. Unlike the existing approaches from the literature, in our paper, we consider a new sparsifying transform model that enforces explicit control over the data representation quality and the condition number of the learned transforms. We confirm through numerical experiments that our model presents better numerical behavior than the state-of-the-art.
Nodal Hydraulic Head Estimation through Unscented Kalman Filter for Data-driven Leak Localization in Water Networks
Nov 27, 2023In this paper, we present a nodal hydraulic head estimation methodology for water distribution networks (WDN) based on an Unscented Kalman Filter (UKF) scheme with application to leak localization. The UKF refines an initial estimation of the hydraulic state by considering the prediction model, as well as available pressure and demand measurements. To this end, it provides customized prediction and data assimilation steps. Additionally, the method is enhanced by dynamically updating the prediction function weight matrices. Performance testing on the Modena benchmark under realistic conditions demonstrates the method's effectiveness in enhancing state estimation and data-driven leak localization.